게으름에 대한 인턴십: 비최적화된 함수의 게으른 언링크
약 3개월 전에 저는 V8 팀 (구글 뮌헨)에서 인턴으로 합류했으며, 그 이후로 VM의 _Deoptimizer_라는 완전히 새로운 프로젝트에 대해 작업하고 있습니다. 이는 매우 흥미롭고 도전적인 프로젝트임을 입증했습니다. 제 인턴십 첫 번째 부분은 VM의 보안성을 개선하는 데 초점을 맞췄습니다. 두 번째 부분은 성능 개선에 중점을 두었습니다. 즉, 이전에 비최적화된 함수를 언링크할 때 사용된 데이터 구조를 제거하는 작업을 수행했으며, 이는 쓰레기 수집 중 성능 병목현상을 일으킨 문제였습니다. 이 블로그 게시물은 제 인턴십의 두 번째 부분에 대해 설명하며, V8이 비최적화된 함수들을 어떻게 언링크했는지, 이를 어떻게 변경했는지, 그리고 얻은 성능 향상에 대해 설명합니다.
JavaScript 함수에 대한 V8 파이프라인을 간단히 되짚어보겠습니다: V8의 인터프리터, Ignition은 해당 함수에 대한 프로파일링 정보를 수집하며 이를 해석합니다. 함수가 활성화되면 이 정보는 V8의 컴파일러, TurboFan에 전달되어 최적화된 기계 코드로 변환됩니다. 프로파일링 정보가 더 이상 유효하지 않을 때 — 예를 들어 프로파일된 객체 중 하나가 런타임 동안 다른 유형을 얻었을 때 — 최적화된 기계 코드는 무효화될 수 있습니다. 그러한 경우 V8은 이를 비최적화해야 합니다.
최적화 시 TurboFan은 해당 함수에 대해 코드 객체, 즉 최적화된 기계 코드, 를 생성합니다. 해당 함수가 다음 번 호출될 때 V8은 해당 함수의 최적화된 코드 링크를 따라 이를 실행합니다. 이 함수가 비최적화될 경우, 다시 실행되지 않도록 코드 객체를 언링크해야 합니다. 이는 어떻게 이루어질까요?
예를 들어, 다음 코드에서 함수 f1은 여러 번 호출됩니다(항상 정수를 인수로 전달). TurboFan은 그 특정 경우에 대한 기계 코드를 생성합니다.
function g() {
return (i) => i;
}
// 클로저 생성
const f1 = g();
// f1 최적화
for (var i = 0; i < 1000; i++) f1(0);
각 함수는 인터프리터로의 트램폴린도 가지며 — 자세한 내용은 이 슬라이드에서 확인할 수 있습니다 — 이를 SharedFunctionInfo (SFI)에서 유지합니다. 이 트램폴린은 V8이 최적화되지 않은 코드로 돌아가야 할 때 사용됩니다. 따라서 예를 들어 다른 유형의 인수를 전달하여 비최적화가 발생할 경우, Deoptimizer는 JavaScript 함수의 코드 필드를 이 트램폴린으로 설정할 수 있습니다.
이것이 간단해보일 수 있지만 V8은 최적화된 JavaScript 함수의 약한 리스트를 유지해야 합니다. 이는 동일한 최적화된 코드 객체를 가리키는 서로 다른 함수들이 존재할 수 있기 때문입니다. 예제를 다음과 같이 확장하면, 함수 f1 및 f2가 동일한 최적화된 코드를 함께 가리키게 됩니다.
const f2 = g();
f2(0);
함수 f1이 비최적화될 경우(예를 들어 다른 유형의 객체 {x: 0}로 호출하여) f2를 호출함으로써 무효화된 코드가 다시 실행되도록 해서는 안 됩니다.
따라서 비최적화 시 V8은 모든 최적화된 JavaScript 함수를 반복 검토하고, 비최적화된 코드 객체를 가리키는 함수들을 언링크했습니다. 많은 최적화된 JavaScript 함수가 있는 애플리케이션에서는 이 반복 작업이 성능 병목현상이 되었습니다. 또한, 디옵티마이제이션 속도를 늦출 뿐만 아니라 V8은 멈춤-세계 형식의 쓰레기 수집 사이클에서도 이러한 리스트들을 반복 확인했으며, 상황이 더욱 악화되었습니다.
V8의 성능에 대해 이러한 데이터 구조의 영향을 파악하기 위해 많은 JavaScript 함수 생성 후 많은 생존 순환을 유발하는 마이크로 벤치마크를 작성했습니다.
function g() {
return (i) => i + 1;
}
// 초기 클로저 생성 및 최적화
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// 2M개의 클로저를 생성한다. 이러한 클로저는 이전에 최적화된 코드를 얻는다.
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// 이제 가비지 컬렉션을 유발한다. 모든 작업이 느리게 수행된다.
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
이 벤치마크를 실행할 때 V8이 실행 시간의 약 98%를 가비지 컬렉션에 소비하는 것을 관찰할 수 있었다. 우리는 이 데이터 구조를 제거하고, 대신 지연 링크 해제 방식을 사용했으며, x64에서 다음을 관찰했다:

비록 많은 자바스크립트 함수들을 생성하고 많은 가비지 컬렉션 사이클을 유발시킨 간단한 마이크로 벤치마크에 불과하지만, 이 데이터 구조가 초래한 오버헤드에 대한 개념을 제공한다. 우리가 이 작업에 동기를 부여받았던 실제 애플리케이션은 Node.js에서 구현된 router 벤치마크와 ARES-6 벤치마크 스위트이었다.
지연 링크 해제
최적화된 코드를 자바스크립트 함수에서 역최적화할 때 바로 제거하는 대신, V8은 해당 함수가 다음 호출되었을 때까지 이를 연기한다. 이러한 함수가 호출되면 V8은 해당 함수가 역최적화되었는지 확인하고 최적화된 코드를 제거한 다음 지연 컴파일을 계속 진행한다. 이 함수가 다시 호출되지 않는 경우, 이러한 역최적화된 코드 객체는 제거되지 않고 수집되지 않는다. 하지만 역최적화가 진행되는 동안 코드 객체의 내장 필드를 모두 무효화하므로, 해당 코드 객체 자체는 계속 존재한다.
최적화된 자바스크립트 함수 목록을 제거했던 커밋은 VM의 여러 부분에서 변경을 필요로 했지만, 기본 아이디어는 다음과 같다. 최적화된 코드 객체를 조립할 때, 해당 코드 객체가 자바스크립트 함수의 코드인지 확인한다. 그렇다면, 해당 함수의 프로로그에 코드 객체가 역최적화되었는지 확인하고 탈출하는 머신 코드를 작성한다. 역최적화하면 역최적화된 코드는 수정되지 않는다 — 코드 패칭은 사라진다. 따라서 해당 함수가 다시 호출될 때 bit marked_for_deoptimization은 여전히 설정되어 있다. TurboFan은 이를 확인하는 코드를 생성하며, 설정된 경우 V8은 새로운 builtin CompileLazyDeoptimizedCode로 점프하여 역최적화된 코드를 자바스크립트 함수에서 제거한 다음 지연 컴파일을 계속 진행한다.
좀 더 자세히 보면, 첫 번째 단계는 현재 조립 중인 코드의 주소를 로드하는 지시어를 생성하는 것이다. x64에서는 다음 코드로 이를 수행할 수 있다:
Label current;
// 현재 명령어의 유효 주소를 rcx에 로드한다.
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
그 후에는 코드 객체에서 marked_for_deoptimization 비트가 위치한 곳을 알아내야 한다.
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
그런 다음 해당 비트를 테스트하며 설정된 경우 CompileLazyDeoptimizedCode로 점프한다.
// 비트가 설정되어 있는지 테스트, 즉 코드가 역최적화로 표시된 경우.
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// 설정된 경우 builtin 코드로 점프.
__ j(not_zero, /* handle to builtin code here */, RelocInfo::CODE_TARGET);
이 CompileLazyDeoptimizedCode 내에서 남은 작업은 자바스크립트 함수의 코드 필드를 링크 해제하고 이를 Interpreter 엔트리로의 트램펄린으로 설정하는 것이다. 자바스크립트 함수의 주소가 레지스터 rdi에 있다고 가정하면, 다음과 같이 SharedFunctionInfo의 포인터를 얻을 수 있다:
// SharedFunctionInfo를 얻기 위한 필드 읽기.
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
... 그리고 유사하게 트램펄린을 다음과 같이 얻을 수 있다:
// 코드 객체를 얻기 위한 필드 읽기.
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
그런 다음 이를 사용하여 코드 포인터를 함수 슬롯에 업데이트할 수 있다:
// 트램펄린으로 함수의 코드 필드를 업데이트.
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// 필드를 보호하기 위한 쓰기 배리어.
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
이 작업은 이전과 동일한 결과를 생성한다. 하지만 역최적화 도구에서 링크 해제를 처리하는 대신, 코드 생성 중에 이를 걱정해야 한다. 따라서 직접 작성된 어셈블리를 사용한다.
위는 x64 아키텍처에서의 동작 방식입니다. 우리는 ia32, arm, arm64, mips, mips64에도 이를 구현했습니다.
이 새로운 기술은 이미 V8에 통합되어 있으며, 나중에 논의할 성능 향상을 가능하게 합니다. 그러나 다음과 같은 약간의 단점이 있습니다: 이전에는 V8이 최적화 해제 시에만 연결 해제를 고려했지만 이제 모든 최적화된 함수의 활성화 시 연결 해제를 수행해야 합니다. 또한 marked_for_deoptimization 비트를 확인하는 접근법은 코드 객체의 주소를 얻기 위해 약간의 작업을 해야 하기 때문에 최고 효율적이지는 않습니다. 이는 최적화된 함수를 실행할 때마다 발생합니다. 이런 문제에 대한 가능한 해결책은 코드 객체에 자신의 포인터를 유지하는 것입니다. 함수가 호출될 때마다 코드 객체의 주소를 찾기 위한 작업을 수행하는 대신, V8이 객체를 생성한 후 단 한 번만 수행하도록 하는 것입니다.
결과
이제 이 프로젝트로 얻어진 성능 향상 및 회귀에 대해 살펴봅니다.
x64에서의 일반적인 개선
다음 그래프는 이전 커밋에 비해 일부 개선 사항과 회귀를 보여줍니다. 높을수록 더 좋음을 나타냅니다.
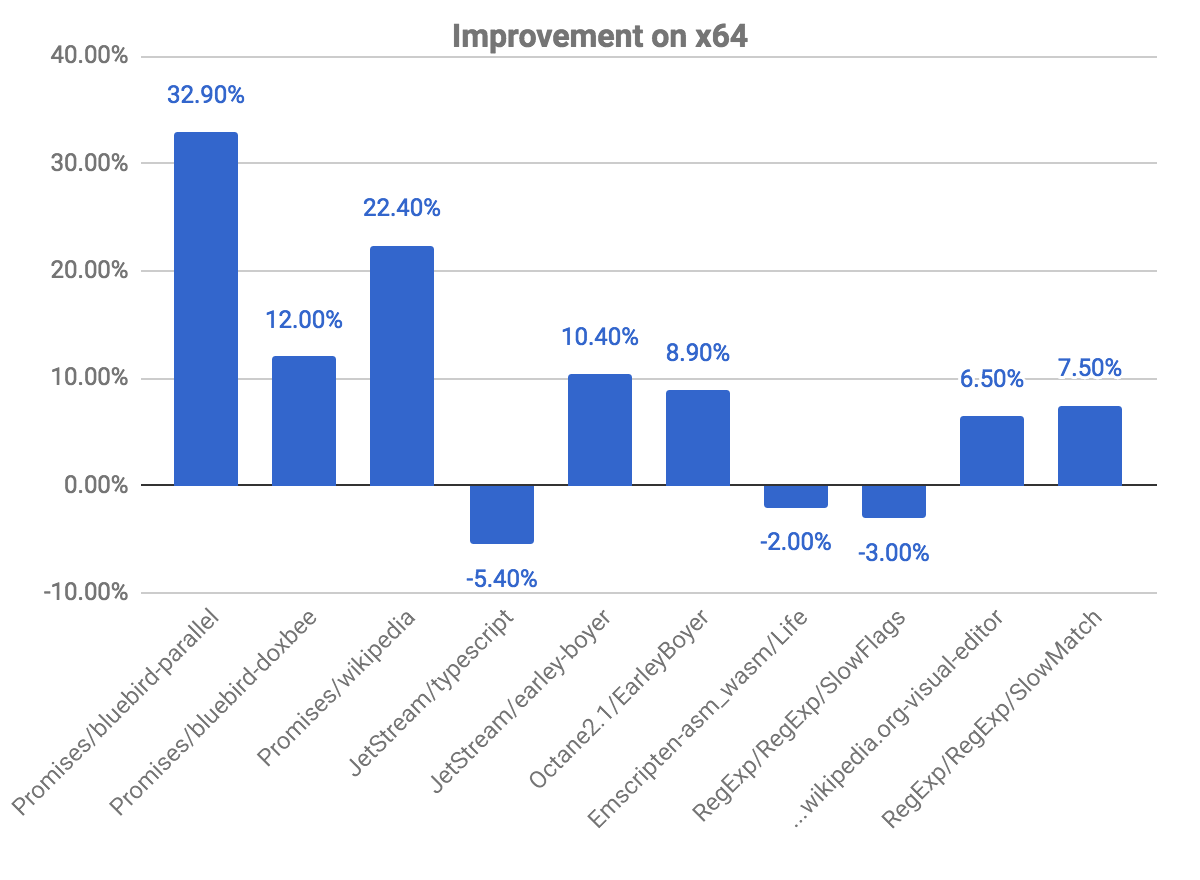
promises 벤치마크는 bluebird-parallel 벤치마크에서 거의 33%의 향상을, wikipedia에서 22.40%의 향상을 보여주며 가장 큰 개선을 보입니다. 몇몇 벤치마크에서 약간의 회귀를 관찰했습니다. 이는 위에서 설명한 최적화 해제 여부를 확인하는 문제와 관련이 있습니다.
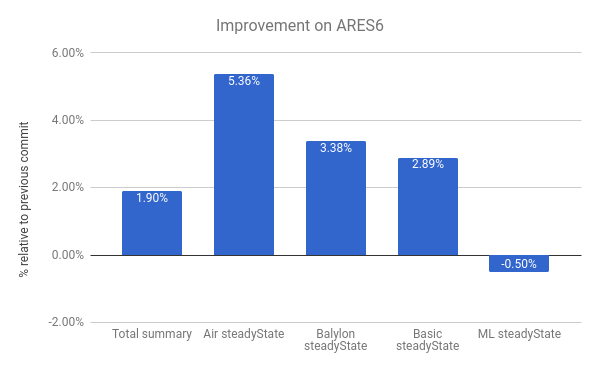
ARES-6 벤치마크 스위트에서도 개선 사항을 볼 수 있습니다. 이 그래프에서도 높을수록 더 좋습니다. 이러한 프로그램들은 원래 GC 관련 활동에 상당한 시간을 소비하곤 했습니다. 느린 연결 해제를 통해 전체적으로 1.9%의 성능 향상을 이루었습니다. 가장 두드러진 사례는 Air steadyState로, 약 5.36%의 개선을 얻었습니다.
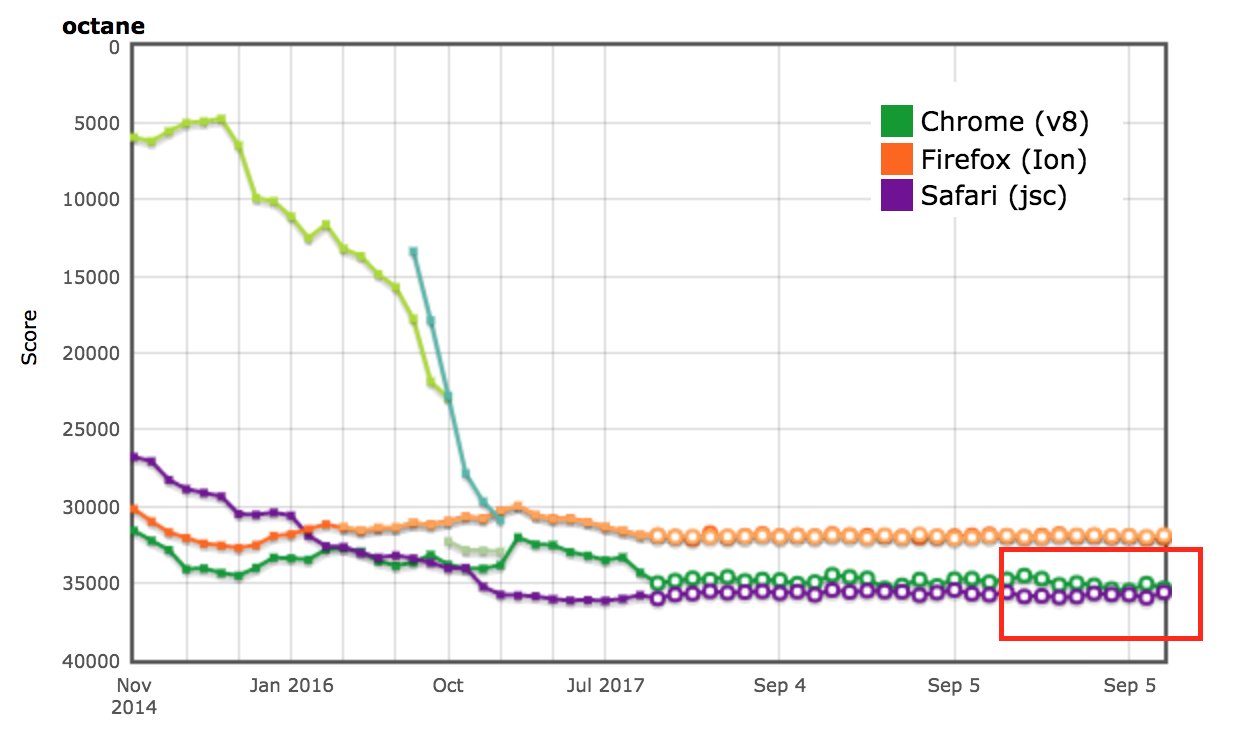
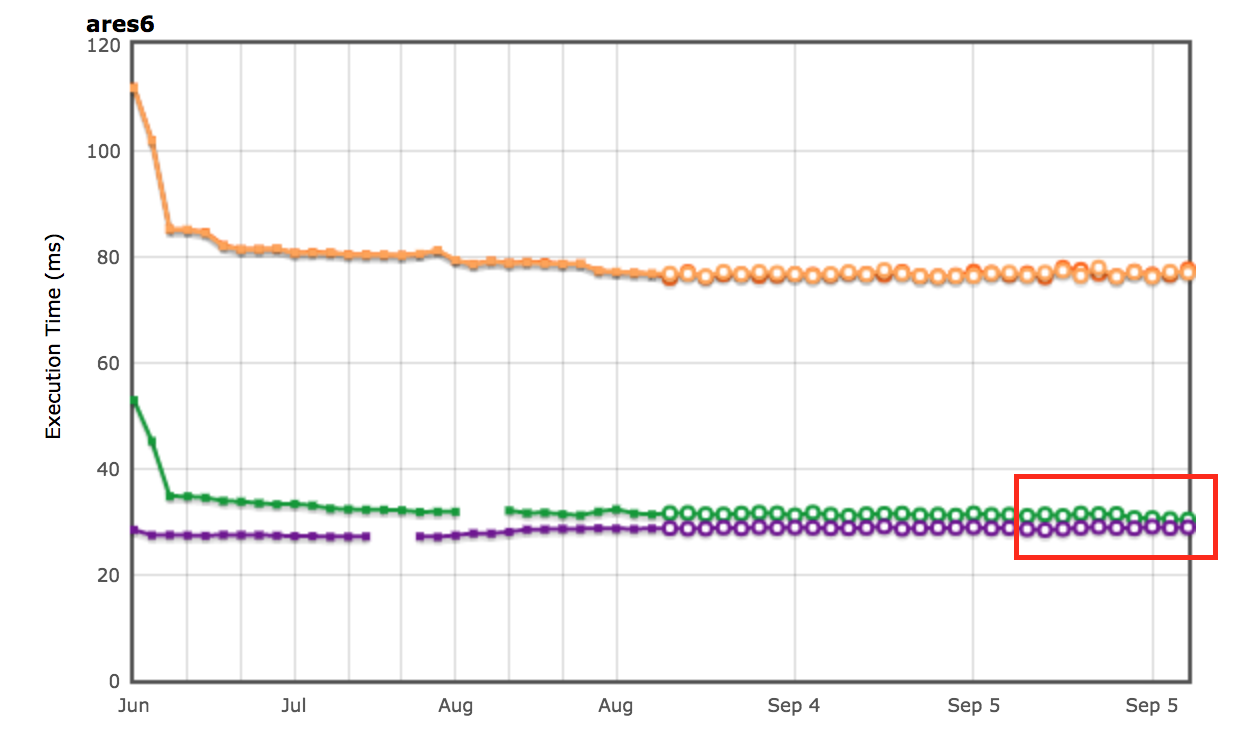
AreWeFastYet 결과
Octane 및 ARES-6 벤치마크 스위트의 성능 결과는 AreWeFastYet 트래커에서도 나타났습니다. 2017년 9월 5일에 제공된 기본 머신(macOS 10.10 64비트, Mac Pro, shell)을 사용하여 이러한 성능 결과를 조사했습니다.
Node.js에 미치는 영향
router-benchmark에서도 성능 향상을 확인할 수 있습니다. 다음 두 그래프는 테스트된 각 라우터가 초당 처리하는 작업 수를 보여줍니다. 즉, 높을수록 더 좋습니다. 이 벤치마크 스위트를 사용하여 두 가지 유형의 실험을 수행했습니다. 첫 번째로, 각 테스트를 독립적으로 실행하여 나머지 테스트와 무관하게 성능 향상을 확인했습니다. 두 번째로, VM을 변경하지 않고 모든 테스트를 한꺼번에 실행하여 각 테스트가 다른 기능들과 통합된 환경을 시뮬레이션했습니다.
첫 번째 실험에서 router와 express 테스트는 이전에 비해 동일한 시간 동안 약 두 배 이상의 작업을 수행했습니다. 두 번째 실험에서는 더욱 큰 향상을 확인할 수 있었습니다. 일부 경우 (routr, server-router, router 등)에서는 각각 약 3.80배, 3배 및 2배 더 많은 작업을 수행했습니다. 이는 V8이 테스트마다 더 많은 최적화된 자바스크립트 함수를 축적하기 때문입니다. 따라서 특정 테스트를 실행할 때 가비지 수집 주기가 발생하면 V8은 현재 테스트와 이전 테스트에서 최적화된 함수를 방문해야 합니다.


추가 최적화
이제 V8이 컨텍스트에서 자바스크립트 함수들의 연결 리스트를 유지하지 않으므로 JSFunction 클래스에서 next 필드를 제거할 수 있습니다. 비록 간단한 수정이지만, 함수당 포인터 크기를 절약하여 여러 웹 페이지에서 의미 있는 절약을 제공합니다:
| 벤치마크 | 종류 | 메모리 절약 (절대값) | 메모리 절약 (상대값) |
|---|---|---|---|
| facebook.com | 평균 효율 크기 | 170 KB | 3.70% |
| twitter.com | 할당된 객체의 평균 크기 | 284 KB | 1.20% |
| cnn.com | 할당된 객체의 평균 크기 | 788 KB | 1.53% |
| youtube.com | 할당된 객체의 평균 크기 | 129 KB | 0.79% |
감사의 말
인턴 기간 동안 항상 제 많은 질문에 답변해주신 여러 사람들의 많은 도움을 받았습니다. 이에 대해 다음 분들께 감사드리고 싶습니다: 컴파일러와 디옵티마이저 작동 방식에 대한 논의를 도와주신 Benedikt Meurer, Jaroslav Sevcik, Michael Starzinger 님, 제가 쓰레기 수집기를 망가뜨릴 때마다 도와주신 Ulan Degenbaev 님, 그리고 이 글을 교정해주신 Mathias Bynens, Peter Marshall, Camillo Bruni, Maya Armyanova 님께 감사드립니다.
마지막으로, 이 글은 제가 Google 인턴으로서 기여하는 마지막 글이며, V8 팀의 모든 분들, 특히 제 호스트 Benedikt Meurer 님께 감사드리고 싶습니다. 저를 호스팅해주시고 흥미로운 프로젝트에 참여할 기회를 주셔서 감사드리며, Google에서 많은 것을 배우고 즐거운 시간을 보냈습니다!