Um estágio sobre preguiça: desvinculação preguiçosa de funções desotimizadas
Há cerca de três meses, me juntei à equipe V8 (Google Munique) como estagiária e, desde então, tenho trabalhado no Desotimizador da máquina virtual — algo completamente novo para mim, que se revelou um projeto interessante e desafiador. A primeira parte do meu estágio focou em melhorar a segurança da máquina virtual. A segunda parte focou em melhorias de desempenho, especificamente na remoção de uma estrutura de dados usada para desvincular funções previamente desotimizadas, que era um gargalo de desempenho durante a coleta de lixo. Este post descreve essa segunda parte do meu estágio. Vou explicar como o V8 costumava desvincular funções desotimizadas, como mudamos isso e quais foram as melhorias de desempenho obtidas.
Vamos recapitular brevemente o pipeline do V8 para uma função JavaScript: o interpretador do V8, Ignition, coleta informações de perfil sobre essa função enquanto a interpreta. Quando a função se torna quente, essas informações são passadas para o compilador do V8, TurboFan, que gera código de máquina otimizado. Quando as informações de perfil deixam de ser válidas — por exemplo, porque um dos objetos analisados obtém um tipo diferente durante a execução — o código de máquina otimizado pode se tornar inválido. Nesse caso, o V8 precisa desotimizá-lo.
Durante a otimização, o TurboFan gera um objeto de código, ou seja, o código de máquina otimizado, para a função sob otimização. Quando essa função é invocada na próxima vez, o V8 segue o link para o código otimizado dessa função e o executa. Após a desotimização dessa função, precisamos desvincular o objeto de código para garantir que ele não seja executado novamente. Como isso acontece?
Por exemplo, no código a seguir, a função f1 será invocada muitas vezes (sempre passando um inteiro como argumento). O TurboFan então gera código de máquina para esse caso específico.
function g() {
return (i) => i;
}
// Cria um fechamento.
const f1 = g();
// Otimiza f1.
for (var i = 0; i < 1000; i++) f1(0);
Cada função também tem um trampolim para o interpretador — mais detalhes nestes slides — e manterá um ponteiro para esse trampolim em seu SharedFunctionInfo (SFI). Este trampolim será usado sempre que o V8 precisar voltar para o código não otimizado. Assim, durante a desotimização, desencadeada ao passar um argumento de tipo diferente, por exemplo, o Desotimizador pode simplesmente definir o campo de código da função JavaScript para este trampolim.
Embora isso pareça simples, força o V8 a manter listas fracas de funções JavaScript otimizadas. Isso ocorre porque pode haver diferentes funções apontando para o mesmo objeto de código otimizado. Podemos estender nosso exemplo da seguinte maneira, e as funções f1 e f2 apontam para o mesmo código otimizado.
const f2 = g();
f2(0);
Se a função f1 for desotimizada (por exemplo, ao invocá-la com um objeto de tipo diferente {x: 0}) precisamos garantir que o código invalidado não será executado novamente ao invocar f2.
Assim, durante a desotimização, o V8 costumava iterar sobre todas as funções JavaScript otimizadas e desconectava aquelas que apontavam para o objeto de código que estava sendo desotimizado. Essa iteração em aplicações com muitas funções JavaScript otimizadas tornou-se um gargalo de desempenho. Além disso, além de desacelerar a desotimização, o V8 costumava iterar sobre essas listas durante os ciclos de coleta de lixo em stop-the-world, tornando isso ainda pior.
Para ter uma ideia do impacto de tal estrutura de dados no desempenho do V8, escrevemos um micro-benchmark que estressa seu uso, desencadeando muitos ciclos de coleta após criar várias funções JavaScript.
function g() {
return (i) => i + 1;
}
// Cria um fechamento inicial e otimiza.
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// Crie 2M de closures; essas receberão o código previamente otimizado.
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// Agora, cause coletas; todas elas serão lentas.
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
Ao executar este benchmark, observamos que o V8 gastou cerca de 98% de seu tempo de execução em coleta de lixo. Em seguida, removemos esta estrutura de dados e, em vez disso, usamos uma abordagem para lazy unlinking, e isto foi o que observamos no x64:

Embora este seja apenas um micro-benchmark que cria muitas funções JavaScript e dispara muitos ciclos de coleta de lixo, ele nos dá uma ideia da sobrecarga introduzida por essa estrutura de dados. Outros aplicativos mais realistas onde vimos alguma sobrecarga, e que motivaram este trabalho, foram o router benchmark implementado em Node.js e o ARES-6 benchmark suite.
Lazy unlinking
Em vez de desvincular o código otimizado das funções JavaScript ao sofrer desotimização, o V8 adia isso para a próxima invocação de tais funções. Quando tais funções são invocadas, o V8 verifica se elas foram desotimizadas, desvincula-as e, em seguida, continua com a compilação lazy. Se essas funções nunca forem invocadas novamente, então elas nunca serão desvinculadas e os objetos de código desotimizados não serão coletados. Porém, dado que durante a desotimização invalidamos todos os campos incorporados do objeto de código, apenas mantemos aquele objeto de código ativo.
O commit que removeu esta lista de funções JavaScript otimizadas exigiu alterações em várias partes da VM, mas a ideia básica é a seguinte. Ao montar o objeto de código otimizado, verificamos se este é o código de uma função JavaScript. Se for, no prólogo, montamos o código de máquina para fazer rollback se o objeto de código tiver sido desotimizado. Durante a desotimização não modificamos o código desotimizado — a modificação do código foi eliminada. Assim, o bit marked_for_deoptimization permanece configurado ao invocar a função novamente. TurboFan gera código para verificá-lo, e se estiver configurado, então o V8 salta para um novo builtin, CompileLazyDeoptimizedCode, que desvincula o código desotimizado da função JavaScript e, em seguida, continua com a compilação lazy.
Com mais detalhes, o primeiro passo é gerar instruções que carreguem o endereço do código sendo atualmente montado. Podemos fazer isso no x64, com o seguinte código:
Label current;
// Carrega o endereço efetivo da instrução atual em rcx.
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
Depois disso, precisamos obter onde no objeto de código o bit marked_for_deoptimization vive.
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
Podemos então testar o bit e, se configurado, saltar para o builtin CompileLazyDeoptimizedCode.
// Testa se o bit está configurado, ou seja, se o código está marcado para desotimização.
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// Salta para o builtin se estiver.
__ j(not_zero, /* handle para o código builtin aqui */, RelocInfo::CODE_TARGET);
Do lado deste builtin CompileLazyDeoptimizedCode, tudo o que resta é desvincular o campo de código da função JavaScript e configurá-lo como o trampoline para a entrada do Interpreter. Assim, considerando que o endereço da função JavaScript está no registrador rdi, podemos obter o ponteiro para o SharedFunctionInfo com:
// Leitura de campo para obter o SharedFunctionInfo.
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
...e, de forma semelhante, o trampoline com:
// Leitura de campo para obter o objeto de código.
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
Então, podemos usá-lo para atualizar o slot da função para o ponteiro do código:
// Atualiza o campo de código da função com o trampoline.
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// Barreira de gravação para proteger o campo.
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
Isso produz o mesmo resultado de antes. No entanto, em vez de cuidar de desvincular no Deoptimizer, precisamos nos preocupar com isso durante a geração do código. Daí o assembly escrito à mão.
O acima é como funciona na arquitetura x64. Nós implementamos isso para ia32, arm, arm64, mips e mips64.
Esta nova técnica já está integrada ao V8 e, como discutiremos mais tarde, permite melhorias de desempenho. No entanto, vem com uma pequena desvantagem: Antes, o V8 considerava desvincular apenas na desotimização. Agora, precisa fazer isso na ativação de todas as funções otimizadas. Além disso, a abordagem para verificar o bit marked_for_deoptimization não é tão eficiente quanto poderia ser, dado que precisamos realizar algum trabalho para obter o endereço do objeto de código. Note que isso ocorre ao entrar em cada função otimizada. Uma solução possível para este problema é manter em um objeto de código um ponteiro para si mesmo. Em vez de buscar o endereço do objeto de código toda vez que a função é invocada, o V8 faria isso uma única vez, após sua construção.
Resultados
Agora analisamos os ganhos e regressões de desempenho obtidos com este projeto.
Melhorias gerais no x64
O gráfico a seguir nos mostra algumas melhorias e regressões, em relação ao commit anterior. Observe que quanto mais alto, melhor.
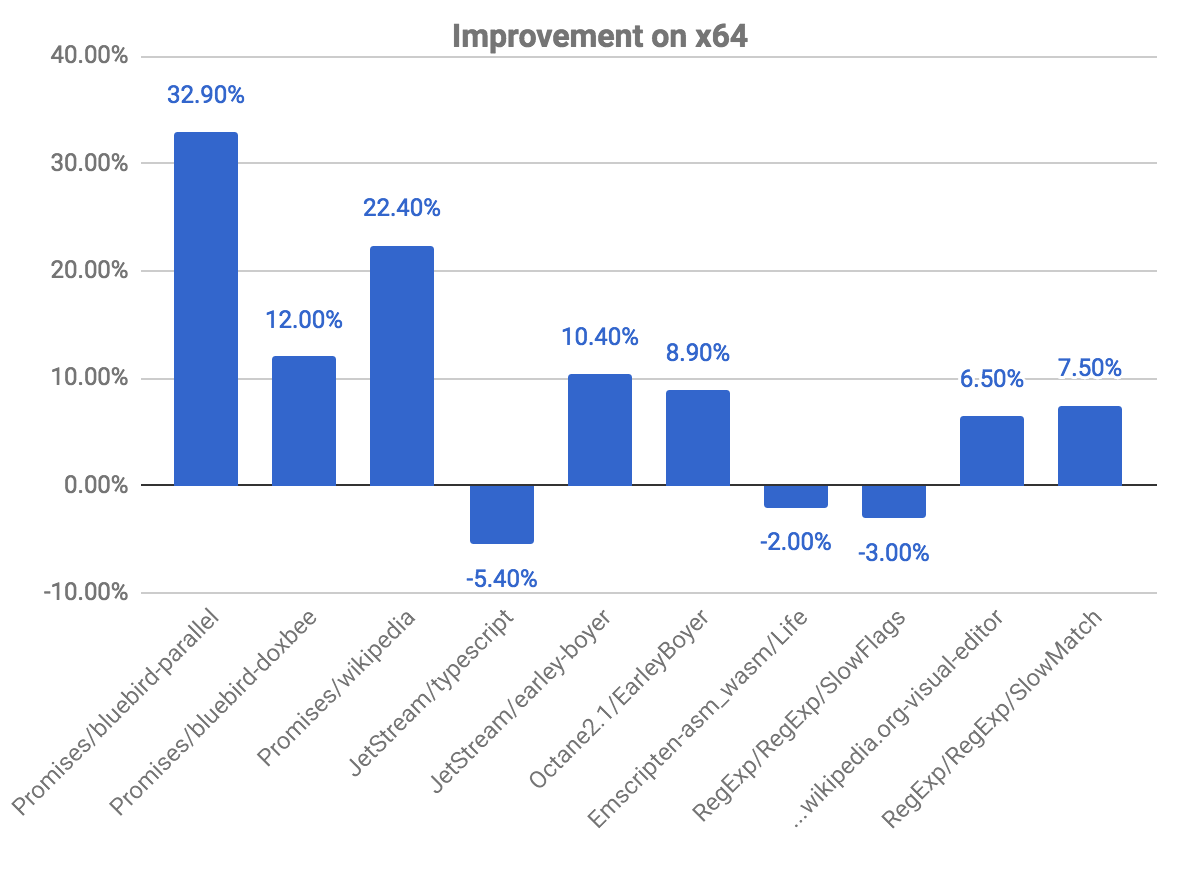
Os benchmarks promises são aqueles em que vemos maiores melhorias, observando quase 33% de ganho no benchmark bluebird-parallel e 22,40% no wikipedia. Também observamos algumas regressões em alguns benchmarks. Isso está relacionado ao problema explicado acima, sobre verificar se o código está marcado para desotimização.
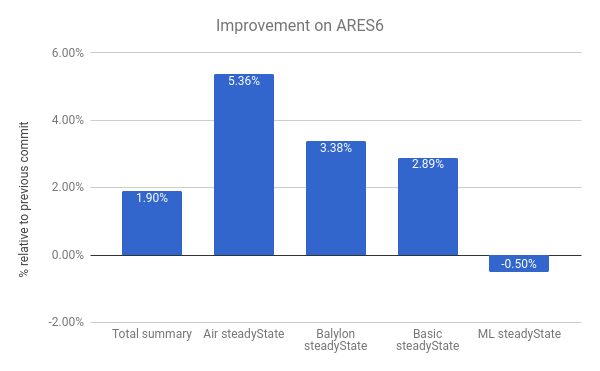
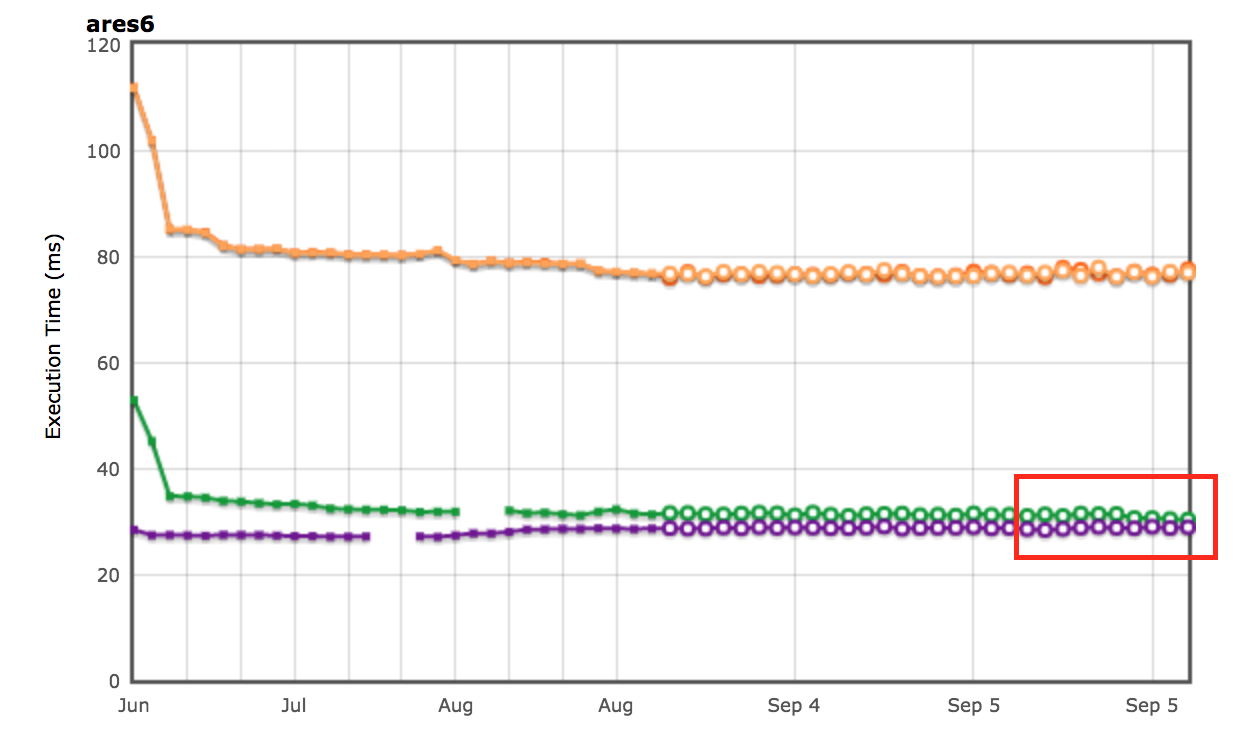
Também vemos melhorias na suíte de benchmarks ARES-6. Note que neste gráfico também, quanto mais alto, melhor. Esses programas costumavam gastar considerável quantidade de tempo em atividades relacionadas ao GC. Com desvinculação preguiçosa, melhoramos o desempenho em 1.9% no geral. O caso mais notável é o Air steadyState, onde conseguimos uma melhoria de cerca de 5.36%.
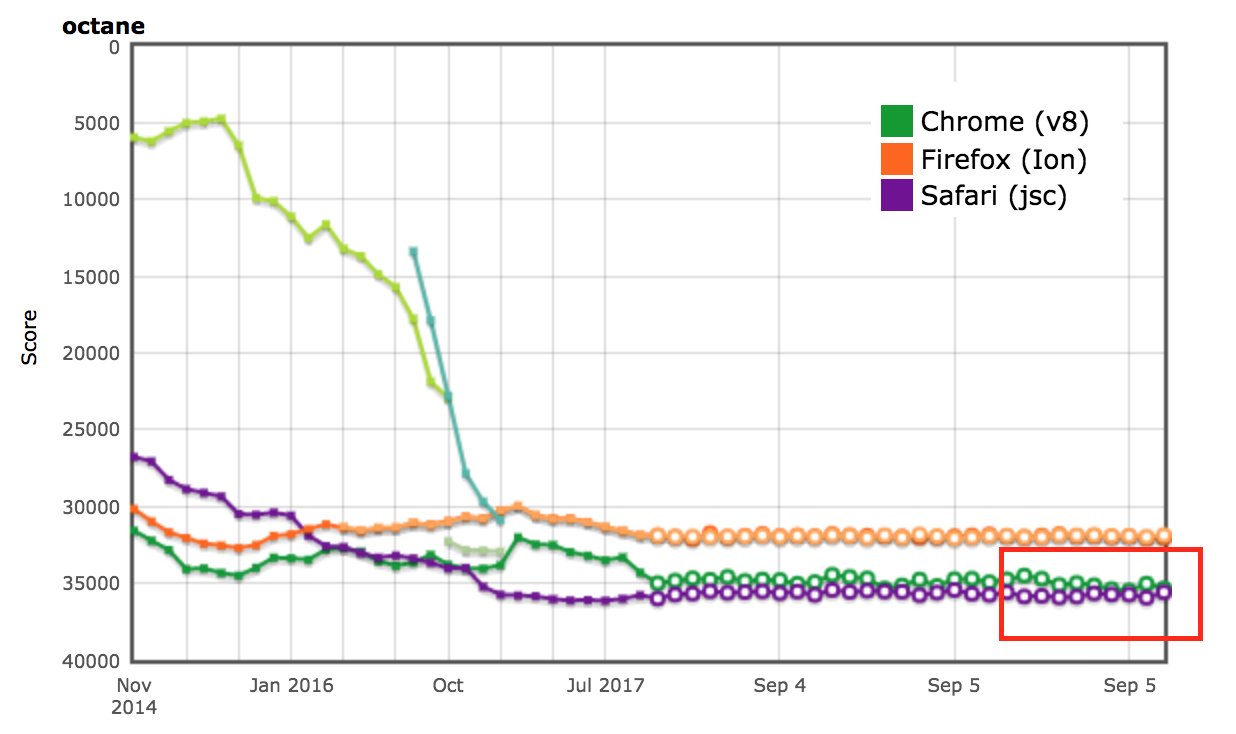
Resultados do AreWeFastYet
Os resultados de desempenho para as suítes de benchmark Octane e ARES-6 também apareceram no rastreador AreWeFastYet. Observamos esses resultados de desempenho em 5 de setembro de 2017, usando a máquina padrão fornecida (macOS 10.10 64-bit, Mac Pro, shell).
Impacto no Node.js
Também podemos ver melhorias de desempenho no router-benchmark. Os dois gráficos a seguir mostram o número de operações por segundo de cada roteador testado. Assim, quanto maior, melhor. Realizamos dois tipos de experimentos com esta suíte de benchmarks. Primeiro, executamos cada teste isoladamente, para que pudéssemos ver a melhoria de desempenho, independentemente dos testes restantes. Em segundo lugar, executamos todos os testes de uma vez, sem alternância da VM, simulando um ambiente onde cada teste está integrado com outras funcionalidades.
No primeiro experimento, vimos que os testes router e express executam cerca do dobro de operações em comparação com antes, no mesmo período de tempo. No segundo experimento, vimos ainda maior melhora. Em alguns dos casos, como routr, server-router e router, o benchmark realiza aproximadamente 3.80×, 3× e 2× mais operações, respectivamente. Isso ocorre porque o V8 acumula mais funções JavaScript otimizadas, teste após teste. Assim, sempre que um ciclo de coleta de lixo é acionado, o V8 precisa visitar as funções otimizadas do teste atual e dos anteriores.


Otimização adicional
Agora que o V8 não mantém a lista vinculada de funções JavaScript no contexto, podemos remover o campo next da classe JSFunction. Embora esta seja uma modificação simples, ela nos permite economizar o tamanho de um ponteiro por função, o que representa economias significativas em várias páginas web:
| Benchmark | Tipo | Economia de memória (absoluta) | Economia de memória (relativa) |
|---|---|---|---|
| facebook.com | Tamanho médio efetivo | 170 KB | 3.70% |
| twitter.com | Tamanho médio dos objetos alocados | 284 KB | 1.20% |
| cnn.com | Tamanho médio dos objetos alocados | 788 KB | 1.53% |
| youtube.com | Tamanho médio dos objetos alocados | 129 KB | 0.79% |
Agradecimentos
Ao longo do meu estágio, recebi muita ajuda de várias pessoas, que estavam sempre disponíveis para responder às minhas inúmeras perguntas. Assim, gostaria de agradecer às seguintes pessoas: Benedikt Meurer, Jaroslav Sevcik e Michael Starzinger pelas discussões sobre como o compilador e o deoptimizer funcionam, Ulan Degenbaev por ajudar com o coletor de lixo sempre que eu o quebrava, e Mathias Bynens, Peter Marshall, Camillo Bruni e Maya Armyanova por revisarem este artigo.
Por fim, este artigo é minha última contribuição como estagiário do Google, e gostaria de aproveitar a oportunidade para agradecer a todos na equipe do V8, e especialmente ao meu anfitrião, Benedikt Meurer, por me acolher e por me dar a oportunidade de trabalhar em um projeto tão interessante — definitivamente aprendi muito e aproveitei meu tempo no Google!