V8 힙 스냅샷 가속화
이 블로그 게시물은 José Dapena Paz (Igalia)가 작성했으며, Jason Williams (Bloomberg), Ashley Claymore (Bloomberg), Rob Palmer (Bloomberg), Joyee Cheung (Igalia), Shu-yu Guo (Google)의 기여로 작성되었습니다.
이 게시물에서는 V8 힙 스냅샷과 관련된 Bloomberg 엔지니어들이 발견한 몇 가지 성능 문제와 이를 해결하여 JavaScript 메모리 분석을 그 어느 때보다 빠르게 만든 방법에 대해 설명합니다.
문제
Bloomberg 엔지니어들은 JavaScript 애플리케이션에서 메모리 누수를 진단하려 하고 있었습니다. 이 애플리케이션은 메모리 부족(Out-Of-Memory) 오류로 실패하고 있었습니다. 테스트된 애플리케이션의 경우, V8 힙 한도가 약 1400 MB로 설정되어 있었습니다. 일반적으로 V8의 가비지 컬렉터는 힙 사용량을 이 한도 이하로 유지할 수 있어야 하므로 이러한 실패는 누수가 있을 가능성을 나타냅니다.
이런 일반적인 메모리 누수 시나리오를 디버그하는 일반적인 기술은 먼저 힙 스냅샷을 캡처한 다음, DevTools의 "Memory" 탭에서 이를 로드하고 다양한 요약 및 객체 속성을 검사하여 가장 많은 메모리를 소비하는 것이 무엇인지 알아내는 것입니다. DevTools UI에서 힙 스냅샷은 "Memory" 탭에서 캡처할 수 있습니다. Node.js 애플리케이션의 경우, 힙 스냅샷은 프로그래밍 방식으로 트리거될 수 있습니다 API를 사용하여 다음과 같이 실행합니다:
require('v8').writeHeapSnapshot();
그들은 애플리케이션 수명의 여러 시점에서 여러 스냅샷을 캡처하여 DevTools 메모리 뷰어에서 서로 다른 시점의 힙 사이의 차이를 표시하려고 했습니다. 문제는 단일 전체 크기(500 MB) 스냅샷을 캡처하는 데 30분 이상이 걸렸다는 것입니다!
이렇게 느린 메모리 분석 워크플로우를 해결하는 것이 우리의 과제였습니다.
문제 좁히기
그런 다음, Bloomberg 엔지니어들은 V8 매개변수를 사용하여 문제를 조사하기 시작했습니다. 이 게시물에 설명된 대로, Node.js 및 V8에는 문제를 해결하는 데 도움이 되는 몇 가지 매력적인 명령줄 매개변수가 있습니다. 이러한 옵션을 사용하여 힙 스냅샷을 생성하고, 문제를 재현하는 과정을 단순화하며, 관찰 가능성을 개선했습니다:
--max-old-space-size=100: 힙을 100메가바이트로 제한하여 문제를 훨씬 빠르게 재현할 수 있도록 합니다.--heapsnapshot-near-heap-limit=10: Node.js에서 메모리 부족에 가까울 때마다 스냅샷을 생성하도록 하는 특정 명령줄 매개변수입니다. 총 10개의 스냅샷을 생성하도록 구성됩니다. 이는 메모리에 굶주린 프로그램이 필요 이상으로 많은 스냅샷을 생성하느라 오랜 시간을 소비하지 않도록 방지합니다.--enable-etw-stack-walking: ETW, WPA 및 xperf와 같은 도구가 V8에서 호출된 JS 스택을 볼 수 있도록 합니다. (Node.js v20+에서 사용 가능)--interpreted-frames-native-stack: 이 플래그는 ETW, WPA 및 xperf와 같은 도구를 사용해 프로파일링할 때 네이티브 스택을 볼 수 있도록 사용됩니다. (Node.js v20+에서 사용 가능).
V8 힙 크기가 한도에 가까워지면 V8은 메모리 사용량을 줄이기 위해 가비지 컬렉션을 강제로 실행합니다. 또한 이를 임베더에게 알립니다. Node.js의 --heapsnapshot-near-heap-limit 플래그는 알림이 있을 때 새 힙 스냅샷을 생성합니다. 테스트 사례에서 메모리 사용량이 감소했지만, 여러 반복 후 갤비지 컬렉션은 결국 충분한 공간을 확보하지 못하고 애플리케이션이 메모리 부족(Out-Of-Memory) 오류로 종료됩니다.
그들은 Windows Performance Analyzer(아래 참조)를 사용하여 녹화를 실행하며 문제를 좁혔습니다. 이를 통해 CPU 시간이 대부분 V8 힙 탐색기에서 소비되고 있음을 알게 되었습니다. 특히, 힙을 탐색하여 각 노드를 방문하고 이름을 수집하는 데만 약 30분이 소요되었습니다. 이는 별로 납득이 되지 않았습니다 — 왜 각 속성의 이름을 기록하는 데 그렇게 오래 걸릴까요?
이 시점에서 제가 조사를 요청받았습니다.
문제 정량화
첫 번째 단계는 V8에서 힙 스냅샷 캡처 중에 시간이 어디에서 소비되는지 더 잘 이해할 수 있도록 지원을 추가하는 것이었습니다. 캡처 프로세스 자체는 생성 및 직렬화 두 단계로 나뉩니다. 우리는 이 패치를 V8에 업스트림으로 적용하여 --profile_heap_snapshot이라는 새 명령줄 플래그를 도입했으며, 이를 통해 생성 및 직렬화 시간을 로깅할 수 있습니다.
이 플래그를 사용하여 우리는 몇 가지 흥미로운 사실을 알아냈습니다!
우선, V8이 각 스냅샷을 생성하는 데 소요한 정확한 시간을 관찰할 수 있었습니다. 축소된 테스트 케이스에서는 첫 번째 스냅샷에 5분, 두 번째 스냅샷에 8분이 걸렸으며, 이후의 각 스냅샷은 점점 더 많은 시간이 걸렸습니다. 이 시간의 대부분은 생성 단계에서 소비되었습니다.
이는 또한 아주 적은 오버헤드로 스냅샷 생성에 소요된 시간을 정량화할 수 있게 해주었고, 이를 통해 다른 널리 사용되는 자바스크립트 애플리케이션(특히 TypeScript의 ESLint)에서 유사한 속도 저하를 격리 및 식별할 수 있었습니다. 따라서 문제가 특정 앱에 국한되지 않았음을 알게 되었습니다.
게다가, 우리는 이 문제가 Windows와 Linux에서 모두 발생한다는 것을 발견했습니다. 즉, 문제는 특정 플랫폼에 국한되지 않았습니다.
첫 번째 최적화: 개선된 StringsStorage 해싱
과도한 지연의 원인을 파악하기 위해 Windows Performance Toolkit을 사용하여 실패한 스크립트를 프로파일링했습니다.
Windows Performance Analyzer로 기록을 열었을 때 다음과 같은 내용을 발견했습니다:
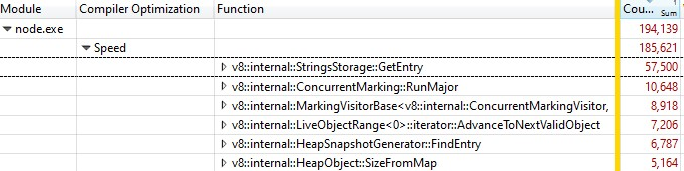
샘플의 3분의 1은 v8::internal::StringsStorage::GetEntry에서 소비되었습니다:
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
릴리스 빌드에서 실행되었기 때문에 인라인된 함수 호출 정보가 StringsStorage::GetEntry()에 통합되었습니다. 인라인 함수 호출에 정확히 얼마나 많은 시간이 소요되는지 알아내기 위해 "Source Line Number" 열을 분해에 추가했으며, 대부분의 시간이 182번 라인에 소비된 것을 발견했습니다. 이 호출은 ComputeStringHash()를 호출하는 부분이었습니다:
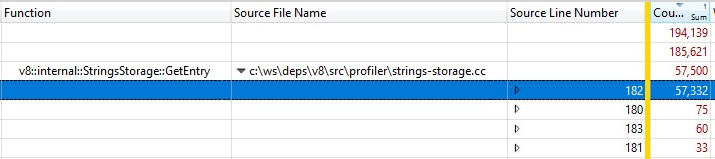
따라서 스냅샷 생성 시간의 30% 이상이 ComputeStringHash()에서 소비되었습니다. 하지만 왜 그런 걸까요?
StringsStorage에 대해 먼저 이야기해 봅시다. 이 클래스의 목적은 힙 스냅샷에서 사용될 모든 문자열의 고유한 복사본을 저장하는 것입니다. 빠른 액세스와 중복 방지를 위해 이 클래스는 배열로 지원되는 해시맵을 사용하며, 충돌은 배열에서 다음 빈 위치에 요소를 저장하는 방식으로 처리됩니다.
저는 충돌로 인해 배열에서 긴 검색이 발생할 수 있다는 점에서 문제가 발생할 수 있다고 의심하기 시작했습니다. 그래서 생성된 해시 키와 삽입 시 해시 키로 계산된 예상 위치와 충돌로 인해 실제 항목이 위치하게 된 거리 간의 차이를 보기 위해 철저한 로그를 추가했습니다.
로그에서는 상황이 정상적이지 않았습니다: 많은 항목들의 오프셋이 20을 초과했고, 최악의 경우에는 수천 단위였습니다!
문제의 일부는 숫자 문자열(특히 연속적인 숫자 범위에 대한 문자열)에 의해 발생했습니다. 해시 키 알고리즘은 숫자 문자열과 기타 문자열에 대해 두 가지 구현을 사용했습니다. 문자열 해시 함수는 꽤 고전적이었지만, 숫자 문자열에 대한 구현은 기본적으로 숫자 값 앞에 자리 수를 추가하여 반환하는 방식이었습니다:
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
이 함수는 문제가 있었습니다. 이 해시 함수의 문제 몇 가지 예는 다음과 같습니다:
- 해시 키 값이 작은 숫자인 문자열을 삽입하자마자, 해당 위치에 또 다른 숫자를 저장하려고 하면 충돌이 발생하며, 연속적으로 숫자를 저장하려고 하면 유사한 충돌이 발생합니다.
- 혹은 더 나쁘게도: 맵에 이미 연속적인 숫자들이 많이 저장되어 있고, 우리가 그 범위에 해시 키 값이 있는 문자열을 삽입하려고 하면, 해당 항목이 빈 위치를 찾을 때까지 모든 점유된 위치로 이동해야 했습니다.
이를 어떻게 해결했을까요? 이 문제는 주로 문자열로 표현된 숫자가 연속적인 위치에 떨어지는 경우 발생하기 때문에, 저는 해시 함수를 수정하여 생성된 해시 값을 왼쪽으로 2비트 회전하도록 했습니다.
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
그래서 연속적인 숫자 쌍마다 중간에 3개의 빈 위치가 생기게 했습니다. 이 수정은 여러 작업 집합에서의 경험적 테스트를 통해 충돌을 최소화하는 데 가장 효과적이라고 입증되었기 때문에 선택되었습니다.
해싱 수정이 V8에 반영되었습니다.
두 번째 최적화: 소스 위치 캐싱
해싱을 수정한 후, 프로파일링을 다시 진행하여 오버헤드를 상당 부분 줄일 수 있는 추가 최적화 기회를 발견했습니다.
힙 스냅샷을 생성할 때, 힙 내의 각 함수에 대해 V8은 라인과 열 번호의 쌍으로 시작 위치를 기록하려고 합니다. 이 정보는 DevTools에서 함수의 소스 코드를 연결하는 데 사용될 수 있습니다. 하지만 일반적인 컴파일 중에는 V8이 각 함수의 시작 위치를 스크립트의 시작 지점으로부터의 선형 오프셋 형태로만 저장합니다. 선형 오프셋을 바탕으로 라인과 열 번호를 계산하기 위해, V8은 전체 스크립트를 순회하며 라인 나누기 지점(line breaks)을 기록해야 합니다. 이 계산은 매우 비용이 많이 듭니다.
일반적으로, V8이 스크립트 내 라인 나누기 지점의 오프셋을 계산한 후, 이를 스크립트에 연결된 새로 할당된 배열에 캐싱합니다. 그러나 스냅샷 구현은 힙을 순회할 때 힙을 수정할 수 없기 때문에, 새로 계산된 라인 정보는 캐싱될 수 없습니다.
해결책은 무엇일까요? 이제 힙 스냅샷을 생성하기 전에 V8 컨텍스트에 있는 모든 스크립트를 순회하여 라인 나누기 오프셋을 계산하고 캐싱합니다. 이는 힙 스냅샷을 생성하기 위해 힙을 순회할 때 실행되는 것이 아니므로, 여전히 힙을 수정하고 소스 라인 위치를 캐시로 저장할 수 있게 됩니다.
라인 나누기 오프셋 캐싱 수정이 역시 V8에 반영되었습니다.
과연 빨라졌을까요?
두 가지 수정 사항을 적용한 후, 다시 프로파일링을 진행했습니다. 두 수정 사항 모두 스냅샷 생성 시간에만 영향을 미치므로, 예상대로 스냅샷 직렬화 시간에는 영향을 미치지 않았습니다.
JS 프로그램에서 다음이 포함된 경우:
- 개발 환경 JS의 경우, 생성 시간이 50% 더 빨라졌습니다 👍
- 프로덕션 환경 JS의 경우, 생성 시간이 90% 더 빨라졌습니다 😮
왜 개발 코드와 프로덕션 코드 간에 큰 차이가 있었을까요? 프로덕션 코드는 번들링 및 압축으로 최적화되므로 JS 파일이 적고, 이러한 파일은 크기가 큰 경향이 있습니다. 이러한 큰 파일의 소스 라인 위치를 계산하는 데 시간이 걸리므로, 소스 위치를 캐싱하고 계산을 반복하지 않을 경우 가장 큰 혜택을 얻습니다.
최적화는 Windows와 Linux 대상 환경 모두에서 검증되었습니다.
Bloomberg 엔지니어들이 원래 직면했던 특히 까다로운 문제에 대해, 100MB 스냅샷을 캡처하는 총 소요 시간이 고통스러웠던 10분에서 매우 쾌적한 6초로 단축되었습니다. 이는 100배의 개선입니다! 🔥
이 최적화는 V8, Node.js, Chromium에서 메모리 디버깅을 수행하는 누구에게나 광범위하게 적용될 수 있는 일반적 성과입니다. 이러한 성과는 V8 v11.5.130에 포함되어 있으며, 이는 Chromium 115.0.5576.0에서 확인할 수 있습니다. 이러한 최적화가 Node.js의 향후 주요 버전에 통합되기를 기대합니다.
앞으로의 계획?
첫째, Node.js가 NODE_OPTIONS에서 새로운 --profile-heap-snapshot 플래그를 수락하는 것이 유용할 것입니다. 일부 사용 사례에서는 사용자가 Node.js에 전달되는 명령줄 옵션을 직접 제어할 수 없으며, 환경 변수 NODE_OPTIONS를 통해 이를 구성해야 합니다. 현재 Node.js는 환경 변수에 설정된 V8 명령줄 옵션을 필터링하고, 알려진 하위 집합만 허용하므로, 우리의 경우처럼 Node.js에서 새로운 V8 플래그를 테스트하기가 더 어려워질 수 있습니다.
스냅샷의 정보 정확도를 더욱 향상시킬 수 있습니다. 현재 각 스크립트 소스 코드 줄 정보는 V8 힙 자체에 표현으로 저장됩니다. 그러나 이것은 우리가 관찰하고 있는 대상에 성능 측정 오버헤드가 영향을 미치지 않도록 힙을 정확히 측정하려고 하기 때문에 문제가 됩니다. 이상적으로는, 힙 스냅샷 정보를 더 정확하게 만들기 위해, 라인 정보 캐시를 V8 힙 외부에 저장해야 합니다.
마지막으로, 생성 단계가 개선되었기 때문에 이제 가장 큰 비용은 직렬화 단계입니다. 추가 분석을 통해 직렬화에서 새로운 최적화 기회를 발견할 수 있을지도 모릅니다.