Accélération des instantanés de tas V8
Cet article de blog a été rédigé par José Dapena Paz (Igalia), avec les contributions de Jason Williams (Bloomberg), Ashley Claymore (Bloomberg), Rob Palmer (Bloomberg), Joyee Cheung (Igalia) et Shu-yu Guo (Google).
Dans cet article sur les instantanés de tas V8, je vais parler de certains problèmes de performance rencontrés par les ingénieurs de Bloomberg et comment nous les avons résolus pour rendre l'analyse mémoire JavaScript plus rapide que jamais.
Le problème
Les ingénieurs de Bloomberg travaillaient sur le diagnostic d'une fuite mémoire dans une application JavaScript. Elle échouait avec des erreurs de type Out-Of-Memory. Pour l'application testée, la limite du tas V8 était configurée autour de 1400 Mo. Normalement, le ramasse-miettes de V8 devrait pouvoir maintenir l'utilisation du tas en dessous de cette limite, de sorte que les échecs indiquent probablement une fuite.
Une technique courante pour déboguer un scénario de fuite mémoire de routine consiste à capturer un instantané de tas, puis à le charger dans l'onglet "Mémoire" des DevTools et à découvrir ce qui utilise le plus de mémoire en inspectant les différents résumés et attributs d'objets. Dans l'interface utilisateur de DevTools, l'instantané de tas peut être pris dans l'onglet "Mémoire". Pour les applications Node.js, l'instantané de tas peut être déclenché de manière programmatique en utilisant cette API:
require('v8').writeHeapSnapshot();
Ils voulaient capturer plusieurs instantanés à différents moments de la vie de l'application, afin que le visualiseur de mémoire de DevTools puisse être utilisé pour montrer la différence entre les tas à différents moments. Le problème était que capturer un seul instantané de taille complète (500 Mo) prenait plus de 30 minutes!
C'est cette lenteur dans le flux de travail d'analyse mémoire que nous devions résoudre.
Réduire le problème
Ensuite, les ingénieurs de Bloomberg ont commencé à enquêter sur le problème en utilisant certains paramètres de V8. Comme décrit dans cet article, Node.js et V8 ont quelques paramètres de ligne de commande utiles à cet effet. Ces options ont été utilisées pour créer les instantanés de tas, simplifier la reproduction et améliorer l'observabilité :
--max-old-space-size=100: Cela limite le tas à 100 mégaoctets et aide à reproduire le problème beaucoup plus rapidement.--heapsnapshot-near-heap-limit=10: Il s'agit d'un paramètre de ligne de commande spécifique à Node.js qui indique à Node.js de générer un instantané chaque fois qu'il approche de la limite de mémoire. Il est configuré pour générer jusqu'à 10 instantanés au total. Cela évite la situation où le programme à court de mémoire passe beaucoup de temps à produire plus d'instantanés que nécessaire.--enable-etw-stack-walking: Cela permet à des outils tels que ETW, WPA et xperf de voir la pile JS appelée dans V8. (disponible dans Node.js v20+)--interpreted-frames-native-stack: Ce drapeau est utilisé en combinaison avec des outils comme ETW, WPA et xperf pour voir la pile native lors du profilage. (disponible dans Node.js v20+).
Lorsque la taille du tas V8 approche de sa limite, V8 force un ramassage de mémoire pour réduire l'utilisation. Il informe également l'intégrateur à ce sujet. Le drapeau --heapsnapshot-near-heap-limit dans Node.js génère un nouvel instantané de tas après notification. Dans le cas de test, l'utilisation de la mémoire diminue, mais, après plusieurs itérations, le ramassage de mémoire ne peut finalement pas libérer suffisamment d'espace et l'application est alors arrêtée avec une erreur Out-Of-Memory.
Ils ont effectué des enregistrements en utilisant Windows Performance Analyzer (voir ci-dessous) afin de réduire le problème. Cela a révélé que la majeure partie du temps CPU était passée dans l'explorateur de tas V8. Plus précisément, cela prenait environ 30 minutes juste pour parcourir le tas, visiter chaque nœud et collecter le nom. Cela ne semblait pas avoir de sens — pourquoi enregistrer le nom de chaque propriété prendrait-il autant de temps ?
C'est à ce moment-là qu'on m'a demandé d'examiner le problème.
Quantifier le problème
La première étape consistait à ajouter un support dans V8 pour mieux comprendre où le temps est consacré lors de la capture des instantanés de tas. Le processus de capture lui-même est divisé en deux phases : génération, puis sérialisation. Nous avons introduit ce patch en amont pour ajouter un nouveau drapeau de ligne de commande --profile_heap_snapshot à V8, qui permet de consigner les temps de génération et de sérialisation.
Avec ce drapeau, nous avons appris des choses intéressantes !
Tout d'abord, nous avons pu observer la durée précise que V8 consacrait à la génération de chaque instantané. Dans notre cas de test réduit, le premier a pris 5 minutes, le deuxième a pris 8 minutes, et chaque instantané suivant continuait de prendre de plus en plus de temps. Presque tout ce temps était consacré à la phase de génération.
Cela nous a également permis de quantifier le temps consacré à la génération d'instantanés avec une surcharge triviale, ce qui nous a aidé à isoler et identifier des ralentissements similaires dans d'autres applications JavaScript largement utilisées - en particulier, ESLint sur TypeScript. Nous savons donc que le problème n'était pas spécifique à l'application.
De plus, nous avons constaté que le problème se produisait à la fois sur Windows et Linux. Le problème n'était donc pas spécifique à la plateforme.
Première optimisation : amélioration du hachage de StringsStorage
Pour identifier ce qui causait le délai excessif, j'ai profilé le script défaillant en utilisant Windows Performance Toolkit.
Lorsque j'ai ouvert l'enregistrement avec Windows Performance Analyzer, voici ce que j'ai trouvé :
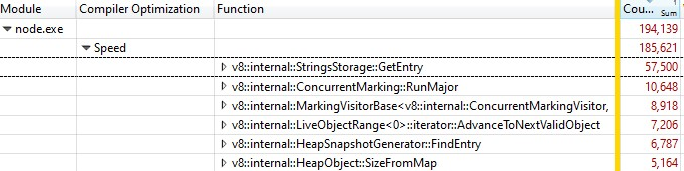
Un tiers des échantillons était consacré à v8::internal::StringsStorage::GetEntry :
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
Étant donné que cela a été exécuté avec une version de build release, les informations des appels de fonctions inline ont été regroupées dans StringsStorage::GetEntry(). Pour déterminer exactement combien de temps prenaient les appels de fonction inline, j'ai ajouté la colonne "Numéro de ligne source" à la répartition et constaté que la majeure partie du temps était consacrée à la ligne 182, qui était un appel à ComputeStringHash() :
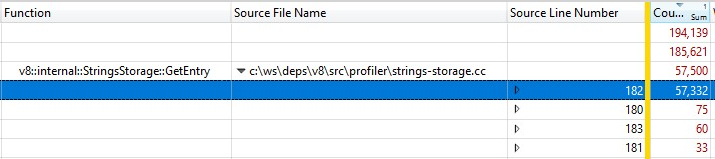
Ainsi, plus de 30 % du temps de génération des instantanés était consacré à ComputeStringHash(), mais pourquoi ?
Parlons d'abord de StringsStorage. Son objectif est de stocker une copie unique de toutes les chaînes qui seront utilisées dans l'instantané du tas. Pour un accès rapide et éviter les doublons, cette classe utilise une hashmap soutenue par un tableau, où les collisions sont gérées en stockant les éléments dans le prochain emplacement libre du tableau.
J'ai commencé à soupçonner que le problème pouvait être causé par des collisions, ce qui pourrait entraîner de longues recherches dans le tableau. J'ai donc ajouté des journaux exhaustifs pour voir les clés de hachage générées et, lors de l'insertion, voir la distance entre la position attendue calculée à partir de la clé de hachage et la position réelle où l'entrée était finalement placée en raison des collisions.
Dans les journaux, les choses n'allaient pas bien : le décalage de nombreux éléments dépassait 20, et dans le pire des cas, de l'ordre de milliers !
Une partie du problème était causée par des chaînes numériques — en particulier des chaînes représentant une large gamme de nombres consécutifs. L'algorithme de clé de hachage possédait deux implémentations, une pour les chaînes numériques et une autre pour les autres chaînes. Alors que la fonction de hachage des chaînes était assez classique, l'implémentation pour les chaînes numériques renvoyait essentiellement la valeur du nombre précédée par le nombre de chiffres :
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
Cette fonction posait problème. Voici quelques exemples de problèmes liés à cette fonction de hachage :
- Une fois qu'une chaîne dont la clé de hachage avait une valeur faible était insérée, nous rencontrions des collisions lorsque nous essayions de stocker un autre nombre à cet emplacement, et des collisions similaires se produisaient si nous essayions de stocker des nombres consécutifs.
- Ou pire encore : si un grand nombre de nombres consécutifs étaient déjà stockés dans la carte et que nous voulions insérer une chaîne dont la clé de hachage se trouvait dans cette plage, nous devions déplacer l'entrée le long de tous les emplacements occupés pour trouver un emplacement libre.
Qu'ai-je fait pour résoudre cela ? Comme le problème provient principalement des nombres représentés sous forme de chaînes qui tomberaient dans des positions consécutives, j'ai modifié la fonction de hachage afin de faire pivoter la valeur de hachage résultante de 2 bits vers la gauche.
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
Ainsi, pour chaque paire de nombres consécutifs, nous introduisions 3 positions libres entre eux. Cette modification a été choisie car les tests empiriques sur plusieurs ensembles de travail ont montré qu'elle était la meilleure pour minimiser les collisions.
Cette correction de hachage a été intégrée dans V8.
Deuxième optimisation : mise en cache des positions de source
Après avoir corrigé le hachage, nous avons reprofilé et identifié une nouvelle opportunité d'optimisation qui permettrait de réduire une partie significative de la surcharge.
Lors de la génération d'une capture du tas, pour chaque fonction dans le tas, V8 tente d'enregistrer sa position de début dans une paire de numéros de ligne et de colonne. Ces informations peuvent être utilisées par les DevTools pour afficher un lien vers le code source de la fonction. Cependant, lors de la compilation normale, V8 stocke uniquement la position de début de chaque fonction sous forme d'un déplacement linéaire à partir du début du script. Pour calculer les numéros de ligne et de colonne à partir du déplacement linéaire, V8 doit traverser tout le script et enregistrer où se trouvent les sauts de ligne. Ce calcul s'avère très coûteux.
Normalement, après que V8 a fini de calculer les décalages des sauts de ligne dans un script, il les met en cache dans un tableau nouvellement alloué attaché au script. Malheureusement, l'implémentation de la capture ne peut pas modifier le tas lorsqu'elle le parcourt, donc les informations de ligne nouvellement calculées ne peuvent pas être mises en cache.
La solution ? Avant de générer la capture du tas, nous parcourons maintenant tous les scripts du contexte V8 pour calculer et mettre en cache les décalages des sauts de ligne. Étant donné que cela n'est pas fait lors de la traversée du tas pour la génération de la capture, il est toujours possible de modifier le tas et de stocker les positions des lignes sources en tant que cache.
La correction pour la mise en cache des décalages des sauts de ligne a également été intégrée dans V8.
L'avons-nous rendu rapide ?
Après avoir activé les deux corrections, nous avons reprofilé. Nos deux corrections n'affectent que le temps de génération de la capture, donc, comme prévu, les temps de sérialisation des captures n'ont pas été modifiés.
Lors de l'exécution sur un programme JS contenant…
- JS de développement, le temps de génération est 50 % plus rapide 👍
- JS de production, le temps de génération est 90 % plus rapide 😮
Pourquoi y a-t-il une différence massive entre le code de production et de développement ? Le code de production est optimisé à l'aide de l'empaquetage et de la minification, donc il y a moins de fichiers JS, et ces fichiers ont tendance à être grands. Il faut plus de temps pour calculer les positions des lignes sources pour ces fichiers volumineux, donc ils bénéficient le plus lorsque nous pouvons mettre en cache les positions sources et éviter de répéter les calculs.
Les optimisations ont été validées sur les environnements cibles Windows et Linux.
Pour le problème particulièrement difficile rencontré initialement par les ingénieurs de Bloomberg, le temps total de capture d'une capture de 100 Mo a été réduit d'un douloureux 10 minutes à un très agréable 6 secondes. C'est un gain de 100× 🔥
Les optimisations sont des gains génériques que nous espérons être largement applicables à quiconque effectue du débogage mémoire sur V8, Node.js et Chromium. Ces gains ont été intégrés dans V8 v11.5.130, ce qui signifie qu'ils apparaissent dans Chromium 115.0.5576.0. Nous espérons que Node.js bénéficiera de ces optimisations dans la prochaine version majeure de semver.
Et après ?
Premièrement, il serait utile que Node.js accepte le nouveau flag --profile-heap-snapshot dans NODE_OPTIONS. Dans certains cas d'utilisation, les utilisateurs ne peuvent pas contrôler directement les options de ligne de commande passées à Node.js et doivent les configurer via la variable d'environnement NODE_OPTIONS. Aujourd'hui, Node.js filtre les options de ligne de commande V8 définies dans la variable d'environnement et n'autorise qu'un sous-ensemble connu, ce qui pourrait rendre plus difficile le test des nouveaux flags V8 dans Node.js, comme cela s'est produit dans notre cas.
L'exactitude des informations dans les captures peut être encore améliorée. Aujourd'hui, chaque ligne de code source de script est stockée dans une représentation dans le tas lui-même de V8. Et c'est un problème parce que nous voulons mesurer précisément le tas sans que la surcharge de mesure des performances n'affecte le sujet que nous observons. Idéalement, nous stockerions le cache des informations de lignes en dehors du tas de V8 afin de rendre les informations des captures du tas plus précises.
Enfin, maintenant que nous avons amélioré la phase de génération, le coût le plus important est désormais la phase de sérialisation. Une analyse plus approfondie pourrait révéler de nouvelles opportunités d'optimisation dans la sérialisation.
Remerciements
Cela a été rendu possible grâce au travail des ingénieurs de Igalia et Bloomberg.