Acelerando las instantáneas de montón de V8
Esta publicación en el blog ha sido escrita por José Dapena Paz (Igalia), con contribuciones de Jason Williams (Bloomberg), Ashley Claymore (Bloomberg), Rob Palmer (Bloomberg), Joyee Cheung (Igalia) y Shu-yu Guo (Google).
En esta publicación sobre instantáneas de montón de V8, hablaré sobre algunos problemas de rendimiento encontrados por ingenieros de Bloomberg, y cómo los solucionamos para que el análisis de memoria de JavaScript sea más rápido que nunca.
El problema
Los ingenieros de Bloomberg estaban trabajando en diagnosticar una fuga de memoria en una aplicación de JavaScript. Estaba fallando con errores de Falta de Memoria. Para la aplicación probada, el límite del montón de V8 estaba configurado en aproximadamente 1400 MB. Normalmente, el colector de basura de V8 debería poder mantener el uso del montón por debajo de ese límite, por lo que los fallos indicaban que probablemente había una fuga.
Una técnica común para depurar un escenario de fuga de memoria rutinario como este es capturar primero una instantánea de montón, luego cargarla en la pestaña “Memoria” de DevTools y averiguar qué está consumiendo más memoria inspeccionando los distintos resúmenes y atributos de los objetos. En la interfaz de DevTools, la instantánea de montón puede tomarse en la pestaña “Memoria”. Para aplicaciones de Node.js, la instantánea de montón puede activarse programáticamente utilizando esta API:
require('v8').writeHeapSnapshot();
Querían capturar varias instantáneas en diferentes puntos de la vida útil de la aplicación, de modo que el visor de memoria de DevTools pudiera mostrar la diferencia entre los montones en diferentes momentos. El problema era que capturar una sola instantánea de tamaño completo (500 MB) estaba tomando más de 30 minutos!
Era esta lentitud en el flujo de trabajo de análisis de memoria lo que necesitábamos resolver.
Delimitando el problema
Entonces, los ingenieros de Bloomberg comenzaron a investigar el problema utilizando algunos parámetros de V8. Como se describe en esta publicación, Node.js y V8 tienen algunos parámetros de línea de comandos útiles que pueden ayudar con esto. Estas opciones se utilizaron para crear las instantáneas de montón, simplificar la reproducción y mejorar la observabilidad:
--max-old-space-size=100: Esto limita el montón a 100 megabytes y ayuda a reproducir el problema mucho más rápido.--heapsnapshot-near-heap-limit=10: Este es un parámetro específico de línea de comandos de Node.js que indica a Node.js que genere una instantánea cada vez que esté cerca de quedarse sin memoria. Está configurado para generar hasta 10 instantáneas en total. Esto evita el desgaste donde el programa con falta de memoria pasa mucho tiempo produciendo más instantáneas de las necesarias.--enable-etw-stack-walking: Esto permite a herramientas como ETW, WPA y xperf ver la pila JS que ha sido llamada en V8. (disponible en Node.js v20+)--interpreted-frames-native-stack: Esta bandera se usa en combinación con herramientas como ETW, WPA y xperf para ver la pila nativa al realizar perfiles. (disponible en Node.js v20+).
Cuando el tamaño del montón de V8 se acerca al límite, V8 fuerza una recolección de basura para reducir el uso de memoria. También notifica al incrustador sobre esto. La bandera --heapsnapshot-near-heap-limit en Node.js genera una nueva instantánea de montón tras la notificación. En el caso de prueba, el uso de memoria disminuye, pero, después de varias iteraciones, la recolección de basura finalmente no puede liberar suficiente espacio y, por lo tanto, la aplicación se termina con un error de Falta de Memoria.
Tomaron grabaciones utilizando Windows Performance Analyzer (ver más abajo) para delimitar el problema. Esto reveló que la mayor parte del tiempo de CPU se estaba gastando dentro del Explorador de Montón de V8. Específicamente, tomó alrededor de 30 minutos solo caminar por el montón para visitar cada nodo y recolectar el nombre. Esto no parecía tener mucho sentido — ¿por qué grabar el nombre de cada propiedad tomaría tanto tiempo?
Fue entonces cuando se me pidió que echara un vistazo.
Cuantificando el problema
El primer paso fue agregar soporte en V8 para comprender mejor dónde se invierte el tiempo durante la captura de instantáneas de montón. El proceso de captura en sí se divide en dos fases: generación y luego serialización. Implementamos este parche en el upstream para introducir una nueva bandera de línea de comandos --profile_heap_snapshot en V8, lo que habilita el registro de los tiempos de generación y serialización.
¡Usando esta bandera, aprendimos algunas cosas interesantes!
Primero, pudimos observar la cantidad exacta de tiempo que V8 estaba dedicando a generar cada instantánea. En nuestro caso de prueba reducido, la primera tomó 5 minutos, la segunda tomó 8 minutos, y cada instantánea subsecuente seguía tardando más y más tiempo. Casi todo este tiempo se gastó en la fase de generación.
Esto también nos permitió cuantificar el tiempo dedicado a la generación de instantáneas con un gasto mínimo, lo cual nos ayudó a aislar e identificar desaceleraciones similares en otras aplicaciones ampliamente usadas de JavaScript, en particular, ESLint en TypeScript. Así que sabemos que el problema no era específico de una aplicación.
Además, encontramos que el problema ocurría tanto en Windows como en Linux. El problema tampoco era específico de una plataforma.
Primera optimización: mejora del hashing en StringsStorage
Para identificar qué estaba causando el retraso excesivo, perfilé el script que fallaba usando Windows Performance Toolkit.
Cuando abrí la grabación con Windows Performance Analyzer, esto fue lo que encontré:
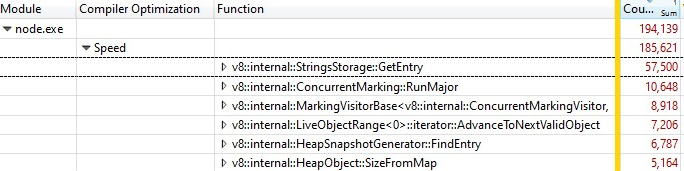
Un tercio de las muestras se gastó en v8::internal::StringsStorage::GetEntry:
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
Debido a que esto se ejecutó con una compilación de versión final, la información de las llamadas a funciones integradas se comprimió en StringsStorage::GetEntry(). Para averiguar exactamente cuánto tiempo estaban tomando las llamadas a funciones integradas, agregué la columna “Número de línea de origen” al desglose y encontré que la mayor parte del tiempo se gastaba en la línea 182, que era una llamada a ComputeStringHash():
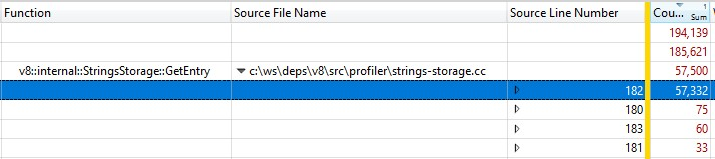
Así que más del 30% del tiempo de generación de instantáneas se gastó en ComputeStringHash(), pero ¿por qué?
Primero hablemos de StringsStorage. Su propósito es almacenar una copia única de todas las cadenas que se usarán en la instantánea del heap. Para un acceso rápido y para evitar duplicados, esta clase utiliza un hashmap respaldado por un arreglo, donde las colisiones se manejan almacenando elementos en la siguiente ubicación libre en el arreglo.
Empecé a sospechar que el problema podría deberse a colisiones, lo que podría llevar a búsquedas largas en el arreglo. Así que agregué registros exhaustivos para ver las claves hash generadas y, al insertar, observar qué tan lejos estaba entre la posición esperada calculada a partir de la clave hash y la posición real donde terminó la entrada debido a colisiones.
En los registros, las cosas estaban... mal: el desplazamiento de muchos elementos era superior a 20 y, en el peor de los casos, del orden de miles.
Parte del problema era causado por cadenas numéricas, especialmente cadenas para un rango amplio de números consecutivos. El algoritmo de la clave hash tenía dos implementaciones: una para cadenas numéricas y otra para otras cadenas. Mientras que la función de hash para cadenas era bastante clásica, la implementación para cadenas numéricas básicamente devolvía el valor del número precedido por la cantidad de dígitos:
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
Esta función era problemática. Algunos ejemplos de problemas con esta función de hash:
- Una vez que insertamos una cadena cuya clave hash era un número pequeño, encontrábamos colisiones al intentar almacenar otro número en esa ubicación, y habría colisiones similares si tratábamos de almacenar números subsecuentes consecutivamente.
- O aún peor: si ya había muchos números consecutivos almacenados en el mapa y queríamos insertar una cadena cuya clave hash estaba en ese rango, teníamos que mover la entrada por todas las ubicaciones ocupadas hasta encontrar una ubicación libre.
¿Qué hice para solucionarlo? Como el problema proviene principalmente de números representados como cadenas que caen en posiciones consecutivas, modifiqué la función hash para que rotara el valor hash resultante 2 bits hacia la izquierda.
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
Así que para cada par de números consecutivos, introdujimos 3 posiciones libres entre ellos. Esta modificación se eligió porque las pruebas empíricas con varios conjuntos de trabajo mostraron que funcionaba mejor para minimizar colisiones.
Esta solución de hashing se ha implementado en V8.
Segunda optimización: almacenamiento en caché de posiciones de fuente
Después de solucionar el problema de hashing, volvimos a analizar y encontramos una oportunidad de optimización adicional que reduciría una parte significativa del tiempo de procesamiento.
Al generar un snapshot del heap, para cada función en el heap, V8 trata de registrar su posición de inicio en un par de números de línea y columna. Esta información se utiliza por DevTools para mostrar un enlace al código fuente de la función. Sin embargo, durante la compilación habitual, V8 solo guarda la posición de inicio de cada función en forma de un desplazamiento lineal desde el principio del script. Para calcular los números de línea y columna basados en el desplazamiento lineal, V8 necesita recorrer todo el script y registrar dónde están los saltos de línea. Este cálculo resulta muy costoso.
Normalmente, después de que V8 termina de calcular los desplazamientos de los saltos de línea en un script, los almacena en un nuevo array adjunto al script. Desafortunadamente, la implementación del snapshot no puede modificar el heap mientras lo recorre, así que la información de línea recién calculada no puede almacenarse en caché.
¿La solución? Antes de generar el snapshot del heap, ahora iteramos sobre todos los scripts en el contexto de V8 para calcular y almacenar en caché los desplazamientos de los saltos de línea. Como esto no se realiza al recorrer el heap para generar el snapshot, todavía es posible modificar el heap y guardar las posiciones de línea origen como un caché.
La solución para el almacenamiento en caché de los desplazamientos de los saltos de línea también ha sido implementada en V8.
¿Lo hicimos rápido?
Después de habilitar ambas soluciones, volvimos a analizar. Nuestras dos soluciones solo afectan el tiempo de generación del snapshot, por lo que, como se esperaba, los tiempos de serialización del snapshot no se vieron afectados.
Al operar sobre un programa JS que contiene…
- JS de desarrollo, el tiempo de generación es 50% más rápido 👍
- JS de producción, el tiempo de generación es 90% más rápido 😮
¿Por qué hubo una diferencia tan notable entre el código de producción y el de desarrollo? El código de producción se optimiza mediante empaquetado y minificación, por lo que hay menos archivos JS, y estos archivos tienden a ser grandes. Lleva más tiempo calcular las posiciones de las líneas fuente para estos archivos grandes, por lo que se benefician más cuando podemos almacenar en caché la posición de la fuente y evitar cálculos repetidos.
Las optimizaciones fueron validadas en entornos objetivo tanto en Windows como en Linux.
Para el problema particularmente desafiante enfrentado originalmente por los ingenieros de Bloomberg, el tiempo total de captura de un snapshot de 100 MB se redujo de unos dolorosos 10 minutos a unos muy agradables 6 segundos. Eso es un incremento de rendimiento de 100×! 🔥
Las optimizaciones son mejoras genéricas que esperamos que sean ampliamente aplicables para cualquier persona que realice depuración de memoria en V8, Node.js y Chromium. Estas mejoras se implementaron en V8 v11.5.130, lo que significa que se encuentran en Chromium 115.0.5576.0. Esperamos que Node.js adopte estas optimizaciones en la próxima versión mayor de semver.
¿Qué sigue?
Primero, sería útil que Node.js aceptara la nueva bandera --profile-heap-snapshot en NODE_OPTIONS. En algunos casos de uso, los usuarios no pueden controlar directamente las opciones de línea de comandos que se pasan a Node.js y tienen que configurarlas a través de la variable de entorno NODE_OPTIONS. Actualmente, Node.js filtra las opciones de línea de comandos de V8 configuradas en la variable de entorno y solo permite un subconjunto conocido, lo que podría dificultar la prueba de nuevas banderas de V8 en Node.js, como sucedió en nuestro caso.
La precisión de la información en los snapshots podría mejorarse más. Hoy en día, la información de cada línea del código fuente del script se almacena en una representación dentro del heap de V8. Esto es un problema porque queremos medir el heap con precisión sin que la sobrecarga de medición del rendimiento afecte al objeto que estamos observando. Idealmente, almacenaríamos la caché de la información de línea fuera del heap de V8 para que la información de los snapshots del heap sea más precisa.
Finalmente, ahora que hemos mejorado la fase de generación, el mayor costo ahora está en la fase de serialización. Un análisis adicional podría revelar nuevas oportunidades de optimización en la serialización.
Créditos
Esto fue posible gracias al trabajo de ingenieros de Igalia y Bloomberg.