Acelerando snapshots do heap do V8
Esta postagem no blog foi escrita por José Dapena Paz (Igalia), com contribuições de Jason Williams (Bloomberg), Ashley Claymore (Bloomberg), Rob Palmer (Bloomberg), Joyee Cheung (Igalia) e Shu-yu Guo (Google).
Nesta postagem sobre snapshots do heap do V8, falarei sobre alguns problemas de desempenho encontrados por engenheiros da Bloomberg e como os corrigimos para tornar a análise de memória do JavaScript mais rápida do que nunca.
O problema
Engenheiros da Bloomberg estavam trabalhando no diagnóstico de um vazamento de memória em uma aplicação JavaScript. A aplicação estava falhando com erros de Out-Of-Memory. Para a aplicação testada, o limite do heap do V8 foi configurado para cerca de 1400 MB. Normalmente, o coletor de lixo do V8 deveria ser capaz de manter o uso do heap abaixo desse limite, então as falhas indicavam que provavelmente havia um vazamento.
Uma técnica comum para depurar um cenário de vazamento de memória rotineiro como este é capturar primeiro um snapshot do heap, carregá-lo na aba “Memory” do DevTools e descobrir o que está consumindo mais memória inspecionando os vários resumos e atributos de objetos. Na interface do DevTools, o snapshot do heap pode ser tirado na aba “Memory”. Para aplicações Node.js, o snapshot do heap pode ser acionado programaticamente usando esta API:
require('v8').writeHeapSnapshot();
Eles queriam capturar vários snapshots em diferentes pontos da vida da aplicação, para que o visualizador de memória do DevTools pudesse ser usado para mostrar a diferença entre os heaps em momentos diferentes. O problema era que capturar um único snapshot de tamanho completo (500 MB) estava levando mais de 30 minutos!
Era essa lentidão no fluxo de trabalho de análise de memória que precisávamos resolver.
Restringindo o problema
Então, engenheiros da Bloomberg começaram a investigar o problema usando alguns parâmetros do V8. Conforme descrito nesta postagem, Node.js e V8 têm alguns bons parâmetros de linha de comando que podem ajudar com isso. Essas opções foram usadas para criar os snapshots do heap, simplificar a reprodução e melhorar a observabilidade:
--max-old-space-size=100: Isso limita o heap a 100 megabytes e ajuda a reproduzir o problema muito mais rapidamente.--heapsnapshot-near-heap-limit=10: Este é um parâmetro de linha de comando específico do Node.js que instrui o Node.js a gerar um snapshot toda vez que estiver próximo de ficar sem memória. Ele está configurado para gerar até 10 snapshots no total. Isso evita o desgaste em que o programa com falta de memória passa muito tempo produzindo mais snapshots do que o necessário.--enable-etw-stack-walking: Isso permite que ferramentas como ETW, WPA e xperf vejam a pilha JS que foi chamada no V8. (disponível no Node.js v20+)--interpreted-frames-native-stack: Esse flag é usado em combinação com ferramentas como ETW, WPA e xperf para ver a pilha nativa ao fazer profiling. (disponível no Node.js v20+)
Quando o tamanho do heap do V8 está se aproximando do limite, o V8 força uma coleta de lixo para reduzir o uso de memória. Ele também notifica o incorporador sobre isso. O flag --heapsnapshot-near-heap-limit no Node.js gera um novo snapshot do heap após a notificação. No caso de teste, o uso da memória diminui, mas, após várias iterações, a coleta de lixo acaba não conseguindo liberar espaço suficiente e, assim, a aplicação é encerrada com um erro de Out-Of-Memory.
Eles fizeram gravações utilizando o Windows Performance Analyzer (veja abaixo) a fim de restringir o problema. Isso revelou que a maior parte do tempo da CPU estava sendo gasta dentro do V8 Heap Explorer. Especificamente, levaram cerca de 30 minutos apenas para percorrer o heap, visitar cada nó e coletar o nome. Isso não parecia fazer muito sentido — por que registrar o nome de cada propriedade levaria tanto tempo?
Foi então que me pediram para dar uma olhada.
Quantificando o problema
O primeiro passo foi adicionar suporte no V8 para entender melhor onde o tempo é gasto durante a captura de snapshots do heap. O próprio processo de captura está dividido em duas fases: geração e serialização. Nós enviamos este patch para o upstream para introduzir um novo flag de linha de comando --profile_heap_snapshot ao V8, que permite o registro dos tempos de geração e serialização.
Usando esse flag, aprendemos algumas coisas interessantes!
Primeiro, pudemos observar a quantidade exata de tempo que o V8 estava gastando para gerar cada instantâneo. Em nosso caso de teste reduzido, o primeiro levou 5 minutos, o segundo levou 8 minutos e cada instantâneo subsequente continuava demorando mais e mais. Quase todo esse tempo foi gasto na fase de geração.
Isso também nos permitiu quantificar o tempo gasto na geração de instantâneos com uma sobrecarga trivial, o que nos ajudou a isolar e identificar lentidões semelhantes em outros aplicativos JavaScript amplamente utilizados - em particular, o ESLint no TypeScript. Assim, sabemos que o problema não era específico do aplicativo.
Além disso, descobrimos que o problema ocorria tanto no Windows quanto no Linux. O problema também não era específico da plataforma.
Primeira otimização: melhoria no hash do StringsStorage
Para identificar o que estava causando o atraso excessivo, eu analisei o script com falha usando o Windows Performance Toolkit.
Quando abri a gravação com o Windows Performance Analyzer, foi isso que encontrei:
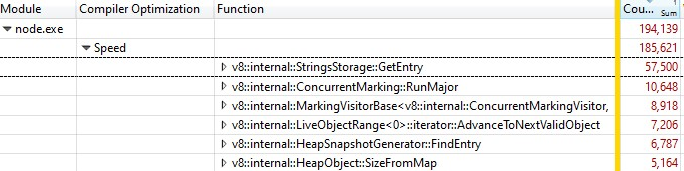
Um terço das amostras foi gasto no v8::internal::StringsStorage::GetEntry:
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
Como isso foi executado com uma versão release, as informações das chamadas de função embutidas foram integradas em StringsStorage::GetEntry(). Para descobrir exatamente quanto tempo as chamadas de funções embutidas estavam levando, adicionei a coluna "Source Line Number" à análise detalhada e descobri que a maior parte do tempo era gasto na linha 182, que era uma chamada para ComputeStringHash():
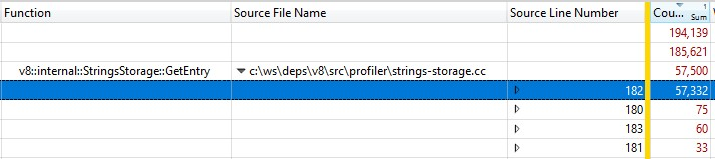
Portanto, mais de 30% do tempo de geração do instantâneo foi gasto no ComputeStringHash(), mas por quê?
Vamos primeiro falar sobre o StringsStorage. Seu propósito é armazenar uma cópia única de todas as strings que serão usadas no instantâneo de heap. Para acesso rápido e evitar duplicatas, esta classe utiliza um hashmap baseado em um array, onde colisões são tratadas armazenando elementos na próxima posição livre no array.
Comecei a suspeitar que o problema poderia ser causado por colisões, o que poderia levar a longas buscas no array. Então adicionei logs exaustivos para ver as chaves hash geradas e, na inserção, verificar quão longe estava da posição esperada calculada a partir da chave hash para a posição real onde a entrada terminou devido a colisões.
Nos logs, as coisas estavam… fora do comum: o deslocamento de muitos itens era superior a 20, e no pior caso, na ordem de milhares!
Parte do problema era causada por strings numéricas — especialmente strings para uma ampla faixa de números consecutivos. O algoritmo de chave hash tinha duas implementações, uma para strings numéricas e outra para outras strings. Enquanto a função de hash para strings era bastante clássica, a implementação para strings numéricas basicamente retornava o valor do número prefixado pelo número de dígitos:
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
Essa função era problemática. Alguns exemplos de problemas com essa função de hash:
- Uma vez que inseríamos uma string cuja chave hash era um número pequeno, enfrentávamos colisões ao tentar armazenar outro número nessa localização, e haveria colisões semelhantes se tentássemos armazenar números subsequentes consecutivamente.
- Ou pior ainda: se já havia muitos números consecutivos armazenados no mapa, e queríamos inserir uma string cuja chave hash estava nessa faixa, tínhamos que mover a entrada por todas as localizações ocupadas para encontrar uma livre.
O que fiz para corrigir isso? Como o problema vem principalmente de números representados como strings que caíam em posições consecutivas, modifiquei a função de hash para que rotacionássemos o valor hash resultante 2 bits para a esquerda.
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
Então, para cada par de números consecutivos, introduzíamos 3 posições livres entre eles. Essa modificação foi escolhida porque testes empíricos em vários conjuntos de trabalho mostraram que ela funcionava melhor para minimizar colisões.
Esta correção de hashing foi implementada no V8.
Segunda otimização: cache de posições de origem
Após corrigir o hashing, reanalisamos e encontramos uma nova oportunidade de otimização que reduziria uma parte significativa da sobrecarga.
Ao gerar um snapshot do heap, para cada função no heap, o V8 tenta registrar sua posição inicial em um par de números de linha e coluna. Essas informações podem ser usadas pelo DevTools para exibir um link para o código fonte da função. Durante a compilação usual, no entanto, o V8 apenas armazena a posição inicial de cada função na forma de um deslocamento linear a partir do início do script. Para calcular os números de linha e coluna com base no deslocamento linear, o V8 precisa percorrer todo o script e registrar onde estão as quebras de linha. Esse cálculo acaba sendo muito oneroso.
Normalmente, após o V8 terminar de calcular os deslocamentos das quebras de linha em um script, ele os armazena em um array alocado recentemente anexado ao script. Infelizmente, a implementação do snapshot não pode modificar o heap ao percorrê-lo, então as informações de linha calculadas recentemente não podem ser armazenadas em cache.
A solução? Antes de gerar o snapshot do heap, agora iteramos por todos os scripts no contexto do V8 para calcular e armazenar em cache os deslocamentos das quebras de linha. Como isso não é feito ao percorrer o heap para a geração do snapshot, ainda é possível modificar o heap e armazenar as posições da linha de origem como um cache.
A correção para o armazenamento em cache de deslocamentos de quebra de linha também foi implementada no V8.
Conseguimos torná-lo rápido?
Após ativar ambas as correções, realizamos um novo perfilamento. Nossas correções afetam apenas o tempo de geração de snapshot, então, como esperado, os tempos de serialização de snapshot não foram afetados.
Ao operar em um programa JS contendo...
- JS em desenvolvimento, o tempo de geração é 50% mais rápido 👍
- JS em produção, o tempo de geração é 90% mais rápido 😮
Por que houve uma diferença tão grande entre o código de produção e o de desenvolvimento? O código de produção é otimizado usando empacotamento e minificação, portanto há menos arquivos JS, e esses arquivos tendem a ser grandes. Leva mais tempo para calcular as posições das linhas de origem para esses arquivos grandes, então eles se beneficiam mais quando podemos armazenar em cache a posição de origem e evitar cálculos repetidos.
As otimizações foram validadas nos ambientes alvo Windows e Linux.
Para o problema particularmente desafiador enfrentado originalmente pelos engenheiros da Bloomberg, o tempo total de ponta a ponta para capturar um snapshot de 100MB foi reduzido de 10 minutos dolorosos para agradáveis 6 segundos. Isso representa uma melhoria de 100×! 🔥
As otimizações são ganhos genéricos que esperamos ser amplamente aplicáveis a qualquer pessoa realizando depuração de memória no V8, Node.js e Chromium. Esses ganhos foram lançados no V8 v11.5.130, o que significa que estão presentes no Chromium 115.0.5576.0. Estamos ansiosos para que o Node.js adote essas otimizações na próxima versão semântico-major.
O que vem a seguir?
Primeiro, seria útil para o Node.js aceitar a nova flag --profile-heap-snapshot em NODE_OPTIONS. Em alguns casos de uso, os usuários não podem controlar diretamente as opções de linha de comando passadas para o Node.js e precisam configurá-las por meio da variável de ambiente NODE_OPTIONS. Hoje, o Node.js filtra opções de linha de comando do V8 definidas na variável de ambiente, permitindo apenas um subconjunto conhecido, o que pode dificultar o teste de novas flags do V8 no Node.js, como aconteceu no nosso caso.
A precisão das informações nos snapshots pode ser ainda mais aprimorada. Hoje, cada linha do código fonte do script é armazenada em uma representação no próprio heap do V8. E isso é um problema porque queremos medir o heap com precisão sem que a sobrecarga de medição de desempenho afete o objeto que estamos observando. Idealmente, armazenaríamos o cache das informações de linha fora do heap do V8 para tornar as informações do snapshot do heap mais precisas.
Por fim, agora que aprimoramos a fase de geração, o maior custo agora é a fase de serialização. Uma análise adicional pode revelar novas oportunidades de otimização na serialização.
Créditos
Isso foi possível graças ao trabalho dos engenheiros da Igalia e da Bloomberg.