2019년 JavaScript 비용
참고: 기사를 읽는 것보다 프레젠테이션을 보는 것을 선호한다면, 아래 영상을 즐겨보세요! 그렇지 않다면, 영상을 건너뛰고 읽어주세요.
지난 몇 년 동안 JavaScript 비용의 주요 변경 사항은 브라우저가 스크립트를 구문 분석하고 컴파일하는 속도의 개선이었습니다. 2019년 현재, 스크립트를 처리하는 주요 비용은 다운로드와 CPU 실행 시간입니다.
브라우저의 메인 스레드가 JavaScript를 실행하는 데 바쁘면 사용자 상호작용이 지연될 수 있으므로 스크립트 실행 시간과 네트워크 병목현상을 최적화하는 것이 영향을 미칠 수 있습니다.
실질적인 고수준 가이드
웹 개발자에게 이것은 무엇을 의미할까요? 구문 분석 및 컴파일 비용이 예전만큼 느리지 않습니다. JavaScript 번들에서 초점을 맞춰야 할 세 가지는 다음과 같습니다:
- 다운로드 시간 개선
- 특히 모바일 장치에서 JavaScript 번들을 작게 유지하세요. 작은 번들은 다운로드 속도를 개선하고 메모리 사용량을 줄이며 CPU 비용을 낮춥니다.
- 단일 대형 번들을 피하세요; 번들이 약 50–100 kB를 초과하면 별도의 작은 번들로 나누세요. (HTTP/2 멀티플렉싱을 사용하면 여러 요청 및 응답 메시지가 동시에 진행될 수 있어 추가 요청에 대한 오버헤드를 줄일 수 있습니다.)
- 모바일에서는 특히 네트워크 속도뿐만 아니라 순수 메모리 사용량을 낮게 유지해야 하므로 훨씬 적게 전달해야 합니다.
- 실행 시간 개선
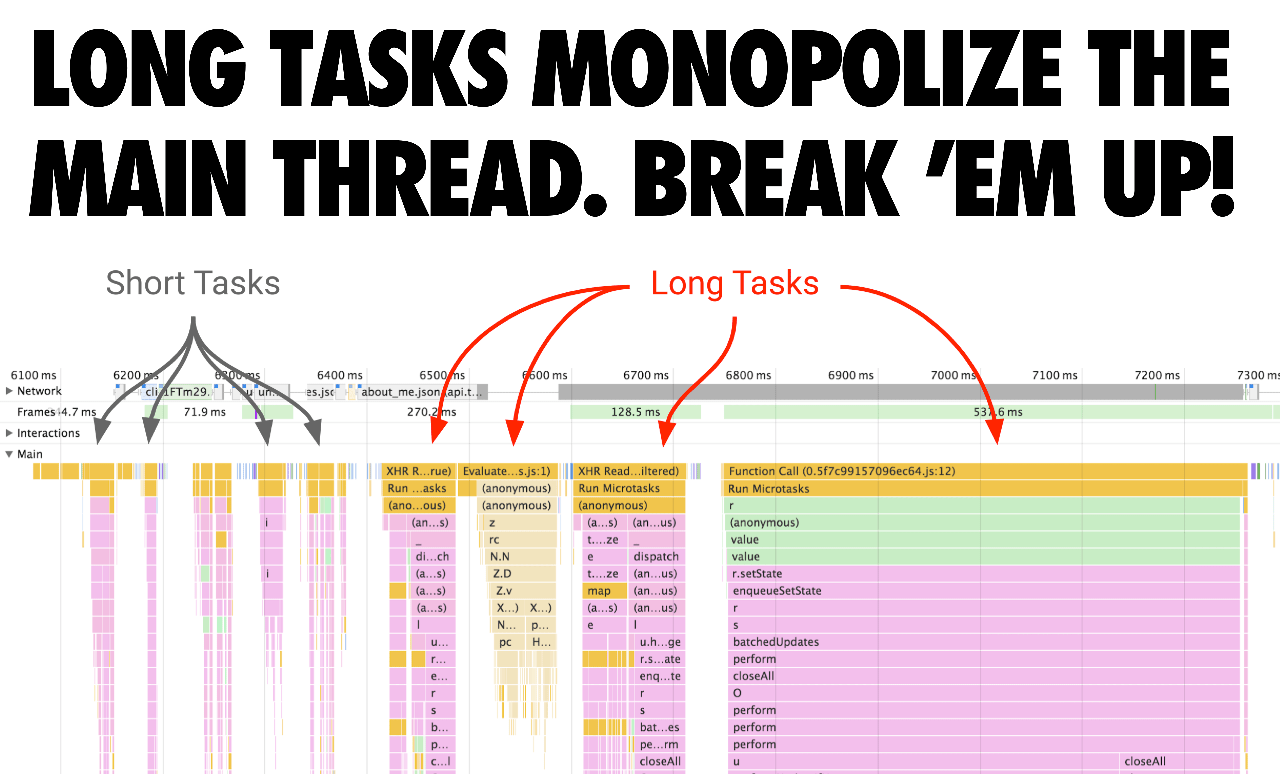
- Long Tasks를 피하세요. 이는 메인 스레드를 바쁘게 유지하여 페이지 상호작용을 늦출 수 있습니다. 다운로드 후 스크립트 실행 시간은 이제 주요 비용입니다.
- 큰 인라인 스크립트 피하기 (메인 스레드에서 여전히 구문 분석되고 컴파일되기 때문임). 좋은 경험법은: 스크립트가 1 kB를 초과하는 경우 인라인화를 피하는 것입니다. (외부 스크립트에서도 1 kB는 코드 캐싱이 시작되는 크기입니다.)
다운로드와 실행 시간이 왜 중요할까요?
다운로드와 실행 시간을 최적화하는 것이 왜 중요할까요? 다운로드 시간은 저속 네트워크 환경에서 매우 중요합니다. 전 세계에서 4G(심지어 5G)의 성장이 있었음에도 불구하고, 우리의 실효 연결 유형은 여전히 일관되지 않으며, 이동 중일 때는 3G(또는 그 이하)같이 느껴지는 속도를 경험할 때가 많습니다.
JavaScript 실행 시간은 느린 CPU를 가진 휴대전화에 중요합니다. CPU, GPU 및 열 스로틀링의 차이로 인해 고급 및 저가형 휴대전화 사이의 성능에 큰 차이가 존재합니다. 이는 JavaScript 성능에 중요하며, 실행은 CPU에 의존합니다.
실제로 Chrome 등 브라우저에서 페이지 로딩에 소비된 총 시간 중 최대 30%가 JavaScript 실행에 소비될 수 있습니다. 아래는 고급 데스크톱 기기에서 꽤 일반적인 작업 부하(Reddit.com)를 가진 사이트의 페이지 로드입니다:

모바일에서는 평균 기기(Moto G4)가 Reddit의 JavaScript를 실행하는 데 고급 기기(Pixel 3)보다 3–4배 더 오래 걸리고, 저가형 기기(<$100 알카텔 1X)에서는 6배 이상 더 오래 걸립니다:

참고: Reddit은 데스크톱과 모바일 웹에 대해 다른 경험을 제공하므로 MacBook Pro 결과는 다른 결과와 비교할 수 없습니다.
JavaScript 실행 시간을 최적화하려고 할 때, UI 스레드를 오랜 시간 독점할 가능성이 있는 Long Tasks에 주목하세요. 이러한 작업은 페이지가 시각적으로 준비된 것처럼 보여도 중요한 작업의 실행을 방해할 수 있습니다. 이를 더 작은 작업으로 나누세요. 코드를 분리하고 로드 순서를 우선순위화함으로써 페이지가 더 빠르게 상호작용할 수 있게 하고 입력 지연 시간을 줄일 수 있습니다.
V8은 파싱/컴파일을 개선하기 위해 무엇을 했나요?
V8의 순수 JavaScript 파싱 속도는 Chrome 60 이후로 2배 증가했습니다. 동시에 다른 최적화 작업 덕분에 순수 파싱(및 컴파일) 비용은 덜 보이거나 중요성이 낮아졌습니다. 이 작업은 병렬화가 이루어졌습니다.
V8은 작업자 스레드에서 파싱 및 컴파일을 수행함으로써 주요 스레드에서의 파싱 및 컴파일 작업량을 평균 40% 줄였습니다(Facebook에서 46%, Pinterest에서 62%, 최대 81% 개선은 YouTube에서 이루어짐). 이는 기존의 주요 스레드 외부 스트리밍 파싱/컴파일에 추가된 작업입니다.

V8의 이러한 변경 사항이 Chrome 릴리스 간의 CPU 시간에 미친 영향을 시각화할 수 있습니다. Chrome 61이 Facebook의 JS를 파싱하는 데 걸린 시간 동안, Chrome 75는 Facebook의 JS와 Twitter의 JS를 6배 더 파싱할 수 있습니다.

이러한 변경 사항이 어떻게 가능한지 자세히 살펴보겠습니다. 간단히 말하면 스크립트 리소스는 작업자 스레드에서 스트리밍 방식으로 파싱 및 컴파일될 수 있습니다. 이는 다음을 의미합니다:
- V8은 주요 스레드를 차단하지 않고 JavaScript를 파싱+컴파일할 수 있습니다.
- 스트리밍은 전체 HTML 파서가
<script>태그를 만나면 시작됩니다. 파서 차단 스크립트의 경우 HTML 파서는 대기하며, 비동기 스크립트의 경우 계속 진행됩니다. - 대부분의 실제 네트워크 속도에서는 V8이 다운로드보다 빠르게 파싱하므로 마지막 스크립트 바이트가 다운로드된 후 몇 밀리초 안에 파싱+컴파일을 완료합니다.
좀 더 자세한 설명은… 훨씬 오래된 Chrome 버전에서는 스크립트를 전부 다운로드한 후 파싱을 시작했는데, 이는 직관적인 접근 방식이지만 CPU를 완전히 활용하지는 않습니다. 41과 68 버전 사이의 Chrome에서는 다운로드가 시작되자마자 비동기 및 연기된 스크립트를 별도의 스레드에서 파싱하기 시작했습니다.

Chrome 71에서는 스케줄러가 여러 비동기/연기된 스크립트를 한 번에 파싱할 수 있는 태스크 기반 설정으로 전환했습니다. 이 변경의 영향으로 주요 스레드 파싱 시간이 약 20% 감소하여 실제 웹사이트에서 TTI/FID가 약 2% 개선되었습니다.

Chrome 72에서는 스트리밍을 주요 파싱 방법으로 사용하기로 전환하였습니다. 이제 일반 동기 스크립트도 이 방식으로 파싱되며(인라인 스크립트 제외), 주요 스레드가 필요한 경우 태스크 기반 파싱을 취소하지 않도록 했습니다. 이는 이미 수행된 작업을 불필요하게 중복하지 않기 위해서입니다.
이전 Chrome 버전에서는 네트워크에서 들어오는 스크립트 소스 데이터가 Chrome의 주요 스레드로 이동한 후 스트리머로 전달되기 전까지 스트리밍 파싱 및 컴파일을 지원했었습니다.
이는 종종 네트워크에서 이미 도착했지만 주요 스레드에서 다른 작업(예: HTML 파싱, 레이아웃 또는 JavaScript 실행)으로 인해 스트리밍 작업에 전달되지 못해 데이터가 부족하여 스트리밍 파서가 기다리는 상황을 초래했습니다.
우리는 이제 프리로드 시 파싱 시작을 실험하고 있으며, 주요 스레드로의 이동이 이전에는 이를 방해하는 요소였습니다.
Leszek Swirski의 BlinkOn 프레젠테이션에서는 더 자세히 설명합니다:
이러한 변경 사항은 DevTools에서 어떻게 반영되나요?
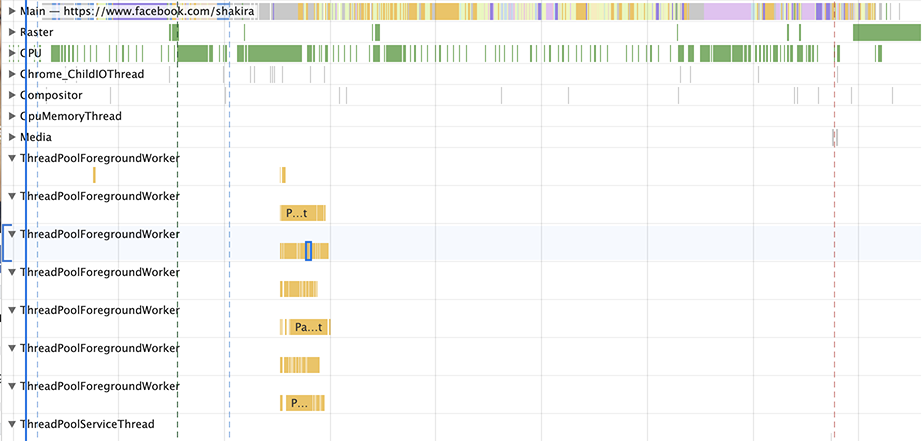
위 내용 외에도, DevTools에서 전체 파서 작업을 CPU를 사용하고 있는 것처럼 보이게 표시하는 문제가 있었습니다(전체 블록). 그러나 파서는 데이터가 부족하면 차단되며(주요 스레드를 통해 이동해야 하는 데이터), 단일 스트리머 스레드에서 스트리밍 태스크로 전환한 이후로 이 문제가 더욱 명확해졌습니다. Chrome 69에서 보던 모습은 다음과 같습니다:

"스크립트 분석" 작업은 1.08초가 걸리는 것으로 표시됩니다. 그러나 자바스크립트 분석은 실제로 그렇게 느리지 않습니다! 대부분의 시간은 메인 스레드를 통해 데이터를 전달하는 것을 기다리며 아무것도 하지 않고 소요됩니다.
Chrome 76에서는 다른 그림을 보여줍니다:
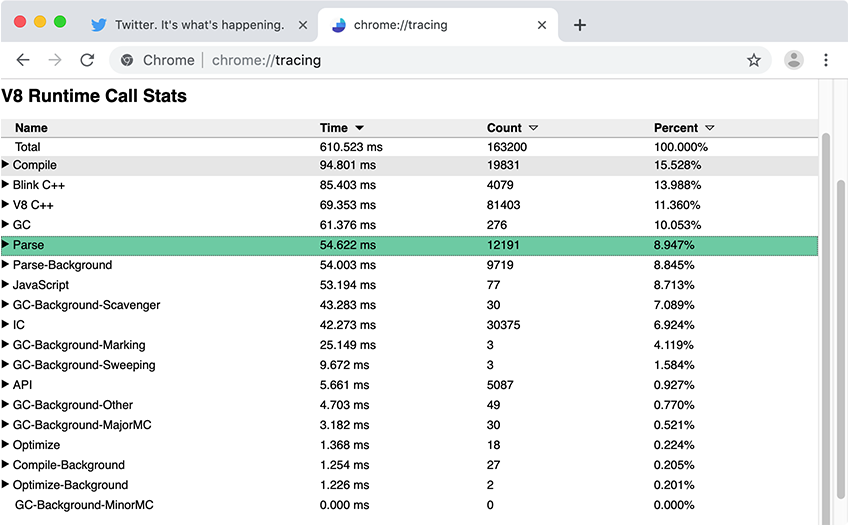
일반적으로 DevTools 성능 패널은 페이지에서 발생하고 있는 작업의 하이레벨 개요를 파악하는 데 훌륭합니다. 자바스크립트 분석 및 컴파일 시간과 같은 V8-특정 세부 메트릭을 얻으려면 Runtime Call Stats(RCS)와 Chrome Tracing을 사용하는 것을 추천합니다. RCS 결과에서 Parse-Background와 Compile-Background는 메인 스레드 밖에서 자바스크립트를 분석하고 컴파일하는 데 소요된 시간을 나타내며, Parse와 Compile은 메인 스레드에서의 메트릭을 캡쳐합니다.
이러한 변화가 실제로 미치는 영향은 무엇인가요?
실제 웹사이트에 대한 몇 가지 사례를 살펴보고 스트리밍 스크립트가 어떻게 적용되는지 확인해 보겠습니다.

Reddit.com은 외부 함수 안에 감싸진 수백 kB 이상의 번들을 포함하고 있어 메인 스레드에서 많은 지연 컴파일이 발생합니다. 위의 차트에서, 메인 스레드 시간은 실제로 중요하므로 메인 스레드가 바쁜 경우 상호 작용이 지연될 수 있습니다. Reddit은 워커/백그라운드 스레드의 최소 사용으로 메인 스레드에서 대부분의 시간을 소비합니다.
더 큰 번들을 작은 번들(예: 각각 50kB)로 분할하고 래핑을 제거하여 병렬화를 최대화하는 것이 도움이 될 것입니다. 이렇게 하면 각 번들이 독립적으로 스트리밍 분석 및 컴파일되고 시작 시 메인 스레드 분석/컴파일을 줄일 수 있습니다.

Facebook.com과 같은 웹사이트도 살펴볼 수 있습니다. Facebook은 ~6MB 압축된 JS를 ~292개의 요청에 걸쳐 불러옵니다. 일부는 비동기적, 일부는 미리 로드, 일부는 낮은 우선순위로 가져옵니다. 많은 스크립트가 매우 작고 세분화되어 있어 백그라운드/워커 스레드의 전체 병렬화에 도움이 될 수 있습니다. 이러한 작은 스크립트는 동시에 스트리밍 분석/컴파일될 수 있습니다.
참고로, 여러분은 아마도 Facebook처럼 데스크톱에서 많은 스크립트가 정당화될 수 있는 장기간 성공적인 앱(Facebook 또는 Gmail 등)을 가지고 있지 않을 것입니다. 일반적으로 번들을 조잡하게 유지하고 필요한 것만 불러오십시오.
대부분의 자바스크립트 분석 및 컴파일 작업은 백그라운드 스레드에서 스트리밍 방식으로 수행될 수 있지만 일부 작업은 여전히 메인 스레드에서 수행되어야 합니다. 메인 스레드가 바쁘면 페이지가 사용자 입력에 응답할 수 없습니다. 다운로드 및 코드 실행이 UX에 미치는 영향을 주시하세요.
참고: 현재 모든 자바스크립트 엔진 및 브라우저가 로드 최적화로 스크립트 스트리밍을 구현하는 것은 아닙니다. 그러나 여기서 제공하는 전반적인 지침은 전반적으로 좋은 사용자 경험을 지원한다고 믿습니다.
JSON 구문 분석의 비용
JSON 문법은 자바스크립트 문법보다 훨씬 간단하기 때문에 JSON은 자바스크립트보다 효율적으로 분석할 수 있습니다. 이 지식은 큰 JSON과 유사한 구성 객체 리터럴(예: 인라인 Redux 저장소)을 전달하는 웹 앱의 시작 성능을 개선하는 데 적용할 수 있습니다. 데이터를 자바스크립트 객체 리터럴로 인라인하지 않고 다음과 같이 표현할 수 있습니다:
const data = { foo: 42, bar: 1337 }; // 🐌
…JSON-문자열화된 형식으로 표현하고 실행 시 JSON-파싱할 수 있습니다:
const data = JSON.parse('{"foo":42,"bar":1337}'); // 🚀
JSON.parse 접근법은 특히 냉로드에서 자바스크립트 객체 리터럴에 비해 훨씬 빠릅니다. 일반적인 규칙은 객체가 10kB 이상인 경우 이 기술을 적용하는 것이지만, 항상 성능 조언에 따라 변경하기 전에 실제 영향을 측정하십시오.

다음 비디오는 02:10 지점부터 성능 차이가 발생하는 이유를 더 자세히 설명합니다.
JSON.parse를 사용한 빠른 앱" - Mathias Bynens가 #ChromeDevSummit 2019에서 발표.JSON ⊂ ECMAScript 기능 설명서를 참고해주세요. 이를 통해 임의의 객체를 받아 적합한 JavaScript 프로그램을 생성하여 JSON.parse를 실행합니다.
큰 데이터량을 처리하면서 단순 객체 리터럴을 사용할 때 추가적인 위험이 있습니다: 데이터가 두 번 파싱될 수 있습니다!
- 첫 번째 파스는 리터럴이 사전 파싱될 때 발생합니다.
- 두 번째 파스는 리터럴이 지연 파싱될 때 발생합니다.
첫 번째 파스는 피할 수 없습니다. 하지만 다행히도 두 번째 파스는 객체 리터럴을 최상위 위치에 놓거나 PIFE와 함께 사용할 경우 피할 수 있습니다.
반복 방문 시 파싱/컴파일은 어떻게 되나요?
V8의 (바이트)코드 캐싱 최적화가 도움이 될 수 있습니다. 스크립트가 처음 요청되면, Chrome은 이를 다운로드하여 V8에 전달하여 컴파일합니다. 또한, 파일을 브라우저의 디스크 캐시에 저장합니다. JS 파일이 두 번째로 요청되면, Chrome은 브라우저 캐시에서 파일을 가져와 다시 V8에 전달하여 컴파일을 수행합니다. 이때, 컴파일된 코드가 직렬화되어 메타데이터로 캐시된 스크립트 파일에 첨부됩니다.
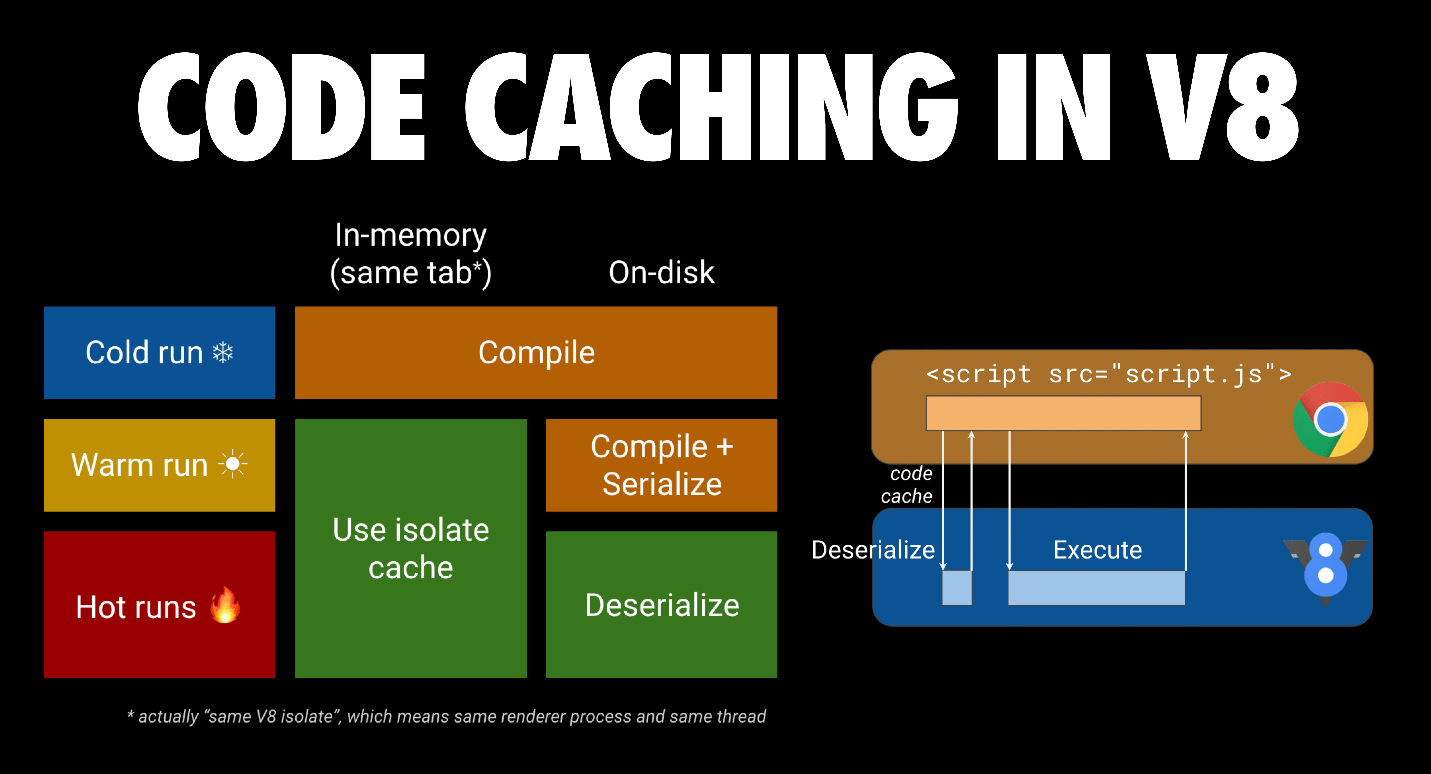
세 번째 요청에서는, Chrome이 캐시에서 파일과 메타데이터를 모두 가져와 V8에 전달합니다. V8은 메타데이터를 역직렬화하여 컴파일을 생략할 수 있습니다. 초기 두 번의 방문이 72시간 내에 발생하면 코드 캐싱이 작동합니다. Chrome은 서비스 워커를 사용하여 스크립트를 캐시할 경우 이른 코드 캐싱도 제공할 수 있습니다. 자세한 내용은 웹 개발자를 위한 코드 캐싱을 읽어보세요.
결론
다운로드 시간과 실행 시간은 2019년 스크립트를 로드하는 데 있어 주요 병목 현상입니다. 페이지 상단 콘텐츠를 위한 동기화(인라인) 스크립트의 작은 번들을 목표로 하고, 나머지 페이지를 위한 하나 이상의 지연된 스크립트를 선택하세요. 사용자 필요에 따라 필요한 코드만 제공하도록 큰 번들을 나누세요. 이는 V8에서 병렬 처리를 극대화하는 데 도움이 됩니다.
모바일에서는 네트워크, 메모리 소비 및 느린 CPU의 실행 시간 때문에 더 적은 스크립트를 제공해야 합니다. 캐시 가능성을 통해 대기 시간을 조정하여 주 스레드 외부에서 발생할 수 있는 파싱과 컴파일 작업을 극대화하세요.