Couverture de code JavaScript
La couverture de code fournit des informations sur si, et éventuellement à quelle fréquence, certaines parties d'une application ont été exécutées. Elle est couramment utilisée pour déterminer dans quelle mesure une suite de tests examine une base de code particulière.
Pourquoi est-ce utile ?
En tant que développeur JavaScript, vous pouvez souvent vous retrouver dans une situation où la couverture de code pourrait être utile. Par exemple :
- Intéressé par la qualité de votre suite de tests ? Refactoriser un grand projet hérité ? La couverture de code peut vous montrer exactement quelles parties de votre base de code sont couvertes.
- Vous voulez savoir rapidement si une partie particulière de la base de code est atteinte ? Au lieu d'instrumenter avec
console.logpour un debugging de styleprintfou de passer manuellement à travers le code, la couverture de code peut afficher des informations en direct sur quelles parties de vos applications ont été exécutées. - Ou peut-être optimisez-vous pour la vitesse et aimeriez savoir sur quels endroits focaliser ? Les comptes d'exécution peuvent pointer les fonctions et boucles importantes.
Couverture de code JavaScript dans V8
Plus tôt cette année, nous avons ajouté une prise en charge native de la couverture de code JavaScript dans V8. La version initiale en version 5.9 a fourni une couverture à granularité fonctionnelle (montrant quelles fonctions ont été exécutées), qui a ensuite été étendue pour prendre en charge une couverture à granularité de bloc dans la v6.2 (de même, mais pour des expressions individuelles).
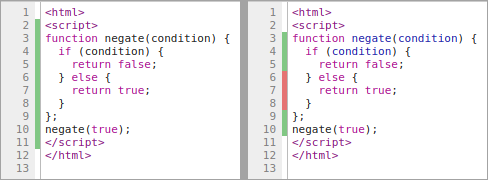
Pour les développeurs JavaScript
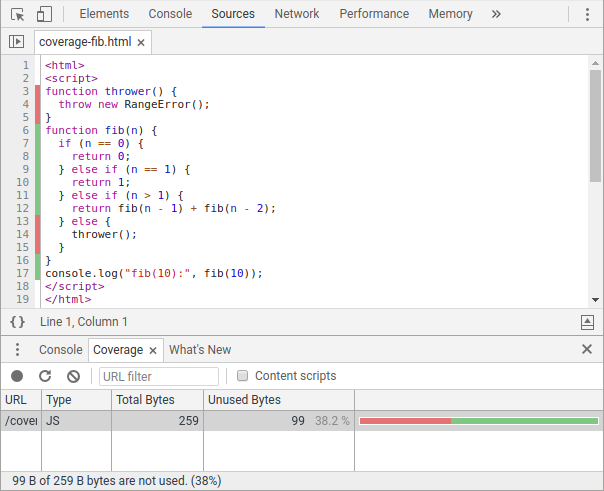
Il existe actuellement deux principales façons d'accéder aux informations de couverture. Pour les développeurs JavaScript, l'onglet Couverture des DevTools de Chrome expose les rapports de couverture JS (et CSS) et met en surbrillance le code mort dans le panneau Sources.
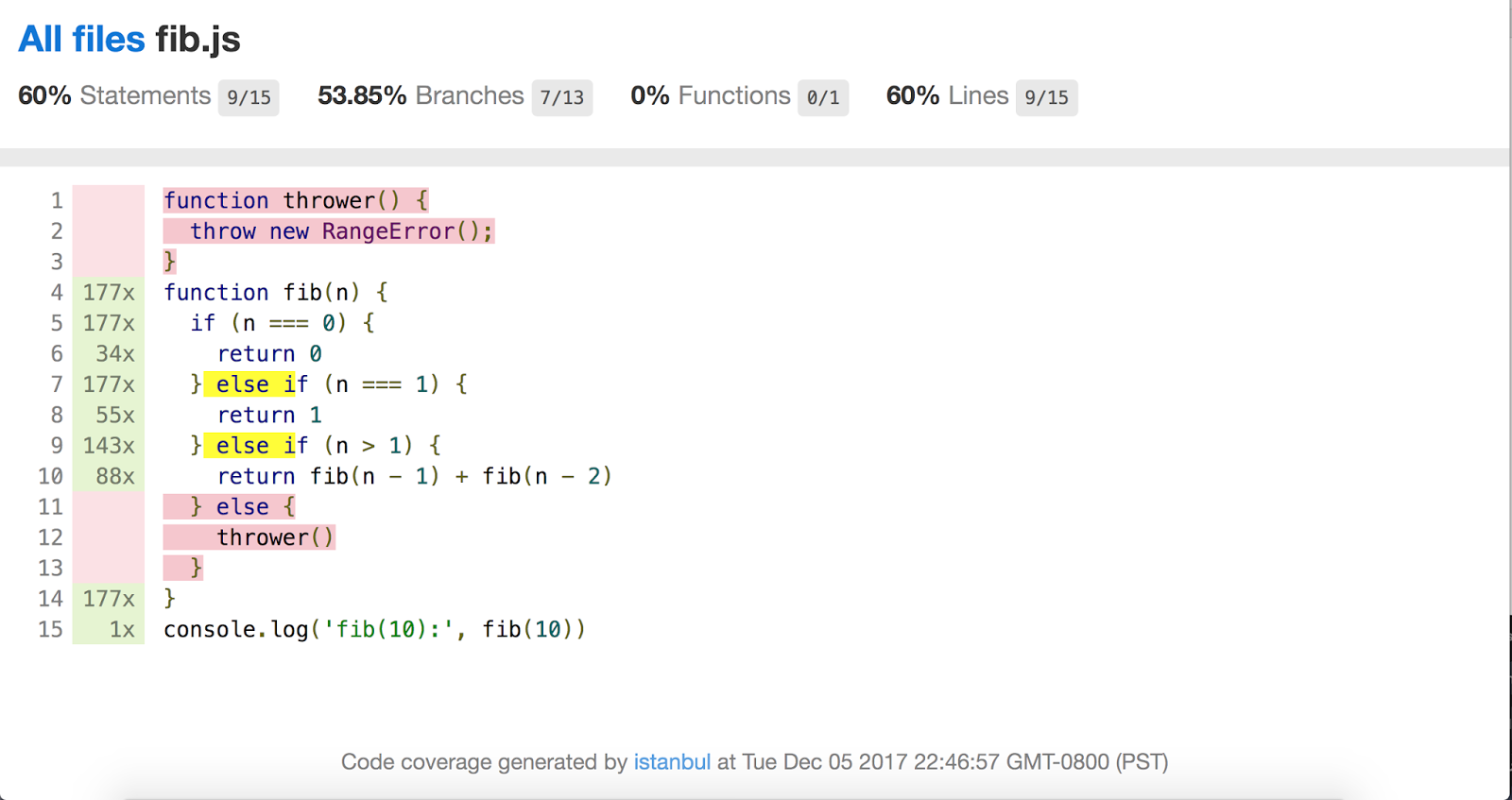
Grâce à Benjamin Coe, un travail en cours vise à intégrer les informations de couverture de code de V8 dans l'outil populaire de couverture de code Istanbul.js.
Pour les intégrateurs
Les intégrateurs et les auteurs de frameworks peuvent se connecter directement à l'API Inspector pour plus de flexibilité. V8 offre deux modes de couverture différents :
-
Couverture approximative collecte des informations de couverture avec un impact minimal sur les performances d'exécution, mais peut perdre des données sur les fonctions collectées par le garbage collector (GC).
-
Couverture précise garantit qu'aucune donnée n'est perdue à cause du GC, et les utilisateurs peuvent choisir de recevoir des comptes d'exécution au lieu d'informations de couverture binaires ; mais les performances peuvent être impactées par une surcharge accrue (voir la section suivante pour plus de détails). La couverture précise peut être collectée soit à granularité fonctionnelle, soit à granularité de bloc.
L'API Inspector pour la couverture précise est la suivante :
-
Profiler.startPreciseCoverage(callCount, detailed)active la collection de couverture, éventuellement avec des comptes d'appel (contre une couverture binaire) et une granularité de bloc (contre une granularité fonctionnelle) ; -
Profiler.takePreciseCoverage()retourne les informations de couverture collectées sous forme de liste de plages sources avec les comptes d'exécution associés ; et -
Profiler.stopPreciseCoverage()désactive la collection et libère les structures de données associées.
Une conversation via le protocole Inspector pourrait ressembler à ceci :
// L'intégrateur dirige V8 pour commencer à collecter une couverture précise.
{ "id": 26, "method": "Profiler.startPreciseCoverage",
"params": { "callCount": false, "detailed": true }}
// L'intégrateur demande les données de couverture (delta depuis la dernière requête).
{ "id": 32, "method":"Profiler.takePreciseCoverage" }
// La réponse contient une collection de plages sources imbriquées.
{ "id": 32, "result": { "result": [{
"functions": [
{
"functionName": "fib",
"isBlockCoverage": true, // Granularité de bloc.
"ranges": [ // Un tableau de plages imbriquées.
{
"startOffset": 50, // Offset en octets, inclus.
"endOffset": 224, // Offset en octets, exclus.
"count": 1
}, {
"startOffset": 97,
"endOffset": 107,
"compte": 0
}, {
"débutDécalage": 134,
"finDécalage": 144,
"compte": 0
}, {
"débutDécalage": 192,
"finDécalage": 223,
"compte": 0
},
]},
"idScript": "199",
"url": "file:///coverage-fib.html"
}
]
}}
// Enfin, l'implémenteur dirige V8 pour terminer la collecte et
// libérer les structures de données associées.
{"id":37,"méthode":"Profiler.stopPreciseCoverage"}
De même, la couverture approximative peut être récupérée à l'aide de Profiler.getBestEffortCoverage().
Dans les coulisses
Comme indiqué dans la section précédente, V8 prend en charge deux modes principaux de couverture de code : couverture approximative et couverture précise. Continuez pour un aperçu de leur mise en œuvre.
Couverture approximative
Les modes couverture approximative et couverture précise réutilisent largement d'autres mécanismes de V8, dont le premier est appelé compteur d'invocations. Chaque fois qu'une fonction est appelée via l'interpréteur Ignition de V8, nous incrémentons un compteur d'invocation sur le vecteur de feedback de la fonction. Lorsque la fonction devient populaire et s'améliore grâce au compilateur d'optimisation, ce compteur est utilisé pour guider les décisions d'inlining concernant quelles fonctions doivent être inline; et maintenant, nous nous appuyons également dessus pour signaler la couverture de code.
Le second mécanisme réutilisé détermine l'étendue source des fonctions. Lors du signalement de la couverture de code, les comptes d'invocation doivent être liés à une plage associée dans le fichier source. Par exemple, dans l'exemple ci-dessous, nous devons non seulement signaler que la fonction f a été exécutée exactement une fois, mais également que l'étendue source de f commence à la ligne 1 et se termine à la ligne 3.
function f() {
console.log('Bonjour le Monde');
}
f();
Encore une fois, nous avons eu de la chance et avons pu réutiliser des informations existantes dans V8. Les fonctions connaissaient déjà leur position de début et de fin dans le code source grâce à Function.prototype.toString, qui doit connaître l'emplacement de la fonction dans le fichier source pour extraire la sous-chaîne appropriée.
Lors de la collecte de la couverture approximative, ces deux mécanismes sont simplement liés : nous trouvons d'abord toutes les fonctions en vie en parcourant l'intégralité du tas. Pour chaque fonction vue, nous rapportons le compte d'invocation (stocké sur le vecteur de feedback, que nous pouvons atteindre à partir de la fonction) et l'étendue source (commodément stockée sur la fonction elle-même).
Notez que puisque les comptes d'invocations sont maintenus indépendamment du fait que la couverture soit activée ou non, la couverture approximative n'introduit aucun surcoût à l'exécution. Elle n'utilise également pas de structures de données dédiées et n'a donc pas besoin d'être explicitement activée ou désactivée.
Alors pourquoi ce mode est-il appelé approximatif, quels sont ses limitations ? Les fonctions qui sortent de la portée peuvent être libérées par le ramasse-miettes. Cela signifie que les comptes d'invocation associés sont perdus et, en fait, nous oublions complètement que ces fonctions ont jamais existé. D'où le terme « approximatif » : même si nous faisons de notre mieux, les informations de couverture collectées peuvent être incomplètes.
Couverture précise (granularité de fonction)
Contrairement au mode approximatif, la couverture précise garantit que les informations de couverture fournies sont complètes. Pour y parvenir, nous ajoutons tous les vecteurs de feedback à l'ensemble racine des références de V8 une fois que la couverture précise est activée, empêchant leur collecte par le GC. Bien que cela garantisse qu'aucune information ne soit perdue, cela augmente la consommation de mémoire en maintenant artificiellement les objets en vie.
Le mode de couverture précise peut également fournir des comptes d'exécution. Cela complique encore la mise en œuvre de la couverture précise. Rappelez-vous que le compteur d'invocations est incrémenté chaque fois qu'une fonction est appelée via l'interpréteur de V8, et que les fonctions peuvent devenir plus efficaces et être optimisées lorsqu'elles deviennent populaires. Mais les fonctions optimisées n'incrémentent plus leur compteur d'invocations, et donc le compilateur d'optimisation doit être désactivé pour que le compte d'exécution signalé reste précis.
Couverture précise (granularité de bloc)
La couverture à granularité de bloc doit signaler une couverture correcte jusqu'au niveau des expressions individuelles. Par exemple, dans le code ci-dessous, la couverture de bloc pourrait détecter que la branche else de l'expression conditionnelle : c n'est jamais exécutée, tandis qu'une couverture à granularité de fonction ne saurait que la fonction f (dans son intégralité) est couverte.
function f(a) {
return a ? b : c;
}
f(true);
Vous vous souvenez peut-être des sections précédentes que nous avions déjà des décomptes d'invocations de fonctions et des plages de code source facilement disponibles dans V8. Malheureusement, ce n'était pas le cas pour la couverture des blocs, et nous avons dû mettre en œuvre de nouveaux mécanismes pour collecter à la fois les décomptes d'exécution et leurs plages de code source correspondantes.
Le premier aspect concerne les plages de code source : supposons que nous avons un décompte d'exécution pour un bloc particulier, comment pouvons-nous les associer à une section du code source ? Pour cela, nous devons collecter les positions pertinentes lors de l'analyse des fichiers source. Avant la couverture des blocs, V8 faisait cela dans une certaine mesure. Un exemple est la collecte des plages de fonctions en raison de Function.prototype.toString, comme décrit ci-dessus. Un autre exemple est l'utilisation des positions de code source pour construire la pile d'appels pour les objets erreurs. Mais aucun de ces cas n'est suffisant pour supporter la couverture des blocs ; le premier n'est disponible que pour les fonctions, tandis que le second ne stocke que des positions (par exemple, la position du mot-clé if pour les instructions if-else), et non des plages de code source.
Nous avons donc dû étendre l'analyseur pour collecter les plages de code source. Pour illustrer, considérons une instruction if-else :
if (cond) {
/* Branche "then". */
} else {
/* Branche "else". */
}
Lorsque la couverture des blocs est activée, nous collectons la plage de code source des branches then et else et les associons au nœud AST IfStatement analysé. La même chose est faite pour d'autres constructions du langage pertinentes.
Après la collecte des plages de code source lors de l'analyse, le deuxième aspect concerne le suivi des décomptes d'exécution à l'exécution. Cela est accompli en insérant un nouvel opcode dédié IncBlockCounter à des positions stratégiques dans le tableau d'octets de code généré. À l'exécution, le gestionnaire d'opcode IncBlockCounter incrémente simplement le compteur approprié (accessible via l'objet fonction).
Dans l'exemple ci-dessus d'une instruction if-else, de tels opcodes seraient insérés à trois endroits : immédiatement avant le corps de la branche then, avant le corps de la branche else, et immédiatement après l'instruction if-else (ces compteurs de continuation sont nécessaires en raison de la possibilité de contrôles non locaux dans une branche).
Enfin, le rapport de couverture à granularité de bloc fonctionne de manière similaire au rapport à granularité de fonction. Mais en plus des décomptes d'invocations (à partir du vecteur de rétroaction), nous rapportons maintenant également la collection de plages de code source intéressantes avec leurs décomptes de bloc (stockés dans une structure de données auxiliaire attachée à la fonction).
Si vous souhaitez en savoir plus sur les détails techniques de la couverture de code dans V8, consultez les documents de conception sur la couverture et la couverture des blocs.
Conclusion
Nous espérons que vous avez apprécié cette brève introduction au support natif de la couverture de code de V8. N'hésitez pas à l'essayer et à nous faire savoir ce qui fonctionne pour vous, et ce qui ne fonctionne pas. Dites bonjour sur Twitter (@schuay et @hashseed) ou signalez un bug sur crbug.com/v8/new.
Le support de couverture dans V8 a été un effort d'équipe, et des remerciements s'imposent à tous ceux qui ont contribué : Benjamin Coe, Jakob Gruber, Yang Guo, Marja Hölttä, Andrey Kosyakov, Alexey Kozyatinksiy, Ross McIlroy, Ali Sheikh, Michael Starzinger. Merci !