Cobertura de código JavaScript
A cobertura de código fornece informações sobre se, e opcionalmente com que frequência, certas partes de uma aplicação foram executadas. É comumente usada para determinar quão bem um conjunto de testes avalia uma base de código específica.
Por que isso é útil?
Como desenvolvedor JavaScript, você pode frequentemente se encontrar em situações onde a cobertura de código pode ser útil. Por exemplo:
- Interessado na qualidade do seu conjunto de testes? Refatorando um grande projeto legado? A cobertura de código pode mostrar exatamente quais partes da sua base de código estão cobertas.
- Gostaria de saber rapidamente se uma parte específica da base de código foi alcançada? Em vez de instrumentar com
console.logpara depuração estiloprintfou passar manualmente pelo código, a cobertura de código pode exibir informações ao vivo sobre quais partes de suas aplicações foram executadas. - Ou talvez você esteja otimizando para desempenho e gostaria de saber onde se concentrar? Contagens de execução podem apontar funções e loops mais usados.
Cobertura de código JavaScript no V8
No início deste ano, adicionamos suporte nativo para cobertura de código JavaScript ao V8. O lançamento inicial na versão 5.9 forneceu cobertura em granularidade de função (mostrando quais funções foram executadas), que posteriormente foi estendido para suportar cobertura em granularidade de bloco na versão 6.2 (da mesma forma, mas para expressões individuais).
Para desenvolvedores JavaScript
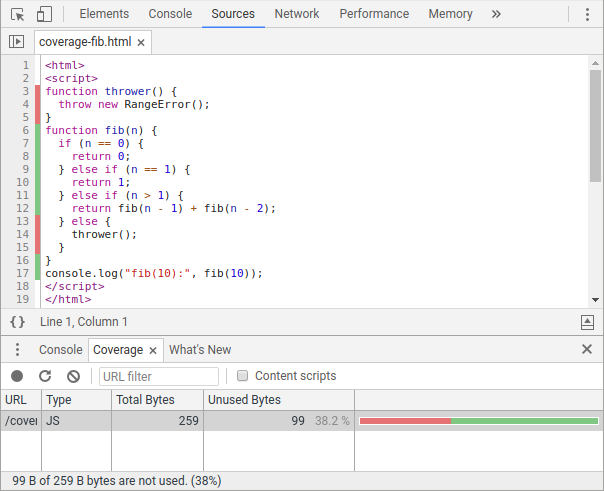
Atualmente, existem duas maneiras principais de acessar informações de cobertura. Para desenvolvedores JavaScript, a aba Coverage do Chrome DevTools expõe razões de cobertura de JS (e CSS) e destaca código morto no painel Sources.
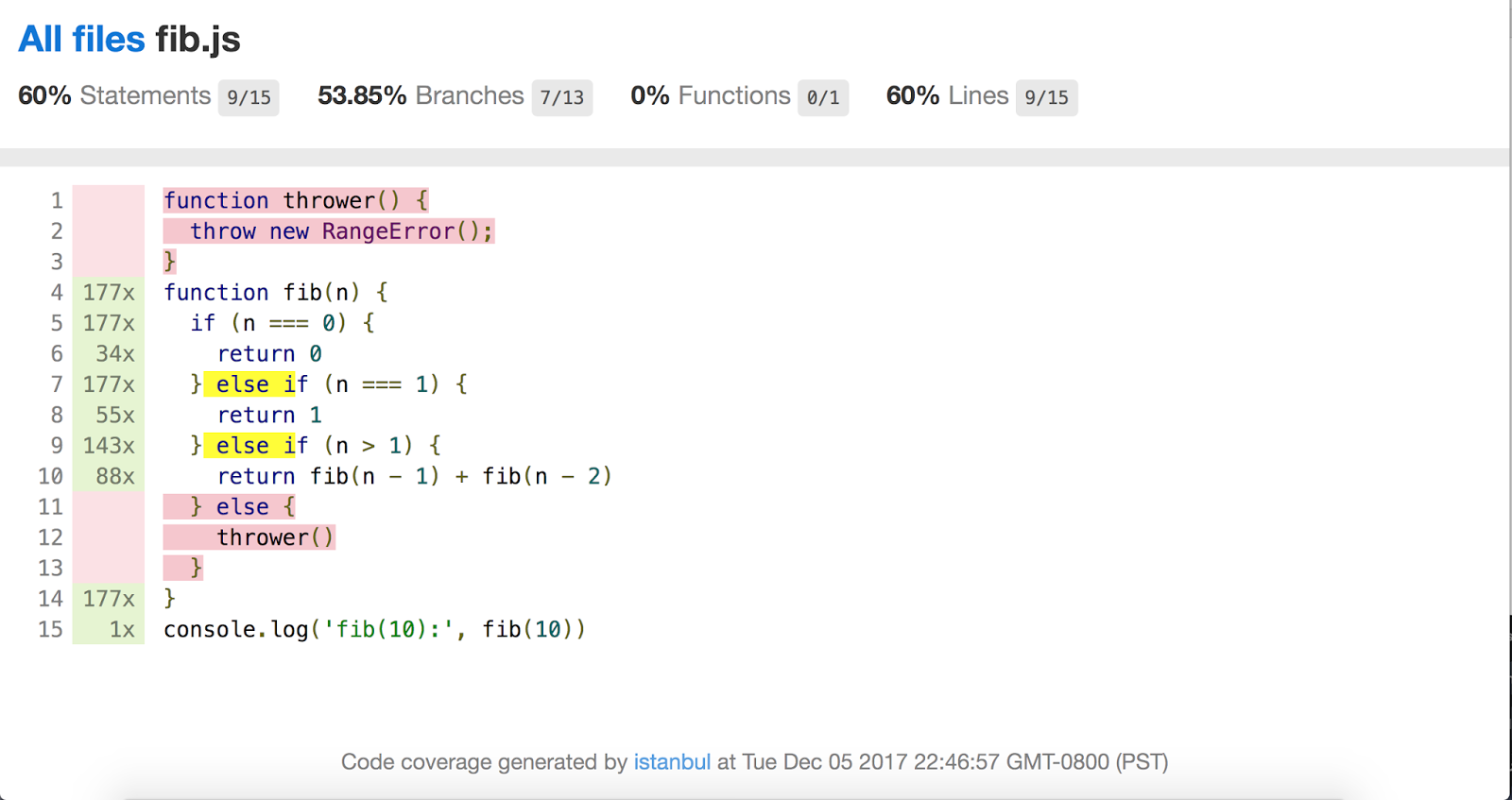
Graças a Benjamin Coe, há também trabalho em andamento para integrar as informações de cobertura de código do V8 na popular ferramenta de cobertura Istanbul.js.
Para integradores
Integradores e autores de frameworks podem se conectar diretamente à API do Inspector para mais flexibilidade. O V8 oferece dois modos diferentes de cobertura:
-
Cobertura de melhor esforço coleta informações de cobertura com impacto mínimo no desempenho em tempo de execução, mas pode perder dados de funções coletadas pelo garbage collector (GC).
-
Cobertura precisa garante que nenhum dado seja perdido para o GC, e os usuários podem optar por receber contagens de execução em vez de informações binárias de cobertura; mas o desempenho pode ser impactado por um aumento no overhead (veja a próxima seção para mais detalhes). A cobertura precisa pode ser coletada em granularidade de função ou de bloco.
A API do Inspector para cobertura precisa é a seguinte:
-
Profiler.startPreciseCoverage(callCount, detailed)ativa a coleta de cobertura, opcionalmente com contagens de chamadas (vs. cobertura binária) e granularidade de bloco (vs. granularidade de função); -
Profiler.takePreciseCoverage()retorna informações de cobertura coletadas como uma lista de intervalos de origem junto com contagens de execução associadas; e -
Profiler.stopPreciseCoverage()desativa a coleta e libera estruturas de dados relacionadas.
Uma conversa pelo protocolo Inspector poderia ser assim:
// O integrador instrui o V8 a começar a coletar cobertura precisa.
{ "id": 26, "method": "Profiler.startPreciseCoverage",
"params": { "callCount": false, "detailed": true }}
// Integrador solicita dados de cobertura (delta desde a última solicitação).
{ "id": 32, "method":"Profiler.takePreciseCoverage" }
// A resposta contém uma coleção de intervalos de origem aninhados.
{ "id": 32, "result": { "result": [{
"functions": [
{
"functionName": "fib",
"isBlockCoverage": true, // Granularidade de bloco.
"ranges": [ // Um array de intervalos aninhados.
{
"startOffset": 50, // Deslocamento em bytes, inclusivo.
"endOffset": 224, // Deslocamento em bytes, exclusivo.
"count": 1
}, {
"startOffset": 97,
"endOffset": 107,
"count": 0
}, {
"startOffset": 134,
"endOffset": 144,
"count": 0
}, {
"startOffset": 192,
"endOffset": 223,
"count": 0
},
]},
"scriptId": "199",
"url": "file:///coverage-fib.html"
}
]
}}
// Finalmente, o embedder instrui o V8 para encerrar a coleta e
// liberar estruturas de dados relacionadas.
{"id":37,"method":"Profiler.stopPreciseCoverage"}
Da mesma forma, cobertura com melhor esforço pode ser obtida usando Profiler.getBestEffortCoverage().
Por trás das cenas
Conforme afirmado na seção anterior, o V8 suporta dois modos principais de cobertura de código: cobertura de melhor esforço e cobertura precisa. Continue lendo para uma visão geral de sua implementação.
Cobertura de melhor esforço
Tanto os modos de cobertura de melhor esforço quanto os de cobertura precisa reutilizam fortemente outros mecanismos do V8, o primeiro dos quais é chamado de contador de invocações. Cada vez que uma função é chamada através do interpretador Ignition do V8, nós incrementamos um contador de invocações no vetor de feedback da função. Conforme a função se torna quente e sobe níveis através do compilador otimizador, este contador é usado para ajudar a orientar decisões de inlining sobre quais funções incorporar; e agora, também confiamos nele para relatar cobertura de código.
O segundo mecanismo reutilizado determina o intervalo de origem das funções. Ao relatar cobertura de código, os números de invocação precisam ser vinculados a um intervalo associado dentro do arquivo fonte. Por exemplo, no exemplo abaixo, não só precisamos relatar que a função f foi executada exatamente uma vez, mas também que o intervalo de origem de f começa na linha 1 e termina na linha 3.
function f() {
console.log('Hello World');
}
f();
Mais uma vez tivemos sorte e conseguimos reutilizar informações existentes dentro do V8. As funções já sabiam suas posições de início e fim dentro do código fonte devido a Function.prototype.toString, que precisa saber a localização da função dentro do arquivo fonte para extrair a substring apropriada.
Ao coletar cobertura de melhor esforço, esses dois mecanismos são simplesmente vinculados: primeiro, encontramos todas as funções vivas percorrendo todo o heap. Para cada função visualizada, relatamos o número de invocações (armazenado no vetor de feedback, ao qual podemos acessar a partir da função) e intervalo de origem (convenientemente armazenado na própria função).
Observe que, como os números de invocação são mantidos independentemente de a cobertura estar habilitada, a cobertura de melhor esforço não introduz nenhuma sobrecarga de tempo de execução. Ela também não usa estruturas de dados dedicadas e, portanto, não precisa ser explicitamente habilitada ou desabilitada.
Então por que esse modo é chamado de melhor esforço, quais são suas limitações? Funções que saem do escopo podem ser liberadas pelo coletor de lixo. Isso significa que os números de invocação associados são perdidos e, na verdade, esquecemos completamente que essas funções já existiram. Portanto, 'melhor esforço': mesmo que tentemos o nosso melhor, as informações de cobertura coletadas podem estar incompletas.
Cobertura precisa (granularidade de função)
Em contraste com o modo de melhor esforço, a cobertura precisa garante que as informações de cobertura fornecidas estão completas. Para conseguir isso, adicionamos todos os vetores de feedback ao conjunto raiz de referências do V8 uma vez que a cobertura precisa está habilitada, impedindo sua coleta pelo GC. Embora isso garanta que nenhuma informação seja perdida, aumenta o consumo de memória ao manter objetos vivos artificialmente.
O modo de cobertura precisa também pode fornecer contagens de execução. Isso adiciona outra complicação à implementação da cobertura precisa. Lembre-se de que o contador de invocações é incrementado cada vez que uma função é chamada através do interpretador do V8, e que as funções podem subir níveis e serem otimizadas assim que se tornam quentes. Mas funções otimizadas não incrementam mais seu contador de invocações, e assim o compilador otimizador deve ser desabilitado para que a contagem de execução relatada permaneça precisa.
Cobertura precisa (granularidade de bloco)
A cobertura com granularidade de bloco deve relatar cobertura que seja correta até o nível de expressões individuais. Por exemplo, no seguinte trecho de código, a cobertura de bloco poderia detectar que o ramo else da expressão condicional : c nunca é executado, enquanto a cobertura de granularidade de função só saberia que a função f (em sua totalidade) está coberta.
function f(a) {
return a ? b : c;
}
f(true);
Você deve se lembrar das seções anteriores, nas quais já tínhamos contagens de invocação de funções e intervalos de origem prontamente disponíveis dentro do V8. Infelizmente, esse não era o caso para a cobertura de blocos e tivemos que implementar novos mecanismos para coletar tanto contagens de execução quanto seus intervalos de origem correspondentes.
O primeiro aspecto são os intervalos de origem: supondo que temos uma contagem de execução para um bloco específico, como podemos mapeá-los para uma seção do código-fonte? Para isso, precisamos coletar posições relevantes enquanto analisamos os arquivos de origem. Antes da cobertura de blocos, o V8 já fazia isso até certo ponto. Um exemplo é a coleta de intervalos de funções devido ao Function.prototype.toString, como descrito acima. Outro é que posições de origem são usadas para construir o rastreamento de erros de objetos Error. Mas nenhum desses é suficiente para suportar a cobertura de blocos; o primeiro está disponível apenas para funções, enquanto o segundo apenas armazena posições (por exemplo, a posição do token if para declarações if-else), não intervalos de origem.
Portanto, tivemos que estender o analisador para coletar intervalos de origem. Para demonstrar, considere uma declaração if-else:
if (cond) {
/* Ramificação Then. */
} else {
/* Ramificação Else. */
}
Quando a cobertura de blocos está ativada, coletamos o intervalo de origem das ramificações then e else e as associamos ao nó AST IfStatement analisado. O mesmo é feito para outros construtos de linguagens relevantes.
Depois de coletar os intervalos de origem durante a análise, o segundo aspecto é acompanhar as contagens de execução em tempo de execução. Isso é feito ao inserir um novo bytecode dedicado IncBlockCounter em posições estratégicas dentro do array de bytecode gerado. Em tempo de execução, o manipulador de bytecode IncBlockCounter simplesmente incrementa o contador apropriado (acessível através do objeto função).
No exemplo acima de uma declaração if-else, tais bytecodes seriam inseridos em três pontos: imediatamente antes do corpo da ramificação then, antes do corpo da ramificação else e imediatamente após a declaração if-else (tais contadores de continuidade são necessários devido à possibilidade de controle não local dentro de uma ramificação).
Finalmente, a geração de relatórios de cobertura em granularidade de bloco funciona de forma semelhante à geração em granularidade de função. Mas além das contagens de invocação (do vetor de feedback), agora também relatamos a coleção de intervalos de origem interessantes junto com suas contagens de bloco (armazenadas em uma estrutura de dados auxiliar conectada à função).
Se você quiser saber mais sobre os detalhes técnicos por trás da cobertura de código no V8, veja os documentos de design de cobertura e cobertura de blocos.
Conclusão
Esperamos que você tenha gostado desta breve introdução ao suporte nativo de cobertura de código do V8. Por favor, experimente e não hesite em nos informar o que funciona para você e o que não funciona. Diga olá no Twitter (@schuay e @hashseed) ou registre um bug em crbug.com/v8/new.
O suporte de cobertura no V8 foi um esforço de equipe, e agradecimentos são devidos a todos que contribuíram: Benjamin Coe, Jakob Gruber, Yang Guo, Marja Hölttä, Andrey Kosyakov, Alexey Kozyatinksiy, Ross McIlroy, Ali Sheikh, Michael Starzinger. Obrigado!