Cobertura de código JavaScript
La cobertura de código proporciona información sobre si, y opcionalmente con qué frecuencia, se han ejecutado ciertas partes de una aplicación. Comúnmente se utiliza para determinar qué tan exhaustivamente una suite de pruebas evalúa una base de código en particular.
¿Por qué es útil?
Como desarrollador de JavaScript, puede que frecuentemente te encuentres en una situación en la que la cobertura de código sea útil. Por ejemplo:
- ¿Interesado en la calidad de tu suite de pruebas? ¿Refactorizando un gran proyecto heredado? La cobertura de código puede mostrarte exactamente qué partes de tu base de código están cubiertas.
- ¿Quieres saber rápidamente si se alcanza una parte particular de la base de código? En lugar de instrumentar con
console.logpara la depuración estiloprintfo avanzar manualmente paso a paso por el código, la cobertura de código puede mostrar información en vivo sobre qué partes de tus aplicaciones se han ejecutado. - ¿O tal vez estás optimizando para velocidad y te gustaría saber en qué áreas enfocarte? Los conteos de ejecución pueden señalar funciones y bucles calientes.
Cobertura de código JavaScript en V8
A principios de este año, agregamos soporte nativo para la cobertura de código JavaScript en V8. La versión inicial en la versión 5.9 proporcionó cobertura a nivel de funciones (mostrando qué funciones se han ejecutado), lo que se extendió más tarde para admitir cobertura a nivel de bloques en la v6.2 (igualmente, pero para expresiones individuales).
Para desarrolladores de JavaScript
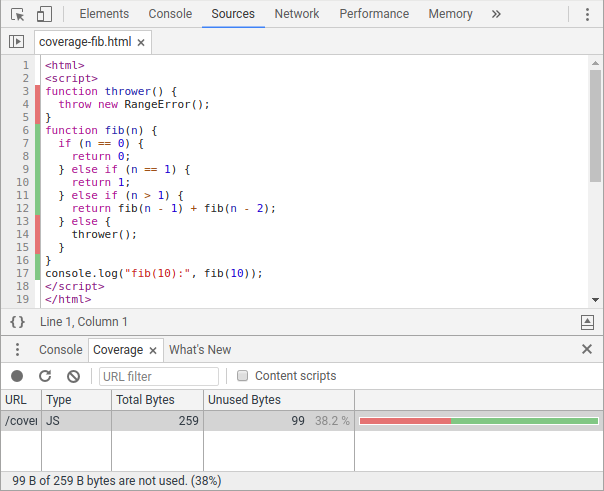
Actualmente hay dos formas principales de acceder a la información de cobertura. Para desarrolladores de JavaScript, la pestaña de Cobertura de Chrome DevTools expone relaciones de cobertura de JS (y CSS) y resalta el código inactivo en el panel Sources.
Gracias a Benjamin Coe, también hay trabajo en curso para integrar la información de cobertura de código de V8 en la popular herramienta de cobertura de código Istanbul.js.

Para embebedores
Los embebedores y los autores de frameworks pueden conectarse directamente a la API del Inspector para mayor flexibilidad. V8 ofrece dos modos diferentes de cobertura:
-
La cobertura de mejor esfuerzo recopila información de cobertura con un impacto mínimo en el rendimiento de ejecución, pero podría perder datos en funciones recolectadas por el recolector de basura (GC).
-
La cobertura precisa asegura que no se pierdan datos debido al GC, y los usuarios pueden elegir recibir conteos de ejecución en lugar de información binaria de cobertura; pero el rendimiento podría verse afectado por el aumento en la sobrecarga (ver la siguiente sección para más detalles). La cobertura precisa puede recopilarse ya sea a nivel de función o de bloque.
La API del Inspector para cobertura precisa es la siguiente:
-
Profiler.startPreciseCoverage(callCount, detailed)habilita la recopilación de cobertura, opcionalmente con conteos de llamadas (en lugar de cobertura binaria) y granularidad de bloque (en lugar de granularidad de función); -
Profiler.takePreciseCoverage()devuelve la información de cobertura recopilada como una lista de rangos de origen junto con los conteos de ejecución asociados; y -
Profiler.stopPreciseCoverage()deshabilita la recopilación y libera las estructuras de datos relacionadas.
Una conversación a través del protocolo del Inspector podría lucir así:
// El embebedor instruye a V8 para comenzar a recopilar cobertura precisa.
{ "id": 26, "method": "Profiler.startPreciseCoverage",
"params": { "callCount": false, "detailed": true }}
// El embebedor solicita datos de cobertura (delta desde la última solicitud).
{ "id": 32, "method":"Profiler.takePreciseCoverage" }
// La respuesta contiene una colección de rangos de origen anidados.
{ "id": 32, "result": { "result": [{
"functions": [
{
"functionName": "fib",
"isBlockCoverage": true, // Granularidad de bloque.
"ranges": [ // Un array de rangos anidados.
{
"startOffset": 50, // Desplazamiento en bytes, inclusivo.
"endOffset": 224, // Desplazamiento en bytes, exclusivo.
"count": 1
}, {
"startOffset": 97,
"endOffset": 107,
"count": 0
}, {
"startOffset": 134,
"endOffset": 144,
"count": 0
}, {
"startOffset": 192,
"endOffset": 223,
"count": 0
},
]},
"scriptId": "199",
"url": "file:///coverage-fib.html"
}
]
}}
// Finalmente, el integrador ordena a V8 finalizar la colección y
// liberar las estructuras de datos relacionadas.
{"id":37,"method":"Profiler.stopPreciseCoverage"}
De manera similar, se puede recuperar la cobertura de mejor esfuerzo utilizando Profiler.getBestEffortCoverage().
Detrás de escena
Como se indicó en la sección anterior, V8 admite dos modos principales de cobertura de código: cobertura de mejor esfuerzo y cobertura precisa. Continúe leyendo para obtener una descripción general de su implementación.
Cobertura de mejor esfuerzo
Tanto los modos de cobertura de mejor esfuerzo como los de cobertura precisa reutilizan ampliamente otros mecanismos de V8, el primero de los cuales se denomina contador de invocación. Cada vez que una función se llama a través del intérprete Ignition de V8, incrementamos un contador de invocación en el vector de retroalimentación de la función. A medida que la función se calienta y asciende a través del compilador optimizante, este contador se utiliza para ayudar a guiar decisiones sobre qué funciones se deben incorporar; y ahora, también confiamos en ello para informar la cobertura de código.
El segundo mecanismo reutilizado determina el rango de origen de las funciones. Al informar la cobertura de código, los conteos de invocación deben estar vinculados a un rango asociado dentro del archivo fuente. Por ejemplo, en el ejemplo siguiente, no solo necesitamos informar que la función f se ha ejecutado exactamente una vez, sino también que el rango de origen de f comienza en la línea 1 y termina en la línea 3.
function f() {
console.log('Hello World');
}
f();
Nuevamente, tuvimos suerte y pudimos reutilizar información existente dentro de V8. Las funciones ya conocían sus posiciones de inicio y final dentro del código fuente debido a Function.prototype.toString, que necesita conocer la ubicación de la función dentro del archivo fuente para extraer la subcadena apropiada.
Al recopilar cobertura de mejor esfuerzo, estos dos mecanismos simplemente se vinculan juntos: primero encontramos todas las funciones vivas recorriendo todo el heap. Para cada función vista, informamos el contador de invocación (almacenado en el vector de retroalimentación, al cual podemos acceder desde la función) y el rango de origen (almacenado convenientemente en la función misma).
Tenga en cuenta que dado que los conteos de invocación se mantienen independientemente de si la cobertura está habilitada, la cobertura de mejor esfuerzo no introduce ninguna sobrecarga en tiempo de ejecución. Tampoco utiliza estructuras de datos dedicadas y, por lo tanto, no necesita habilitarse o deshabilitarse explícitamente.
Entonces, ¿por qué a este modo se le llama mejor esfuerzo, cuáles son sus limitaciones? Las funciones que salen del alcance pueden ser liberadas por el recolector de basura. Esto significa que se pierden los conteos de invocación asociados y, de hecho, olvidamos completamente que estas funciones alguna vez existieron. Ergo ‘mejor esfuerzo’: aunque intentamos lo mejor posible, la información de cobertura recopilada puede estar incompleta.
Cobertura precisa (granularidad a nivel de función)
A diferencia del modo de mejor esfuerzo, la cobertura precisa garantiza que la información de cobertura proporcionada sea completa. Para lograr esto, agregamos todos los vectores de retroalimentación al conjunto raíz de referencias de V8 una vez que se habilita la cobertura precisa, evitando su recolección por parte del GC. Si bien esto asegura que no se pierda información, aumenta el consumo de memoria al mantener vivos objetos de forma artificial.
El modo de cobertura precisa también puede proporcionar conteos de ejecuciones. Esto agrega un matiz adicional a la implementación de cobertura precisa. Recuerde que el contador de invocación se incrementa cada vez que se llama a una función a través del intérprete de V8, y que las funciones pueden escalar y optimizarse una vez que se calientan. Pero las funciones optimizadas ya no incrementan su contador de invocación, y por lo tanto, el compilador optimizante debe deshabilitarse para que el conteo de ejecución informado siga siendo exacto.
Cobertura precisa (granularidad a nivel de bloque)
La cobertura a nivel de bloque debe informar una cobertura que sea correcta hasta el nivel de expresiones individuales. Por ejemplo, en el siguiente fragmento de código, la cobertura de bloque podría detectar que la rama else de la expresión condicional : c nunca se ejecuta, mientras que la cobertura de granularidad a nivel de función solo sabría que la función f (en su totalidad) está cubierta.
function f(a) {
return a ? b : c;
}
f(true);
Es posible que recuerdes de las secciones anteriores que ya teníamos disponibles los conteos de invocación de funciones y los rangos de origen dentro de V8. Lamentablemente, este no era el caso para la cobertura de bloques, y tuvimos que implementar nuevos mecanismos para recopilar tanto los conteos de ejecución como sus rangos de origen correspondientes.
El primer aspecto son los rangos de origen: suponiendo que tenemos un conteo de ejecución para un bloque particular, ¿cómo podemos mapearlos a una sección del código fuente? Para ello, necesitamos recopilar las posiciones relevantes mientras analizamos los archivos fuente. Antes de la cobertura de bloques, V8 ya hacía esto en cierta medida. Un ejemplo es la recopilación de rangos de función debido a Function.prototype.toString como se describió anteriormente. Otro es que las posiciones de origen se utilizan para construir el rastro de retroceso para los objetos Error. Pero ninguno de estos es suficiente para admitir la cobertura de bloques; el primero solo está disponible para funciones, mientras que el segundo solo almacena posiciones (por ejemplo, la posición del token if para las declaraciones if-else), no rangos de origen.
Por lo tanto, tuvimos que extender el analizador para recopilar rangos de origen. Para demostrarlo, considera una declaración if-else:
if (cond) {
/* Rama Then. */
} else {
/* Rama Else. */
}
Cuando la cobertura de bloques está habilitada, recopilamos el rango de origen de las ramas then y else y las asociamos con el nodo AST IfStatement analizado. Lo mismo se hace para otros constructos relevantes del lenguaje.
Después de recopilar los rangos de origen durante el análisis, el segundo aspecto es rastrear los conteos de ejecución en tiempo de ejecución. Esto se hace insertando un nuevo código de bytes dedicado IncBlockCounter en posiciones estratégicas dentro de la matriz de código de bytes generada. En tiempo de ejecución, el controlador de código de bytes IncBlockCounter simplemente incrementa el contador correspondiente (alcanzable a través del objeto de función).
En el ejemplo anterior de una declaración if-else, tales códigos de bytes se insertarían en tres puntos: inmediatamente antes del cuerpo de la rama then, antes del cuerpo de la rama else y justo después de la declaración if-else (dichos contadores de continuación son necesarios debido a la posibilidad de control no local dentro de una rama).
Finalmente, el informe de cobertura a nivel de bloque funciona de manera similar al informe a nivel de función. Pero además de los conteos de invocación (del vector de retroalimentación), ahora también informamos la colección de rangos de origen interesantes junto con sus conteos de bloque (almacenados en una estructura de datos auxiliar que depende de la función).
Si deseas aprender más sobre los detalles técnicos detrás de la cobertura de código en V8, consulta los documentos de diseño de cobertura y cobertura de bloques.
Conclusión
Esperamos que hayas disfrutado esta breve introducción al soporte nativo de cobertura de código de V8. Por favor, pruébalo y no dudes en hacernos saber qué funciona para ti y qué no. Salúdanos en Twitter (@schuay y @hashseed) o informa un error en crbug.com/v8/new.
El soporte de cobertura en V8 ha sido un esfuerzo de equipo, y se deben dar las gracias a todos los que han contribuido: Benjamin Coe, Jakob Gruber, Yang Guo, Marja Hölttä, Andrey Kosyakov, Alexey Kozyatinksiy, Ross McIlroy, Ali Sheikh, Michael Starzinger. ¡Gracias!