자바스크립트 코드 커버리지
코드 커버리지는 애플리케이션의 특정 부분이 실행되었는지 여부와 선택적으로 얼마나 자주 실행되었는지에 대한 정보를 제공합니다. 이는 테스트 스위트가 특정 코드베이스를 얼마나 철저히 검증하는지 판단하는 데 자주 사용됩니다.
왜 유용한가요?
자바스크립트 개발자로서 코드 커버리지가 유용할 수 있는 상황에 자주 처하게 될 것입니다. 예를 들어:
- 테스트 스위트의 품질에 관심이 있나요? 오래된 레거시 프로젝트를 리팩토링 중인가요? 코드 커버리지는 코드베이스의 어떤 부분이 커버되었는지를 정확히 보여줄 수 있습니다.
- 코드베이스의 특정 부분이 빠르게 도달되었는지 알고 싶나요?
console.log를 이용한printf스타일 디버깅이나 코드를 수동으로 디버깅하는 대신, 코드 커버리지는 애플리케이션의 어떤 부분이 실행되었는지에 대한 실시간 정보를 표시할 수 있습니다. - 또는 속도 최적화를 위해 어느 부분에 집중해야 할지 알고 싶나요? 실행 횟수는 핫 함수와 루프를 지적할 수 있습니다.
V8에서의 자바스크립트 코드 커버리지
올해 초, 우리는 V8에 자바스크립트 코드 커버리지에 대한 네이티브 지원을 추가했습니다. 버전 5.9에서의 초기 릴리스는 함수 단위의 커버리지를 제공했으며(어떤 함수가 실행되었는지 표시), 이후 v6.2에서 블록 단위의 커버리지를 지원하도록 확장되었습니다(개별 표현식에 대해서도 동일).
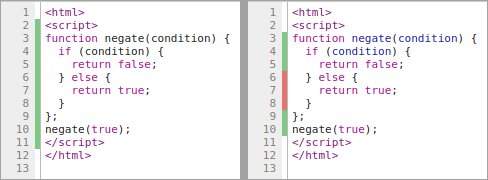
자바스크립트 개발자를 위한
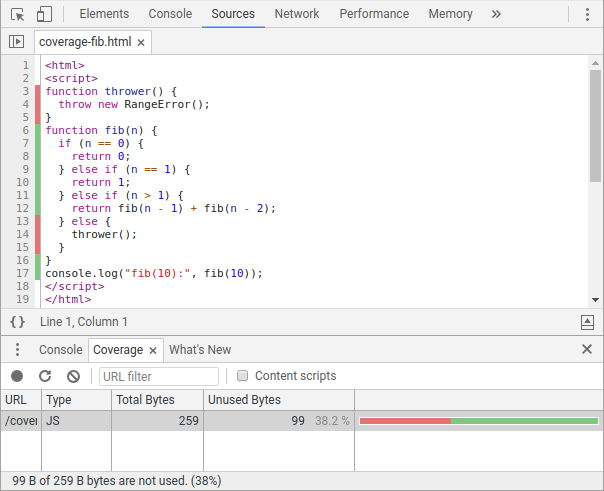
현재 커버리지 정보를 액세스하는 주요 방법이 두 가지 있습니다. 자바스크립트 개발자를 위해 Chrome DevTools의 Coverage 탭은 JS(및 CSS) 커버리지 비율을 공개하고 Sources 패널에서 비활성화된 코드를 강조합니다.
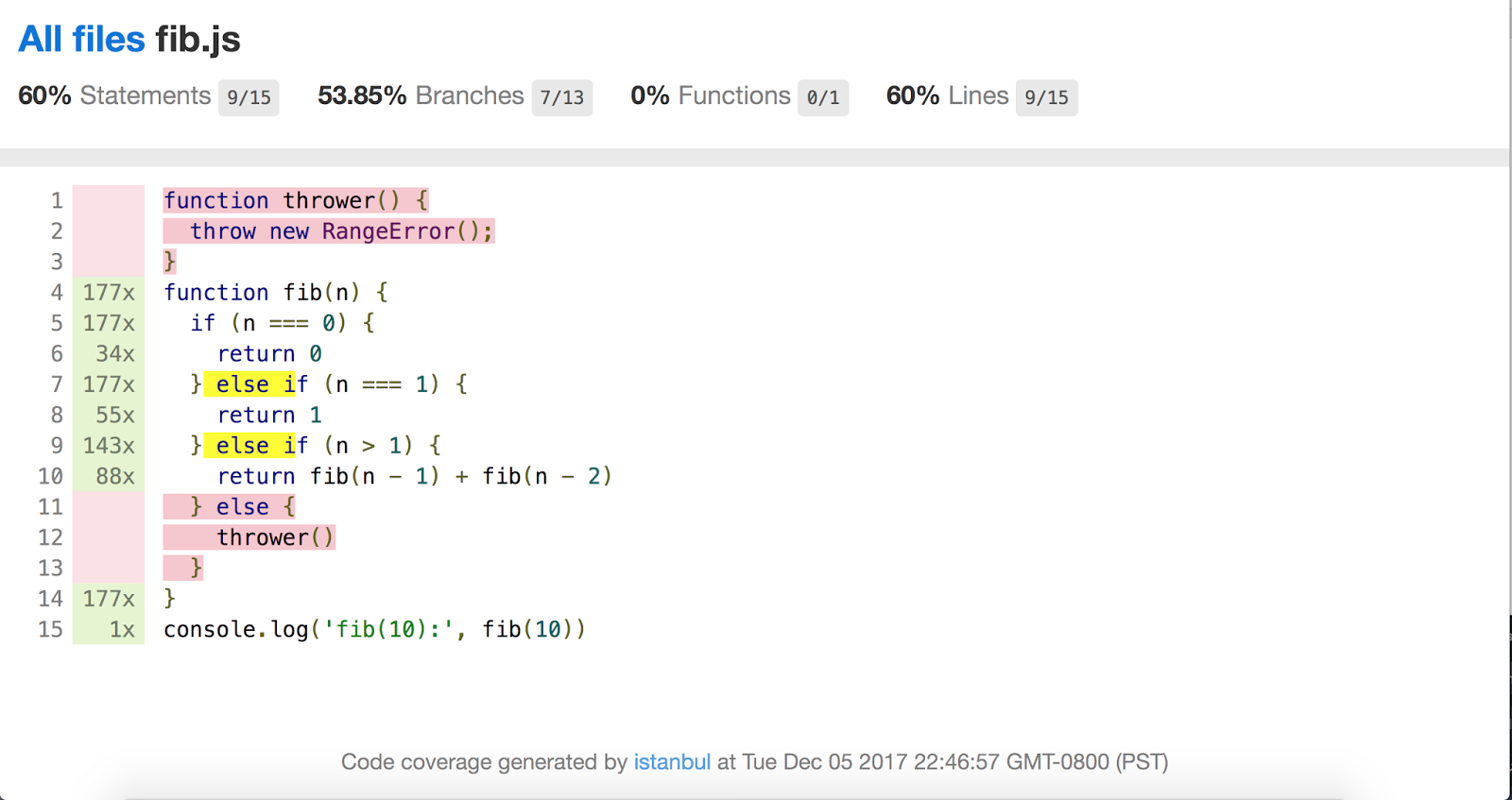
Benjamin Coe 덕분에, V8의 코드 커버리지 정보를 인기 있는 코드 커버리지 도구인 Istanbul.js와 통합하려는 진행 중인 작업도 있습니다.
임베더를 위한
임베더와 프레임워크 작성자는 더 많은 유연성을 위해 Inspector API에 바로 연결할 수 있습니다. V8은 두 가지 다른 커버리지 모드를 제공합니다:
-
_최선의 노력 커버리지_는 런타임 성능에 최소한의 영향을 주면서 커버리지 정보를 수집하지만, 가비지 컬렉션(GC)된 함수에서 데이터를 잃을 수 있습니다.
-
_정확한 커버리지_는 GC에 의해 데이터가 손실되지 않도록 보장하며, 사용자는 이진 커버리지 정보 대신 실행 횟수를 받을 수 있도록 선택할 수 있습니다. 그러나 성능은 증가된 오버헤드로 인해 영향을 받을 수 있습니다(다음 섹션에서 자세히 설명). 정확한 커버리지는 함수 또는 블록 단위로 수집할 수 있습니다.
정확한 커버리지를 위한 Inspector API는 다음과 같습니다:
-
Profiler.startPreciseCoverage(callCount, detailed)는 커버리지 수집을 활성화하며, 선택적으로 호출 횟수(대 이진 커버리지)와 블록 단위(대 함수 단위)를 제공합니다; -
Profiler.takePreciseCoverage()는 소스 범위 목록과 연결된 실행 횟수로 수집된 커버리지 정보를 반환합니다; 그리고 -
Profiler.stopPreciseCoverage()는 수집을 비활성화하고 관련 데이터 구조를 해제합니다.
Inspector 프로토콜을 통한 대화는 다음과 같을 수 있습니다:
// 임베더가 V8에 정확한 커버리지 수집을 시작하도록 지시합니다.
{ "id": 26, "method": "Profiler.startPreciseCoverage",
"params": { "callCount": false, "detailed": true }}
// 임베더가 커버리지 데이터를 요청합니다(마지막 요청 이후 델타).
{ "id": 32, "method":"Profiler.takePreciseCoverage" }
// 응답은 중첩된 소스 범위의 컬렉션을 포함합니다.
{ "id": 32, "result": { "result": [{
"functions": [
{
"functionName": "fib",
"isBlockCoverage": true, // 블록 단위.
"ranges": [ // 중첩된 범위 배열.
{
"startOffset": 50, // 바이트 오프셋, 포함.
"endOffset": 224, // 바이트 오프셋, 제외.
"count": 1
}, {
"startOffset": 97,
"endOffset": 107,
"count": 0
}, {
"startOffset": 134,
"endOffset": 144,
"count": 0
}, {
"startOffset": 192,
"endOffset": 223,
"count": 0
},
]},
"scriptId": "199",
"url": "file:///coverage-fib.html"
}
]
}}
// 마지막으로, 임베더가 V8에 데이터를 수집하는 작업을 끝내고 관련 데이터 구조를 해제하도록 지시합니다.
// 관련 데이터 구조를 해제합니다.
{"id":37,"method":"Profiler.stopPreciseCoverage"}
마찬가지로, 베스트 에포트 커버리지는 Profiler.getBestEffortCoverage()를 사용하여 가져올 수 있습니다.
내부 동작
이전 섹션에서 언급했듯이, V8은 코드 커버리지의 두 가지 주요 모드를 지원합니다: 베스트 에포트 및 정밀 커버리지. 구현 개요를 알아보겠습니다.
베스트 에포트 커버리지
베스트 에포트와 정밀 커버리지 모드는 V8의 다른 메커니즘을 적극적으로 재사용합니다. 그 중 첫 번째는 _호출 카운터_입니다. V8의 Ignition 인터프리터를 통해 함수가 호출될 때마다, 우리는 함수의 피드백 벡터에서 호출 카운터를 증가시킵니다. 해당 함수가 나중에 활성화되어 최적화 컴파일러를 통해 단계를 올릴 때, 이 카운터는 어떤 함수를 인라인 하느냐에 대한 의사결정을 안내하는 데 사용됩니다. 그리고 현재, 우리는 이를 코드 커버리지를 보고하는 데에도 의존하고 있습니다.
두 번째 재사용 메커니즘은 함수의 소스 범위를 결정하는 것입니다. 코드 커버리지를 보고할 때, 호출 횟수는 소스 파일 내의 연관된 범위에 연결되어야 합니다. 예를 들어 아래 예에서 우리는 함수 f가 정확히 한 번 실행되었다고 보고해야 할 뿐만 아니라, f의 소스 범위가 1행에서 시작하여 3행에서 끝난다고도 보고해야 합니다.
function f() {
console.log('Hello World');
}
f();
다시 한번 운이 좋아서, 우리는 V8 내 기존 정보를 재사용할 수 있었습니다. 함수는 이미 Function.prototype.toString를 통해 소스 코드 내 시작 및 종료 위치를 알고 있었으며, 이는 소스 파일에서 적절한 하위 문자열을 추출하려면 함수의 위치를 알아야 합니다.
베스트 에포트 커버리지를 수집할 때, 이 두 메커니즘은 단순히 결합됩니다: 먼저 전체 힙을 순회하여 모든 라이브 함수를 찾습니다. 각 관찰된 함수에 대해 호출 횟수(피드백 백터에 저장된 값을 함수에서 가져옵니다)와 소스 범위(편리하게 함수 자체에 저장된)를 보고합니다.
참고로 호출 횟수는 커버리지가 활성화되었는지 여부에 관계없이 유지되기 때문에, 베스트 에포트 커버리지는 런타임 오버헤드를 도입하지 않습니다. 또한 전용 데이터 구조를 사용하지 않으며 명시적으로 활성화하거나 비활성화할 필요도 없습니다.
그렇다면 이 모드가 왜 베스트 에포트라고 불리며, 그것의 제한은 무엇일까요? 스코프에서 벗어난 함수들은 가비지 컬렉터에 의해 해제될 수 있습니다. 이는 연결된 호출 횟수가 손실된다는 것을 의미하며 실제로는 이러한 함수가 존재했었다는 것을 완전히 잊어버립니다. 따라서 '베스트 에포트': 최선을 다하지만 수집된 커버리지 정보는 불완전할 수 있습니다.
정밀 커버리지(함수 단위)
베스트 에포트 모드와는 달리, 정밀 커버리지는 제공된 커버리지 정보가 완전하다는 것을 보장합니다. 이를 실현하기 위해, 정밀 커버리지가 활성화되면 모든 피드백 벡터를 V8의 루트 참조 세트에 추가하여 GC에서 해제되지 않도록 합니다. 이렇게 하면 정보가 손실되지 않지만 객체를 인위적으로 살려둠으로써 메모리 소비가 증가합니다.
정밀 커버리지 모드는 실행 횟수도 제공할 수 있습니다. 이는 구현에 또 다른 복잡함을 추가합니다. 호출 카운터가 V8의 인터프리터를 통해 함수가 호출될 때마다 증가하고, 함수가 활성화되어 최적화될 수 있다는 점을 기억하십시오. 그러나 최적화된 함수는 더 이상 호출 카운터를 증가시키지 않으므로 보고된 실행 횟수가 정확하게 유지되려면 최적화 컴파일러를 비활성화해야 합니다.
정밀 커버리지(블록 단위)
블록 단위 커버리지는 개별 표현식 수준까지 정확한 커버리지를 보고해야 합니다. 예를 들어 아래 코드에서 블록 커버리지는 조건 표현식의 else 분기인 : c가 실행되지 않았다는 것을 감지할 수 있습니다. 반면 함수 단위 커버리지는 함수 f 전체가 커버되었다는 것만 알 수 있습니다.
function f(a) {
return a ? b : c;
}
f(true);
이전 섹션에서 우리는 이미 V8 내에서 함수 호출 횟수와 소스 범위를 쉽게 사용할 수 있었음을 기억할 것입니다. 그러나 블록 커버리지의 경우는 그렇지 않았으며 실행 횟수와 해당 소스 범위를 수집하기 위한 새로운 메커니즘을 구현해야 했습니다.
첫 번째 측면은 소스 범위입니다: 특정 블록에 대한 실행 횟수가 있는 경우, 이를 소스 코드의 섹션에 어떻게 매핑할 수 있을까요? 이를 위해 소스 파일을 구문 분석하면서 관련 위치를 수집해야 합니다. 블록 커버리지 이전에도 V8은 어느 정도 이를 수행했습니다. 한 예는 위에서 설명한 대로 Function.prototype.toString으로 인해 함수 범위를 수집하는 것입니다. 또 다른 예는 소스 위치가 Error 객체의 백트레이스 생성에 사용된다는 것입니다. 하지만 이 두 가지는 블록 커버리지를 지원하기에는 충분하지 않습니다; 전자는 함수에서만 사용할 수 있고, 후자는 위치(예: if-else 문에 대한 if 토큰의 위치)를 저장하며 소스 범위는 저장하지 않습니다.
따라서 우리는 소스 범위를 수집하기 위해 구문 분석기를 확장해야 했습니다. 이를 설명하기 위해, if-else 문을 고려해보겠습니다:
if (cond) {
/* Then branch. */
} else {
/* Else branch. */
}
블록 커버리지가 활성화되면, 우리는 then 및 else 분기의 소스 범위를 수집하고 이를 구문 분석된 IfStatement AST 노드와 연결합니다. 동일한 작업이 다른 관련 언어 구성 요소에도 수행됩니다.
구문 분석 중 소스 범위 수집 후, 두 번째 측면은 런타임 시 실행 횟수를 추적하는 것입니다. 이는 생성된 바이트코드 배열 내의 전략적 위치에 새로 전용 IncBlockCounter 바이트코드를 삽입하여 수행됩니다. 런타임 시, IncBlockCounter 바이트코드 핸들러는 단순히 적절한 카운터를 증가시킵니다(함수 객체를 통해 도달 가능).
if-else 문의 예에서 이러한 바이트코드는 다음 세 위치에 삽입됩니다: then 분기 본문 직전에, else 분기 본문 직전에, 그리고 if-else 문 바로 뒤(분기 내의 비지역 제어 가능성으로 인해 이러한 연속 카운터가 필요함).
마지막으로, 블록 단위 커버리지 보고는 함수 단위 보고와 유사하게 작동합니다. 하지만 호출 횟수(피드백 벡터로부터) 외에도, 이제 우리는 흥미로운 소스 범위의 수집 및 해당 블록 횟수(함수에 연결된 보조 데이터 구조에 저장)를 보고합니다.
V8의 코드 커버리지 뒤의 기술적 세부 사항에 대해 더 자세히 알고 싶으시면 커버리지 및 블록 커버리지 설계 문서를 참조하십시오.
결론
V8의 네이티브 코드 커버리지 지원에 대한 간단한 소개를 즐기셨기를 바랍니다. 한 번 시도해 보시고, 어떤 것이 잘 작동하고 어떤 것이 그렇지 않은지 자유롭게 알려주십시오. Twitter에서 인사해 주세요 (@schuay 및 @hashseed) 또는 crbug.com/v8/new에서 버그를 신고하세요.
V8에서의 커버리지 지원은 팀의 노력의 결과였으며, 기여한 모든 분들께 감사를 드립니다: Benjamin Coe, Jakob Gruber, Yang Guo, Marja Hölttä, Andrey Kosyakov, Alexey Kozyatinksiy, Ross McIlroy, Ali Sheikh, Michael Starzinger. 감사합니다!