Orinoco: 젊은 세대 가비지 컬렉션
V8의 JavaScript 객체는 V8의 가비지 컬렉터로 관리되는 힙에 할당됩니다. 이전 블로그 글에서는 가비지 컬렉션 일시 중지 시간을 어떻게 줄이는지 (여러 번) 그리고 메모리 소비를 줄이는 방법도 다뤘습니다. 이번 블로그 글에서는 V8의 거의 병렬 및 동시 가비지 컬렉터 Orinoco의 최신 기능 중 하나인 병렬 Scavenger를 소개하고 설계 결정 및 대안 접근 방식에 대해 논의합니다.
V8은 관리되는 힙을 객체가 처음에는 젊은 세대의 'nursery'에 할당되는 여러 세대로 분할합니다. 가비지 컬렉션에서 생존한 객체는 젊은 세대의 일부인 중간 세대로 복사됩니다. 또 다른 가비지 컬렉션에서 생존한 후에는 이러한 객체가 오래된 세대(old generation)로 이동됩니다(그림 1 참조). V8은 두 가지 가비지 컬렉터를 구현합니다: 하나는 젊은 세대를 자주 수집하고, 또 하나는 젊은 세대와 오래된 세대 모두 포함된 전체 힙을 수집합니다. 오래된 세대에서 젊은 세대로의 참조는 젊은 세대 가비지 컬렉션의 루트가 됩니다. 이러한 참조는 기록되고 객체가 이동할 때 효율적인 루트 식별 및 참조 업데이트를 제공합니다.

젊은 세대는 상대적으로 크기가 작기 때문에 (V8에서는 최대 16MiB까지) 객체로 빠르게 채워지고 자주 수집이 필요합니다. M62까지 V8은 아래에 설명된 Cheney semispace 복사 가비지 컬렉터를 사용했으며, 이는 젊은 세대를 두 부분으로 나눕니다. JavaScript 실행 중에는 젊은 세대의 한 부분만 객체 할당에 사용 가능하며, 다른 부분은 비어 있습니다. 젊은 가비지 컬렉션 동안 살아있는 객체는 한 부분에서 다른 부분으로 복사되며 실시간으로 메모리가 압축됩니다. 한 번 복사된 후에도 살아있는 객체는 중간 세대의 일부로 간주되며 오래된 세대로 승격됩니다.
v6.2부터 V8은 젊은 세대를 수집하는 기본 알고리즘을 병렬 Scavenger로 변경했습니다, 이는 Halstead의 semispace 복사 컬렉터와 유사하지만 V8은 여러 스레드에서 정적 대신 동적 작업 훔침을 사용한다는 차이가 있습니다. 다음에서는 세 가지 알고리즘을 설명합니다: a) 단일 스레드 Cheney semispace 복사 컬렉터, b) 병렬 Mark-Evacuate 스키마, c) 병렬 Scavenger.
단일 스레드 Cheney's Semispace 복사
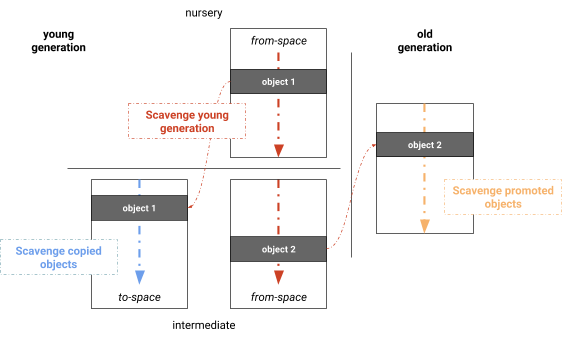
v6.2까지 V8은 단일 코어 실행 및 세대별 스키마에 적합한 Cheney의 semispace 복사 알고리즘을 사용했습니다. 젊은 세대 수집 전에 메모리의 두 semispace 절반이 커밋되고 적합한 레이블이 할당됩니다: 현재 객체 집합을 포함하는 페이지는 _from-space_라 불리고, 객체가 복사되는 페이지는 _to-space_라 불립니다.
Scavenger는 호출 스택의 참조와 오래된 세대에서 젊은 세대로의 참조를 루트로 간주합니다. 그림 2는 처음에 Scavenger가 이러한 루트를 스캔하고 아직 _to-space_로 복사되지 않은 _from-space_에서 도달 가능한 객체를 복사하는 알고리즘을 보여줍니다. 이미 가비지 컬렉션을 생존한 객체는 오래된 세대로 승격(이동)됩니다. 루트를 스캔하고 첫 번째 복사 라운드 후에 새로 할당된 to-space의 객체는 참조를 위해 스캔됩니다. 마찬가지로, 승격된 모든 객체는 _from-space_로의 새로운 참조를 위해 스캔됩니다. 이러한 세 가지 단계는 메인 스레드에서 상호 교차됩니다. 알고리즘은 to-space 또는 오래된 세대에서 더 이상 새로운 객체에 도달할 수 없는 경우까지 계속됩니다. 이 시점에서 _from-space_는 도달할 수 없는 객체만 포함하며, 즉 그것은 쓰레기만 포함합니다.
![]()
병렬 Mark-Evacuate
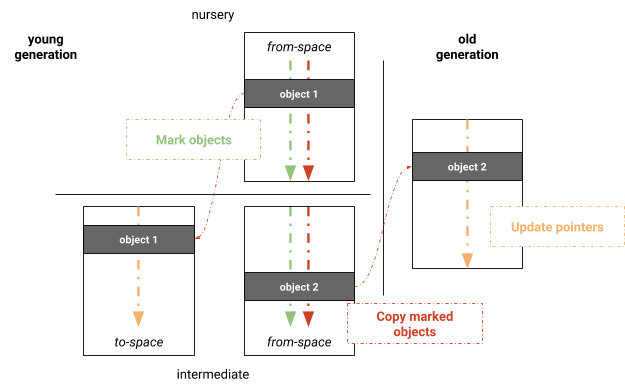
우리는 V8의 전체 Mark-Sweep-Compact 컬렉터를 기반으로 한 병렬 Mark-Evacuate 알고리즘을 실험했습니다. 주요 이점은 전체 Mark-Sweep-Compact 컬렉터로부터 이미 존재하는 가비지 컬렉션 인프라를 활용할 수 있다는 점입니다. 알고리즘은 도표 3에 표시된 것처럼 마킹, 복사 및 포인터 업데이트의 세 단계로 구성됩니다. 자유 목록을 유지하기 위해 젊은 세대의 페이지를 청소하는 것을 방지하기 위해, 젊은 세대는 가비지 컬렉션 동안 활성 객체를 _to-space_로 복사하여 항상 압축 상태로 유지되는 세미스페이스를 사용하여 계속 유지됩니다. 젊은 세대는 처음에 병렬로 마킹됩니다. 마킹 후, 활성 객체는 병렬로 해당 공간으로 복사됩니다. 작업은 논리 페이지를 기준으로 분배됩니다. 복사에 참여하는 쓰레드는 자체 로컬 할당 버퍼(LAB)를 유지하며 복사를 마친 후 병합됩니다. 복사 후, 동일한 병렬화 방식이 객체 간의 포인터를 업데이트하는 데 적용됩니다. 이 세 단계는 동기식으로 수행됩니다. 즉, 단계 자체는 병렬로 수행되지만 쓰레드는 다음 단계로 진행하기 전에 동기화를 해야 합니다.

병렬 Scavenge
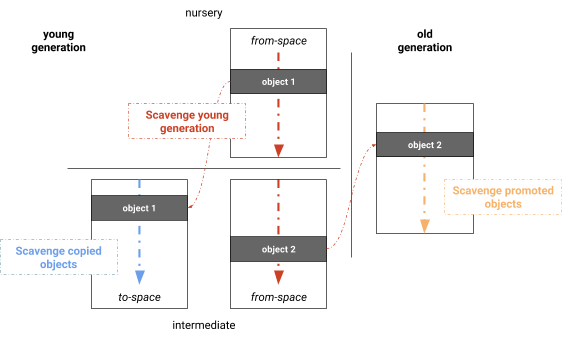
병렬 Mark-Evacuate 컬렉터는 라이브 상태 계산, 활성 객체 복사 및 포인터 업데이트 단계를 분리합니다. 명백한 최적화는 이러한 단계를 병합하여 동시에 마킹, 복사 및 포인터 업데이트를 수행하는 알고리즘을 구현하는 것입니다. 이러한 단계를 병합함으로써 실제로 V8에서 사용되는 병렬 Scavenger를 얻을 수 있으며, 이는 Halstead의 세미스페이스 컬렉터와 유사한 버전으로, V8은 동적 작업 도둑질 및 간단한 로드 밸런싱 메커니즘을 사용하여 루트를 스캔합니다(도표 4를 참조). 단일 쓰레드의 Cheney 알고리즘처럼, 단계는 루트 스캔, 젊은 세대 내 복사, 구세대로 승격 및 포인터 업데이트로 구성됩니다. 우리는 대다수의 루트 세트가 일반적으로 구세대에서 젊은 세대로의 참조임을 발견했습니다. 우리의 구현에서는 페이지별로 기억된 세트가 유지되며, 이는 자연스럽게 가비지 컬렉션 쓰레드 간에 루트 세트를 분배합니다. 객체는 병렬로 처리됩니다. 새로 발견된 객체는 가비지 컬렉션 쓰레드가 도둑질할 수 있는 전역 작업 목록에 추가됩니다. 이 작업 목록은 빠른 작업 로컬 저장소 및 작업 공유를 위한 전역 저장소를 제공합니다. 배리어는 현재 처리 중인 하위 그래프가 작업 도둑질에 적합하지 않은 경우(예: 객체의 선형 체인) 작업이 조기에 종료되지 않도록 합니다. 모든 단계는 병렬로 수행되고 각 작업에서 상호 교차되어 작업 최대 활용도를 극대화합니다.

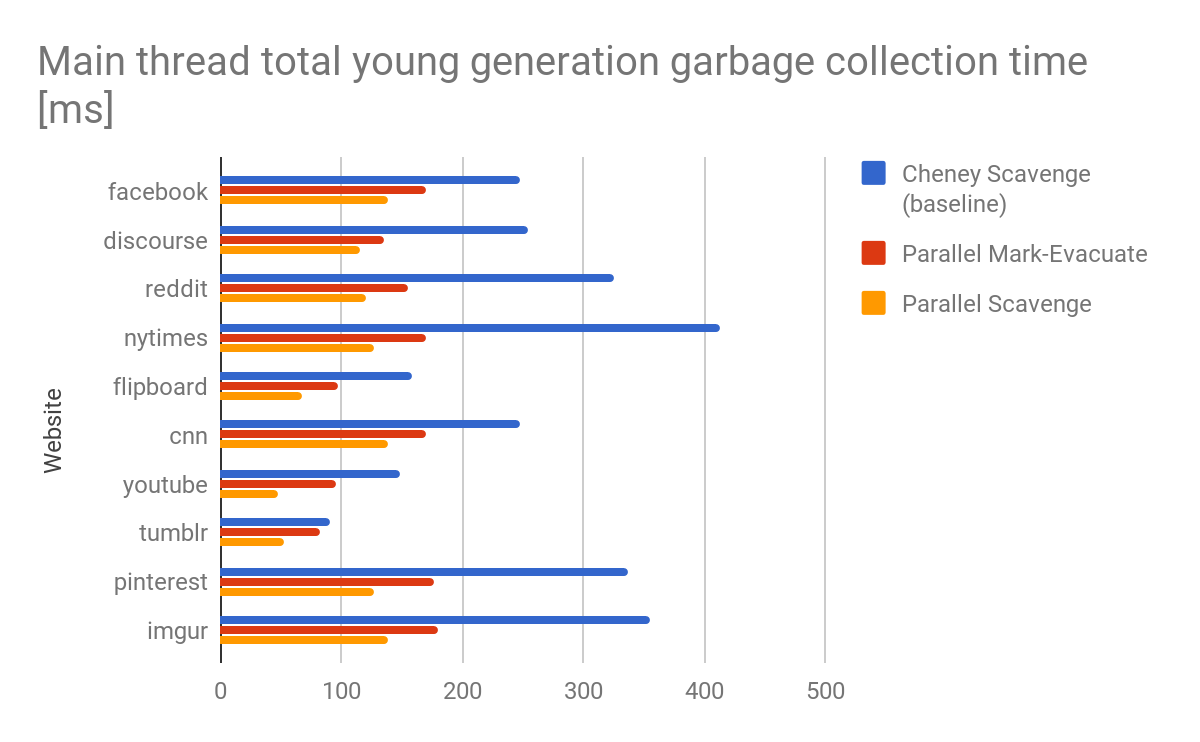
결과와 성과
Scavenger 알고리즘은 처음에 최적의 단일 코어 성능을 염두에 두고 설계되었습니다. 그 이후로 세계는 많이 변했습니다. CPU 코어는 저가형 모바일 장치에서도 종종 풍부합니다. 더 중요한 것은 종종 이러한 코어가 실제로 작동 중이라는 점입니다. 이러한 코어를 완전히 활용하려면 V8의 가비지 컬렉터의 마지막 순차 구성 요소 중 하나인 Scavenger를 현대화해야 했습니다.
병렬 Mark-Evacuate 컬렉터의 큰 장점은 정확한 라이브 상태 정보를 사용할 수 있다는 점입니다. 이 정보는 주로 활성 객체를 포함하는 페이지만 이동 및 재링크함으로써 복사를 전혀 피할 수 있도록 하여, 이는 전체 Mark-Sweep-Compact 컬렉터에서도 수행됩니다. 그러나 실제로 이는 대부분 합성 벤치마크에서 관찰되었으며 실제 웹사이트에서는 거의 나타나지 않았습니다. 병렬 Mark-Evacuate 컬렉터의 단점은 세 개의 별도의 동기식 단계를 수행하는 데 따른 오버헤드입니다. 이러한 오버헤드는 특히 가비지 컬렉터가 주로 죽은 객체로 채워진 힙에서 호출될 때 눈에 띕니다. 이는 많은 실제 웹 페이지의 경우입니다. 힙이 대부분 죽은 객체로 채워진 상태에서 가비지 컬렉션을 호출하는 것이 실제로 이상적인 시나리오라는 점에 주목하세요. 가비지 컬렉션은 일반적으로 활성 객체의 크기에 따라 제한되기 때문입니다.
병렬 Scavenger는 작은 또는 거의 비어 있는 힙에서 최적화된 Cheney 알고리즘에 가까운 성능을 제공하면서 많은 활성 객체로 힙이 커질 경우에도 높은 처리량을 제공하여 이 성능 격차를 해소합니다.
V8은 여러 플랫폼에서 사용을 지원하며, 그 중 하나로 Arm big.LITTLE이 있습니다. 작은 코어에서 작업을 분산하면 배터리 수명을 향상시킬 수 있지만, 작은 코어 작업 패키지가 너무 클 경우 메인 쓰레드에서 정체가 발생할 수 있습니다. 우리는 젊은 세대 가비지 컬렉션의 경우 제한된 페이지 수 때문에 페이지 수준 병렬 처리가 big.LITTLE에서 작업 부하를 균형 있게 하지 못할 수도 있다는 것을 관찰했습니다. Scavenger는 명시적인 작업 목록 및 작업 도둑질을 사용하여 중간 수준의 동기화를 제공함으로써 이러한 문제를 자연스럽게 해결합니다.