Orinoco: recolección de basura para la generación joven
Los objetos de JavaScript en V8 se asignan en un montón administrado por el recolector de basura de V8. En publicaciones anteriores del blog ya hemos hablado sobre cómo reducimos los tiempos de pausa de la recolección de basura (más de una vez) y el consumo de memoria. En esta publicación del blog presentamos el Scavenger paralelo, una de las características más recientes de Orinoco, el recolector de basura principalmente concurrente y paralelo de V8, y discutimos las decisiones de diseño y enfoques alternativos que implementamos en el camino.
V8 divide su montón administrado en generaciones donde los objetos inicialmente se asignan en la “guardería” de la generación joven. Al sobrevivir a una recolección de basura, los objetos se copian a la generación intermedia, que todavía es parte de la generación joven. Después de sobrevivir a otra recolección de basura, estos objetos se mueven a la generación vieja (ver Figura 1). V8 implementa dos recolectores de basura: uno que recopila con frecuencia la generación joven, y otro que recopila el montón completo, incluidas tanto la generación joven como la vieja. Las referencias de la generación vieja a la generación joven son raíces para la recolección de basura de la generación joven. Estas referencias son registradas para proporcionar una identificación eficiente de raíces y actualizaciones de referencias cuando se mueven objetos.

Dado que la generación joven es relativamente pequeña (hasta 16MiB en V8), se llena rápidamente con objetos y requiere recolecciones frecuentes. Hasta la versión M62, V8 utilizaba un recolector de basura de copia con semiespacios de Cheney (ver más abajo) que divide la generación joven en dos mitades. Durante la ejecución de JavaScript, solo una mitad de la generación joven está disponible para asignar objetos, mientras que la otra mitad permanece vacía. Durante una recolección de basura de la generación joven, los objetos vivos se copian de una mitad a la otra, compactando la memoria en el proceso. Los objetos vivos que ya se han copiado una vez se consideran parte de la generación intermedia y se promueven a la generación vieja.
A partir de la versión v6.2, V8 cambió el algoritmo predeterminado de recolección de la generación joven por un Scavenger paralelo, similar al recolector de copia con semiespacios de Halstead con la diferencia de que V8 utiliza trabajo robado dinámicamente en lugar de estáticamente entre múltiples hilos. A continuación, explicamos tres algoritmos: a) el recolector de copia con semiespacios de Cheney de un solo hilo, b) un esquema paralelo de marcado y evacuación, y c) el Scavenger paralelo.
Copia con semiespacios de Cheney de un solo hilo
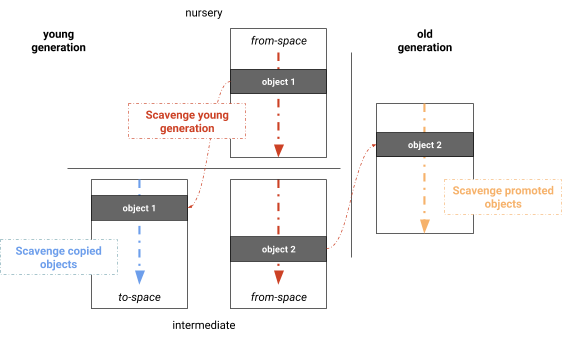
Hasta la versión v6.2, V8 usó el algoritmo de copia con semiespacios de Cheney, que es adecuado tanto para la ejecución en un solo núcleo como para un esquema generacional. Antes de una recolección de la generación joven, ambas mitades del semiespacio de memoria están asignadas y etiquetadas adecuadamente: las páginas que contienen el conjunto actual de objetos se llaman from-space, mientras que las páginas a las que se copian los objetos se llaman to-space.
El Scavenger considera las referencias en la pila de llamadas y las referencias de la generación vieja a la joven como raíces. La Figura 2 ilustra el algoritmo donde inicialmente el Scavenger escanea estas raíces y copia los objetos accesibles en el from-space que aún no se han copiado al to-space. Los objetos que ya han sobrevivido a una recolección de basura se promueven (se mueven) a la generación vieja. Después del escaneo de raíces y la primera ronda de copia, los objetos en el to-space recién asignado se escanean en busca de referencias. De manera similar, todos los objetos promovidos se escanean en busca de nuevas referencias al from-space. Estas tres fases se entrelazan en el hilo principal. El algoritmo continúa hasta que no se encuentren más objetos nuevos accesibles ni desde el to-space ni desde la generación vieja. En este punto, el from-space solo contiene objetos inalcanzables, es decir, solo contiene basura.
![]()
Marcado y evacuación paralelos
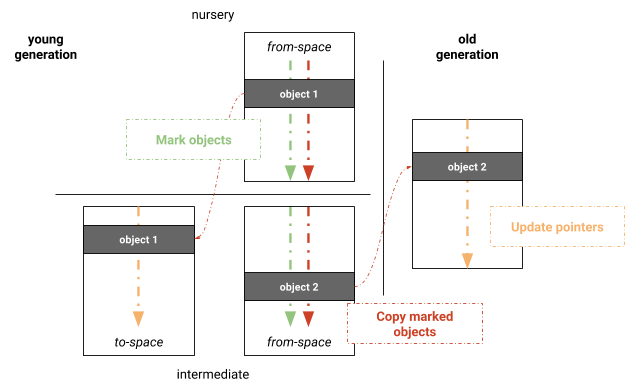
Experimentamos con un algoritmo paralelo de Marcado-Evacuación basado en el recolector completo de Marcado-Barrido-Compactación de V8. La principal ventaja es aprovechar la infraestructura de recolección de basura ya existente del recolector completo de Marcado-Barrido-Compactación. El algoritmo consta de tres fases: marcado, copia y actualización de punteros, como se muestra en la Figura 3. Para evitar barrer páginas en la generación joven para mantener listas libres, la generación joven aún se mantiene utilizando un semiespacio que siempre se mantiene compacto copiando objetos vivos al to-space durante la recolección de basura. Inicialmente, la generación joven se marca en paralelo. Después del marcado, los objetos vivos se copian en paralelo a sus espacios correspondientes. El trabajo se distribuye en función de las páginas lógicas. Los hilos que participan en la copia mantienen sus propios búferes locales de asignación (LABs) que se combinan al terminar la copia. Después de la copia, se aplica el mismo esquema de paralelización para actualizar los punteros entre objetos. Estas tres fases se realizan en pasos sincronizados, es decir, aunque las fases se realizan en paralelo, los hilos deben sincronizarse antes de continuar con la siguiente fase.

Recolección Paralela
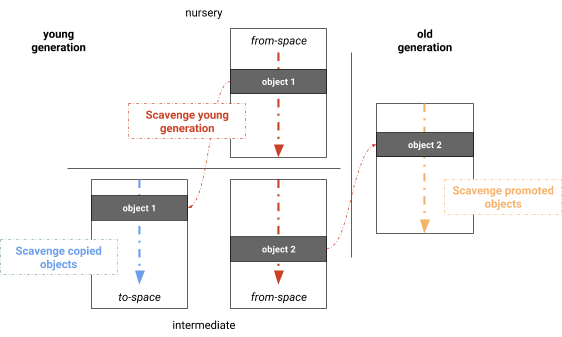
El recolector paralelo de Marcado-Evacuación separa las fases de cálculo de vivacidad, copia de objetos vivos y actualización de punteros. Una optimización evidente es fusionar estas fases, resultando en un algoritmo que marca, copia y actualiza punteros al mismo tiempo. Al fusionar estas fases obtenemos de hecho el Recolector Paralelo utilizado por V8, que es una versión similar al recolector de semiespacio de Halstead con la diferencia de que V8 utiliza robo de trabajo dinámico y un mecanismo simple de balanceo de carga para escanear las raíces (ver Figura 4). Al igual que el algoritmo de Cheney de un solo hilo, las fases son: escanear raíces, copiar dentro de la generación joven, promover a la generación vieja y actualizar punteros. Descubrimos que la mayoría del conjunto raíz suele ser las referencias de la generación vieja a la generación joven. En nuestra implementación, los conjuntos recordados se mantienen por página, lo que distribuye naturalmente el conjunto raíz entre los hilos de recolección de basura. Luego, los objetos se procesan en paralelo. Los objetos recién encontrados se agregan a una lista de trabajo global de la cual los hilos de recolección de basura pueden robar. Esta lista de trabajo proporciona almacenamiento rápido local para tareas, así como almacenamiento global para compartir trabajo. Una barrera asegura que las tareas no terminen prematuramente cuando el subgrafo procesado actualmente no es adecuado para el robo de trabajo (por ejemplo, una cadena lineal de objetos). Todas las fases se realizan en paralelo e intercaladas en cada tarea, maximizando la utilización de las tareas de los trabajadores.

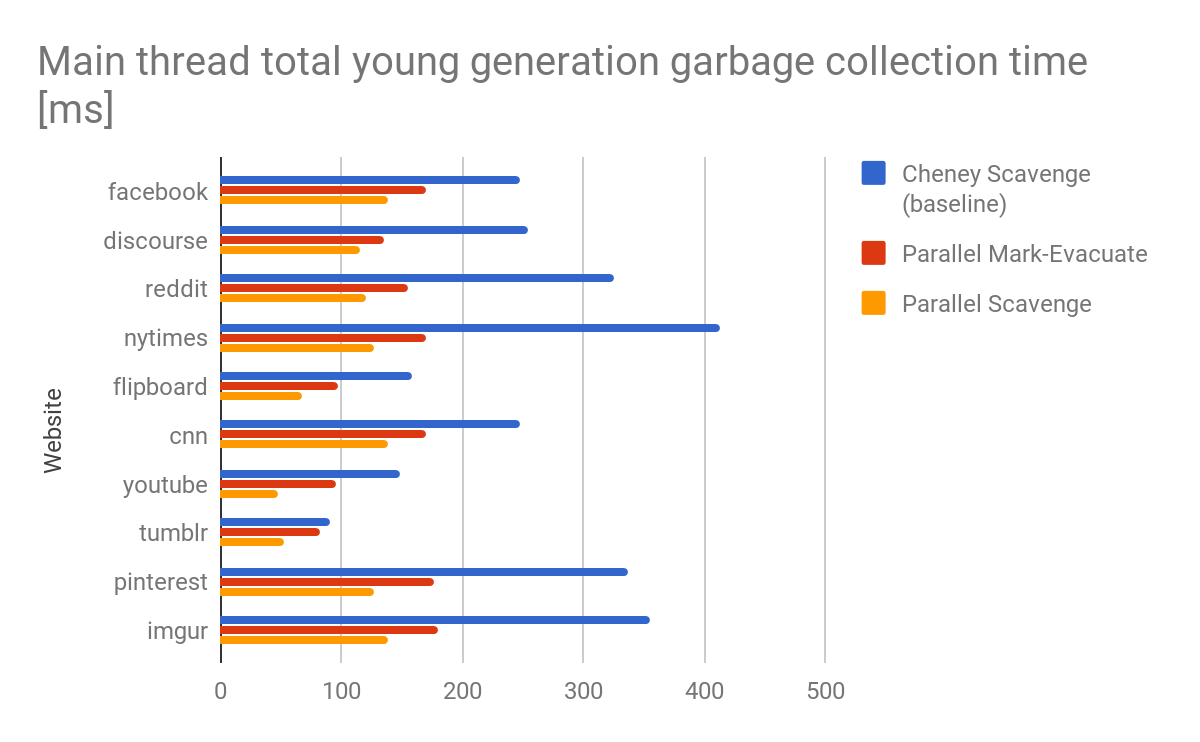
Resultados y resultados
El algoritmo del Recolector fue diseñado inicialmente pensando en el rendimiento óptimo de un solo núcleo. El mundo ha cambiado desde entonces. Los núcleos de CPU son a menudo abundantes, incluso en dispositivos móviles de gama baja. Más importante aún, a menudo estos núcleos están realmente activos. Para aprovechar al máximo estos núcleos, se tuvo que modernizar uno de los últimos componentes secuenciales del recolector de basura de V8, el Recolector.
La gran ventaja de un recolector de Marcado-Evacuación paralelo es que la información exacta de vivacidad está disponible. Esta información se puede utilizar, por ejemplo, para evitar copias simplemente moviendo y relocalizando páginas que contienen principalmente objetos vivos, lo que también realiza el recolector completo de Marcado-Barrido-Compactación. Sin embargo, en la práctica, esto fue observable principalmente en pruebas sintéticas y rara vez apareció en sitios web reales. La desventaja del recolector de Marcado-Evacuación paralelo es el sobrecoste de realizar tres fases separadas sincronizadas. Este sobrecoste es especialmente notable cuando se invoca al recolector de basura en un montón con principalmente objetos muertos, lo cual es el caso en muchas páginas web reales. Cabe destacar que invocar el recolector de basura en montones con principalmente objetos muertos es en realidad el escenario ideal, ya que la recolección de basura suele estar limitada por el tamaño de los objetos vivos.
El Recolector Paralelo cierra esta brecha de rendimiento al proporcionar un rendimiento cercano al algoritmo de Cheney optimizado en montones pequeños o casi vacíos, mientras sigue proporcionando un alto rendimiento en caso de que los montones sean más grandes con muchos objetos vivos.
V8 admite, entre muchas otras plataformas, Arm big.LITTLE. Aunque derivar trabajo en los núcleos pequeños beneficia la duración de la batería, puede llevar a bloqueos en el hilo principal cuando los paquetes de trabajo para los núcleos pequeños son demasiado grandes. Observamos que el paralelismo a nivel de página no necesariamente equilibra la carga de trabajo en big.LITTLE para una recolección de basura de la generación joven debido al número limitado de páginas. El Recolector soluciona naturalmente este problema al proporcionar una sincronización de granularidad media utilizando listas de trabajo explícitas y robo de trabajo.