Orinoco : collecte des déchets de la jeune génération
Les objets JavaScript dans V8 sont alloués sur un tas géré par le collecteur de déchets de V8. Dans des articles de blog précédents, nous avons déjà parlé de la manière dont nous réduisons les temps de pause de la collecte des déchets (plus d'une fois) et la consommation de mémoire. Dans ce billet, nous introduisons le Scavenger parallèle, l'une des dernières fonctionnalités d'Orinoco, le collecteur de déchets principalement concurrent et parallèle de V8, et discutons des décisions de conception et des approches alternatives que nous avons mises en œuvre en cours de route.
V8 partitionne son tas géré en générations où les objets sont initialement alloués dans la « pépinière » de la jeune génération. En survivant à une collecte des déchets, les objets sont copiés dans la génération intermédiaire, qui fait toujours partie de la jeune génération. Après avoir survécu à une autre collecte des déchets, ces objets sont déplacés dans la génération ancienne (voir Figure 1). V8 implémente deux collecteurs de déchets : un qui collecte fréquemment la jeune génération et un qui collecte l’ensemble du tas, y compris les générations jeune et ancienne. Les références de la génération ancienne à la jeune génération sont des racines pour la collecte des déchets de la jeune génération. Ces références sont enregistrées afin de fournir une identification efficace des racines et des mises à jour des références lorsque les objets sont déplacés.

Puisque la jeune génération est relativement petite (jusqu’à 16MiB dans V8), elle se remplit rapidement d’objets et nécessite des collectes fréquentes. Jusqu’à la version M62, V8 utilisait un collecteur de déchets Cheney en espace semi-copiant (voir ci-dessous) qui divise la jeune génération en deux moitiés. Pendant l’exécution de JavaScript, une seule moitié de la jeune génération est disponible pour l’allocation d’objets, tandis que l’autre moitié reste vide. Lors d’une collecte de jeunes déchets, les objets vivants sont copiés d’une moitié à l’autre, compactant la mémoire sur le champ. Les objets vivants qui ont déjà été copiés une fois sont considérés comme faisant partie de la génération intermédiaire et sont promus dans la génération ancienne.
À partir de la version 6.2, V8 a adopté comme algorithme par défaut pour collecter la jeune génération un Scavenger parallèle, similaire à l’espace semi-copiant de Halstead, avec la différence que V8 utilise un vol de travail dynamique au lieu d’utiliser un vol statique entre plusieurs threads. Dans ce qui suit, nous expliquons trois algorithmes : a) le collecteur Cheney en espace semi-copiant monothread, b) un schéma parallèle de marquage-évacuation et c) le Scavenger parallèle.
Copie en espace semi par Cheney à thread unique
Jusqu’à la version 6.2, V8 utilisait l’algorithme en espace semi-copiant de Cheney qui convient bien tant à l’exécution monocœur qu’à un schéma générationnel. Avant une collecte de la jeune génération, les deux moitiés de l’espace semi de la mémoire sont allouées et affectées avec des étiquettes appropriées : les pages contenant l’ensemble actuel des objets sont appelées espace source tandis que les pages vers lesquelles les objets sont copiés sont appelées espace cible.
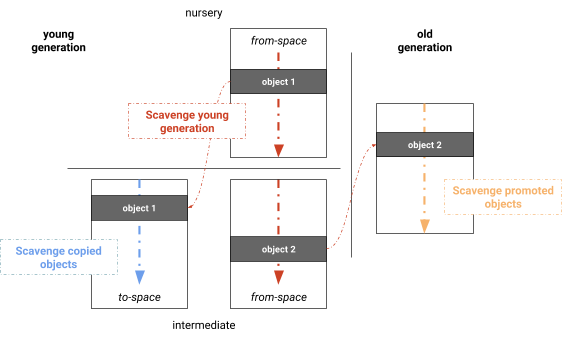
Le Scavenger considère les références dans la pile des appels et les références de l’ancienne génération à la jeune génération comme des racines. La Figure 2 illustre l’algorithme où initialement le Scavenger explore ces racines et copie les objets accessibles dans l’espace source n’ayant pas encore été copiés vers l’espace cible. Les objets qui ont déjà survécu à une collecte des déchets sont promus (déplacés) dans la génération ancienne. Après l’exploration des racines et la première série de copies, les objets dans l’espace cible nouvellement alloué sont explorés pour trouver des références. De manière similaire, tous les objets promus sont explorés pour découvrir de nouvelles références à l’espace source. Ces trois phases sont intercalées sur le thread principal. L’algorithme continue jusqu’à ce que plus aucun objet nouveau ne soit accessible depuis l’espace cible ou la génération ancienne. À ce stade, l’espace source ne contient que des objets inaccessibles, c’est-à-dire qu’il ne contient que des déchets.
![]()
Marquage-Évacuation parallèle
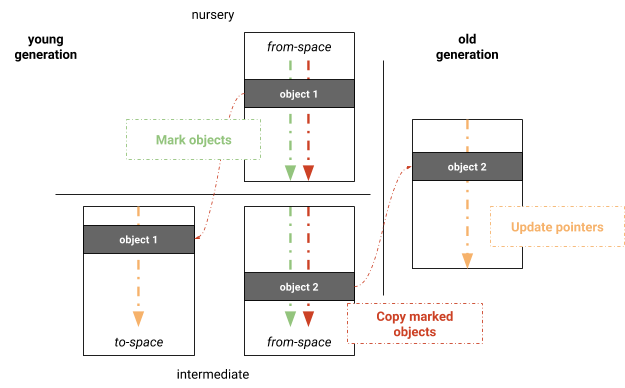
Nous avons expérimenté un algorithme parallèle de Marquage-Évacuation basé sur le collecteur complet Marquage-Balayage-Compactage de V8. L'avantage principal est de tirer parti de l'infrastructure de collecte des déchets déjà existante du collecteur complet Marquage-Balayage-Compactage. L'algorithme consiste en trois phases : marquage, copie et mise à jour des pointeurs, comme illustré sur la Figure 3. Pour éviter le balayage des pages dans la jeune génération afin de maintenir les listes libres, la jeune génération est encore maintenue à l'aide d'un semi-espace qui est toujours compacté en copiant les objets vivants dans l'espace cible lors de la collecte des déchets. La jeune génération est initialement marquée en parallèle. Après le marquage, les objets vivants sont copiés en parallèle dans leurs espaces correspondants. Le travail est distribué en fonction des pages logiques. Les threads participant à la copie conservent leurs propres tampons locaux d'allocation (LABs) qui sont fusionnés après la copie. Après la copie, le même schéma de parallélisation est appliqué pour la mise à jour des pointeurs inter-objets. Ces trois phases sont effectuées de manière synchrone, c'est-à-dire que bien que les phases elles-mêmes soient réalisées en parallèle, les threads doivent se synchroniser avant de passer à la phase suivante.

Ébouage Parallèle
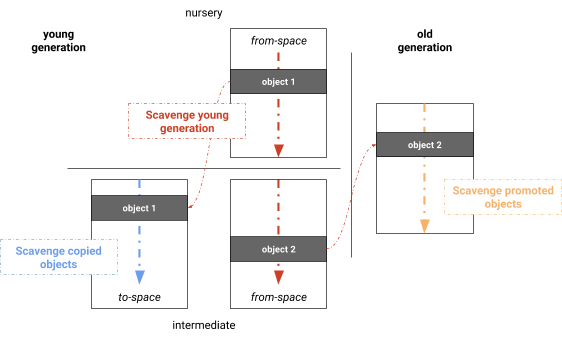
Le collecteur de Marquage-Évacuation parallèle sépare les phases de calcul de la vivacité, de copie des objets vivants et de mise à jour des pointeurs. Une optimisation évidente consiste à fusionner ces phases, aboutissant à un algorithme qui marque, copie et met à jour les pointeurs en même temps. En fusionnant ces phases, nous obtenons en fait l'éboueur parallèle utilisé par V8, qui est une version similaire au collecteur de semi-espace de Halstead avec la différence que V8 utilise un vol de travail dynamique et un mécanisme simple d'équilibrage de charge pour scanner les racines (voir Figure 4). Comme l'algorithme mono-thread de Cheney, les phases sont : scanner les racines, copier dans la jeune génération, promouvoir vers la vieille génération et mettre à jour les pointeurs. Nous avons constaté que la majorité de l'ensemble racine est habituellement composée des références de la vieille génération vers la jeune génération. Dans notre implémentation, des ensembles mémorisés sont maintenus par page, ce qui distribue naturellement l'ensemble des racines parmi les threads de collecte des déchets. Les objets sont ensuite traités en parallèle. Les objets trouvés récemment sont ajoutés à une liste de tâches globale à partir de laquelle les threads de collecte des déchets peuvent voler. Cette liste de tâches offre un stockage local rapide pour les tâches ainsi qu'un stockage global pour le partage du travail. Une barrière garantit que les tâches ne s'arrêtent pas prématurément lorsque le sous-graphe actuellement traité ne convient pas au vol de travail (par exemple, une chaîne linéaire d'objets). Toutes les phases sont effectuées en parallèle et entrelacées sur chaque tâche, maximisant l'utilisation des tâches de travail.

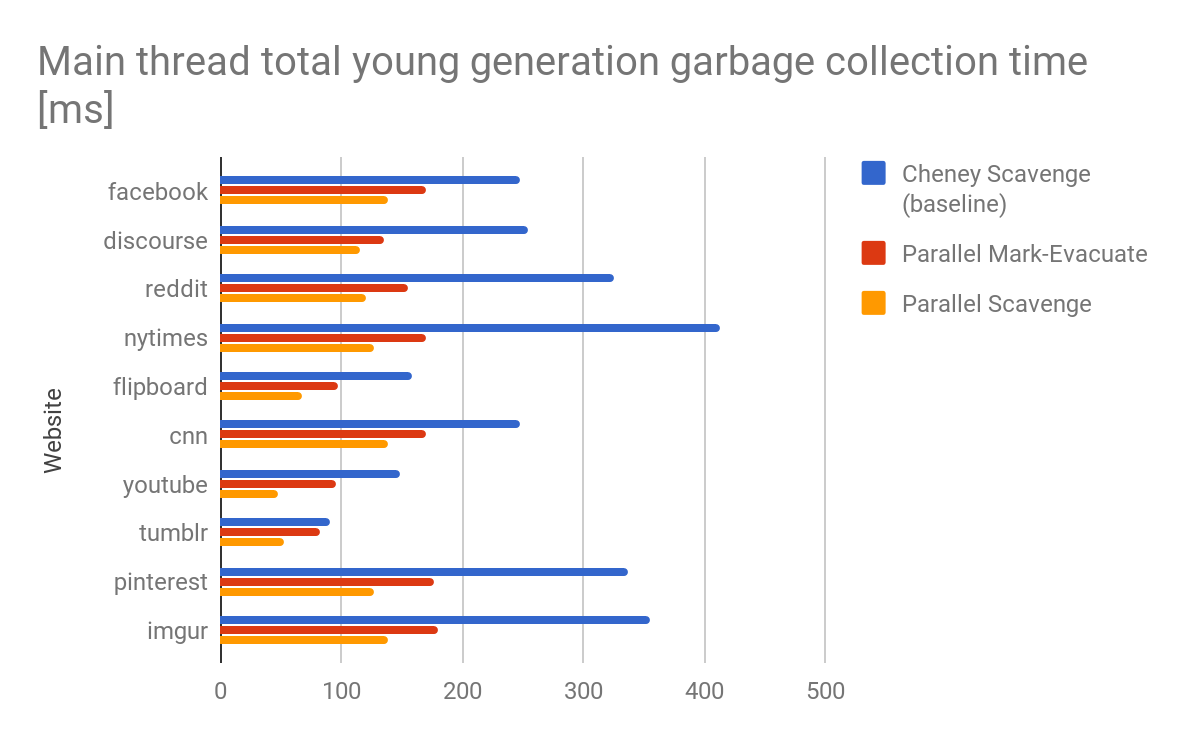
Résultats et conclusions
L'algorithme Scavenger a été initialement conçu en ayant en tête une performance optimale pour un seul cœur. Depuis, les choses ont changé. Les cœurs de CPU sont souvent nombreux, même sur des appareils mobiles d'entrée de gamme. Plus important encore, souvent, ces cœurs sont effectivement actifs. Pour tirer pleinement parti de ces cœurs, l'un des derniers composants séquentiels du collecteur de déchets de V8, le Scavenger, devait être modernisé.
Le grand avantage d'un collecteur de Marquage-Évacuation parallèle est que des informations de vivacité exactes sont disponibles. Ces informations peuvent par exemple être utilisées pour éviter complètement la copie en déplaçant et en réliant simplement les pages contenant principalement des objets vivants, ce qui est également effectué par le collecteur complet Marquage-Balayage-Compactage. En pratique, toutefois, cela a été principalement observable sur des benchmarks synthétiques et est rarement apparu sur de véritables sites Web. L'inconvénient du collecteur de Marquage-Évacuation parallèle est la surcharge liée à l'exécution de trois phases distinctes synchronisées. Cette surcharge est particulièrement perceptible lorsque le collecteur de déchets est invoqué sur un tas contenant principalement des objets morts, ce qui est le cas sur de nombreuses pages Web réelles. Notez que l'invocation de la collecte des déchets sur des tas contenant principalement des objets morts est en fait le scénario idéal, car la collecte des déchets est habituellement limitée par la taille des objets vivants.
Le Scavenger parallèle comble cet écart de performance en offrant une performance proche de l'algorithme optimisé de Cheney sur des tas petits ou presque vides tout en garantissant un débit élevé si les tas deviennent plus grands avec de nombreux objets vivants.
V8 prend en charge, parmi de nombreuses autres plateformes, Arm big.LITTLE. Bien que déléguer le travail sur des petits cœurs bénéficie à la durée de vie de la batterie, cela peut entraîner un blocage du thread principal lorsque les paquets de travail pour les petits cœurs sont trop volumineux. Nous avons observé que le parallélisme au niveau des pages n'équilibre pas nécessairement la charge de manière efficace sur big.LITTLE pour une collecte de déchets de la jeune génération en raison du nombre limité de pages. Le Scavenger résout naturellement ce problème en fournissant une synchronisation à granularité moyenne en utilisant des listes de tâches explicites et le vol de travail.