Orinoco: coleta de lixo da geração jovem
Os objetos JavaScript no V8 são alocados em um heap gerenciado pelo coletor de lixo do V8. Em postagens anteriores no blog, já falamos sobre como reduzir os tempos de pausa na coleta de lixo (mais de uma vez) e o consumo de memória. Nesta postagem, apresentamos o Scavenger paralelo, um dos últimos recursos do Orinoco, o coletor de lixo majoritariamente concorrente e paralelo do V8, e discutimos decisões de design e abordagens alternativas que implementamos ao longo do caminho.
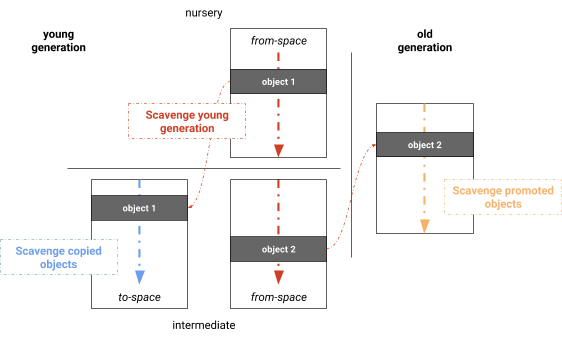
O V8 particiona seu heap gerenciado em gerações, onde os objetos são inicialmente alocados no “berçário” da geração jovem. Ao sobreviver a uma coleta de lixo, os objetos são copiados para a geração intermediária, que ainda é parte da geração jovem. Após sobreviverem a outra coleta de lixo, esses objetos são movidos para a geração antiga (veja a Figura 1). O V8 implementa dois coletores de lixo: um que coleta frequentemente a geração jovem e outro que coleta o heap completo, incluindo tanto a geração jovem quanto a antiga. Referências da geração antiga para a geração jovem são raízes para a coleta de lixo da geração jovem. Essas referências são registradas para fornecer identificação eficiente de raízes e atualizações de referências quando os objetos são movidos.

Como a geração jovem é relativamente pequena (até 16MiB no V8), ela se enche rapidamente com objetos e requer coletas frequentes. Até o M62, o V8 usava um coletor de lixo de cópia Cheney semiespaço (veja abaixo) que divide a geração jovem em duas metades. Durante a execução do JavaScript, apenas uma metade da geração jovem está disponível para alocar objetos, enquanto a outra metade permanece vazia. Durante uma coleta de lixo jovem, os objetos vivos são copiados de uma metade para a outra, compactando a memória dinamicamente. Objetos vivos que já foram copiados uma vez são considerados parte da geração intermediária e são promovidos para a geração antiga.
A partir da versão 6.2, o V8 alterou o algoritmo padrão para coletar a geração jovem para um Scavenger paralelo, semelhante ao coletor de cópia semiespaço de Halstead, com a diferença de que o V8 usa roubo de trabalho dinâmico, em vez de estático, em múltiplos threads. A seguir, explicamos três algoritmos: a) o coletor de cópia semiespaço Cheney de único thread, b) um esquema paralelo Marcar-Evacuador e c) o Scavenger paralelo.
Cópia Semiespaço Cheney de Único Thread
Até a versão 6.2, o V8 usava o algoritmo de cópia semiespaço de Cheney, que é bem adequado tanto para execução em um único núcleo quanto para um esquema geracional. Antes de uma coleta de geração jovem, ambas as metades do semiespaço de memória são comprometidas e recebem rótulos apropriados: as páginas que contêm o conjunto atual de objetos são chamadas de espaço de origem, enquanto as páginas para onde os objetos são copiados são chamadas de espaço de destino.
O Scavenger considera referências na pilha de chamadas e referências da geração antiga para a geração jovem como raízes. A Figura 2 ilustra o algoritmo, onde inicialmente o Scavenger escaneia essas raízes e copia objetos acessíveis no espaço de origem que ainda não foram copiados para o espaço de destino. Objetos que já sobreviveram a uma coleta de lixo são promovidos (movidos) para a geração antiga. Após o escaneamento de raízes e a primeira rodada de cópia, os objetos no espaço de destino recém-alocado são escaneados para referências. Da mesma forma, todos os objetos promovidos são escaneados em busca de novas referências ao espaço de origem. Essas três fases se entrelaçam no thread principal. O algoritmo continua até que nenhum novo objeto esteja acessível a partir do espaço de destino ou da geração antiga. Neste ponto, o espaço de origem contém apenas objetos inacessíveis, ou seja, apenas lixo.
![]()
Marcar-Evacuador Paralelo
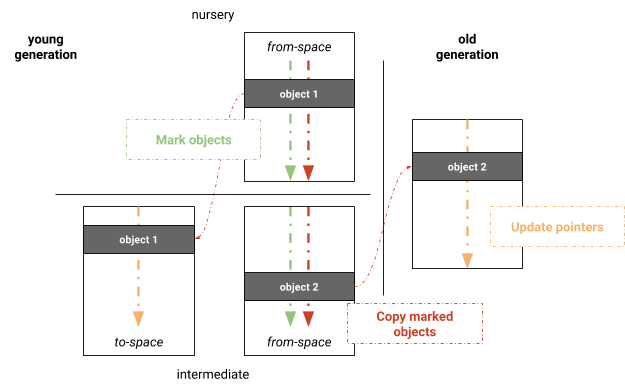
Nós experimentamos um algoritmo paralelo de Mark-Evacuate baseado no coletor completo Mark-Sweep-Compact do V8. A principal vantagem é aproveitar a infraestrutura de coleta de lixo já existente do coletor completo Mark-Sweep-Compact. O algoritmo consiste em três fases: marcação, cópia e atualização de ponteiros, conforme mostrado na Figura 3. Para evitar varrer páginas na geração jovem para manter listas livres, a geração jovem ainda é mantida usando um semiespaço que é sempre mantido compacto ao copiar objetos vivos para o to-space durante a coleta de lixo. Inicialmente, a geração jovem é marcada em paralelo. Após a marcação, os objetos vivos são copiados em paralelo para seus espaços correspondentes. O trabalho é distribuído com base em páginas lógicas. Os threads que participam da cópia mantêm seus próprios buffers locais de alocação (LABs), que são mesclados ao término da cópia. Após a cópia, o mesmo esquema de paralelização é aplicado para atualizar os ponteiros entre objetos. Essas três fases são realizadas em etapas sincronizadas, ou seja, enquanto as próprias fases são realizadas em paralelo, os threads precisam se sincronizar antes de continuar para a próxima fase.

Coleta Paralela
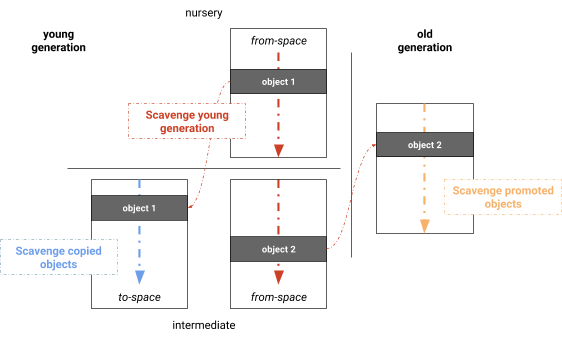
O coletor paralelo Mark-Evacuate separa as fases de cálculo de vivacidade, cópia de objetos vivos e atualização de ponteiros. Uma otimização óbvia é mesclar essas fases, resultando em um algoritmo que marca, copia e atualiza os ponteiros ao mesmo tempo. Ao mesclar essas fases, obtemos o Scavenger paralelo usado pelo V8, que é uma versão semelhante ao coletor semiespaço de Halstead, com a diferença de que o V8 usa roubo de trabalho dinâmico e um mecanismo simples de balanceamento de carga para escanear as raízes (ver Figura 4). Como no algoritmo de Cheney single-threaded, as fases são: escanear as raízes, copiar dentro da geração jovem, promover para a geração antiga e atualizar os ponteiros. Descobrimos que a maioria do conjunto de raízes geralmente são referências da geração antiga para a geração jovem. Na nossa implementação, conjuntos registrados são mantidos por página, o que distribui naturalmente o conjunto de raízes entre os threads de coleta de lixo. Os objetos são então processados em paralelo. Objetos recém-encontrados são adicionados a uma lista de trabalho global da qual os threads de coleta de lixo podem roubar. Essa lista de trabalho fornece armazenamento rápido de tarefas locais, bem como armazenamento global para compartilhamento de trabalho. Uma barreira garante que as tarefas não terminem prematuramente quando o subgrafo atualmente processado não for adequado para roubo de trabalho (por exemplo, uma cadeia linear de objetos). Todas as fases são realizadas em paralelo e intercaladas em cada tarefa, maximizando a utilização de tarefas trabalhadoras.

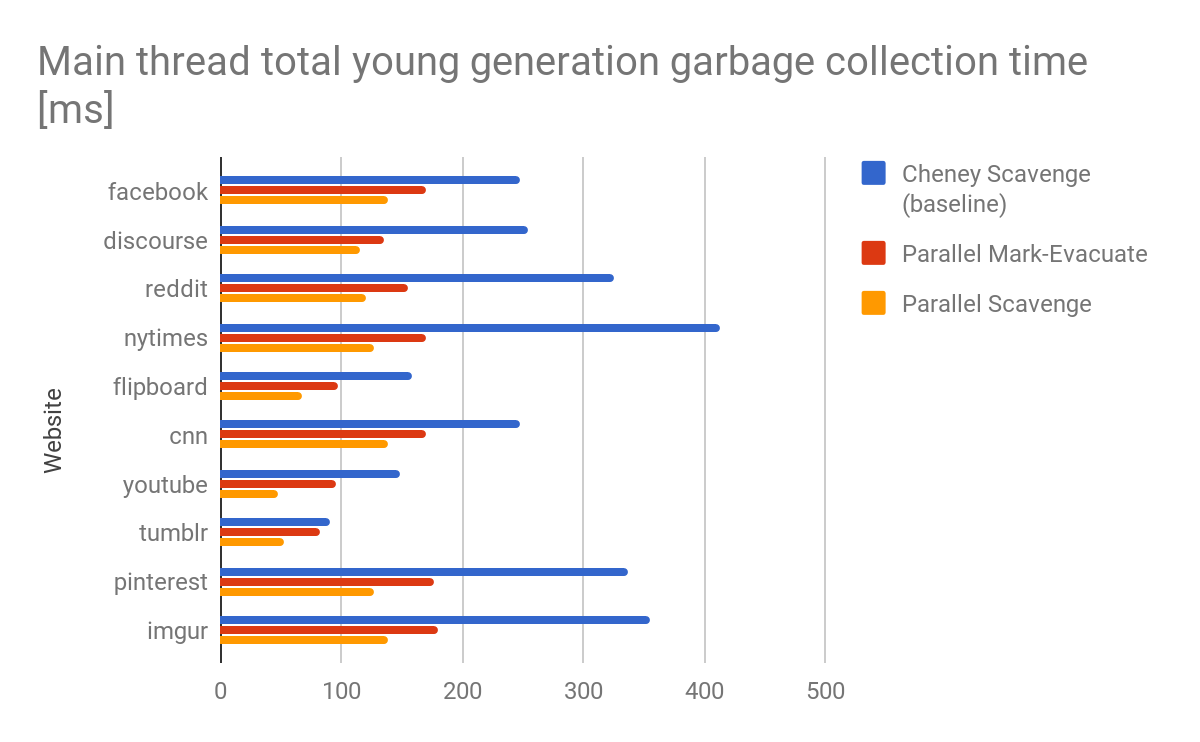
Resultados e Desfecho
O algoritmo Scavenger foi inicialmente projetado com a ideia de desempenho ideal para um único núcleo. O mundo mudou desde então. Os núcleos de CPU são frequentemente abundantes, mesmo em dispositivos móveis de baixo custo. Mais importante, frequentemente esses núcleos estão realmente em operação. Para utilizar totalmente esses núcleos, um dos últimos componentes sequenciais do coletor de lixo do V8, o Scavenger, teve que ser modernizado.
A grande vantagem de um coletor paralelo Mark-Evacuate é que informações exatas de vivacidade estão disponíveis. Essas informações podem, por exemplo, ser usadas para evitar cópias completamente, movendo e relinkando páginas que contêm principalmente objetos vivos, processo que também é realizado pelo coletor completo Mark-Sweep-Compact. Na prática, no entanto, isso foi observado principalmente em benchmarks sintéticos e raramente apareceu em sites reais. A desvantagem do coletor paralelo Mark-Evacuate é a sobrecarga de realizar três fases sincronizadas separadas. Essa sobrecarga é especialmente notável quando o coletor de lixo é invocado em um heap com principalmente objetos mortos, o que é o caso em muitas páginas da web reais. Observe que invocar coletas de lixo em heaps com principalmente objetos mortos é, na verdade, o cenário ideal, já que a coleta de lixo geralmente é limitada pela quantidade de objetos vivos.
O Scavenger paralelo fecha essa lacuna de desempenho ao fornecer uma performance próxima ao algoritmo otimizado de Cheney em heaps pequenos ou quase vazios, enquanto ainda oferece alta taxa de transferência no caso de heaps maiores com muitos objetos vivos.
O V8 suporta, entre muitas outras plataformas, como Arm big.LITTLE. Embora delegar trabalho para núcleos menores beneficie a duração da bateria, isso pode levar a paralisações na thread principal quando pacotes de trabalho para núcleos menores são muito grandes. Observamos que o paralelismo ao nível de página não necessariamente balanceia o trabalho em big.LITTLE para uma coleta de lixo de geração jovem devido ao número limitado de páginas. O Scavenger naturalmente resolve esse problema ao fornecer sincronização de granularidade média usando listas de trabalho explícitas e roubo de trabalho.