Cache de código para desenvolvedores JavaScript
O cache de código (também conhecido como cache de bytecode) é uma otimização importante nos navegadores. Ele reduz o tempo de inicialização de websites frequentemente visitados ao armazenar o resultado da análise e compilação. A maioria dos navegadores populares implementa alguma forma de cache de código, e o Chrome não é exceção. Na verdade, nós já escrevemos, e falamos sobre como o Chrome e o V8 armazenam em cache o código compilado no passado.
Neste post do blog, oferecemos alguns conselhos para desenvolvedores de JS que querem fazer o melhor uso do cache de código para melhorar a inicialização de seus websites. Este conselho se concentra na implementação do cache no Chrome/V8, mas a maior parte dele é transferível para as implementações de cache de código de outros navegadores também.
Recapitulação do cache de código
Enquanto outros posts no blog e apresentações oferecem mais detalhes sobre nossa implementação de cache de código, vale a pena fazer uma breve recapitulação de como as coisas funcionam. O Chrome possui dois níveis de cache para código compilado pelo V8 (tanto scripts clássicos quanto scripts de módulo): um cache em memória de “melhor esforço” de baixo custo mantido pelo V8 (o cache Isolate), e um cache completo serializado no disco.
O cache Isolate opera em scripts compilados no mesmo Isolate do V8 (ou seja, mesmo processo, aproximadamente “as páginas do mesmo website ao navegar na mesma aba”). É de “melhor esforço” no sentido de que tenta ser o mais rápido e minimalista possível, usando dados já disponíveis para nós, ao custo de uma taxa de acerto potencialmente menor e falta de cache entre processos.
- Quando o V8 compila um script, o bytecode compilado é armazenado em uma tabela hash (na heap do V8), indexada pelo código-fonte do script.
- Quando o Chrome solicita ao V8 para compilar outro script, o V8 primeiro verifica se o código-fonte desse script corresponde a algo nesta tabela hash. Se sim, simplesmente retornamos o bytecode existente.
Esse cache é rápido e efetivamente gratuito, no entanto, observamos uma taxa de acerto de 80% no mundo real.
O cache de código em disco é gerenciado pelo Chrome (especificamente pelo Blink), e preenche a lacuna que o cache Isolate não consegue: compartilhar caches de código entre processos e entre sessões múltiplas do Chrome. Ele aproveita o cache de recursos HTTP existente, que gerencia o armazenamento e o vencimento de dados recebidos da web.
- Quando um arquivo JS é solicitado pela primeira vez (ou seja, uma execução a frio), o Chrome o baixa e o entrega ao V8 para compilar. Ele também armazena o arquivo no cache em disco do navegador.
- Quando o arquivo JS é solicitado uma segunda vez (ou seja, uma execução morna), o Chrome pega o arquivo do cache do navegador e, mais uma vez, o entrega ao V8 para compilar. Desta vez, no entanto, o código compilado é serializado e anexado ao arquivo de script em cache como metadados.
- Na terceira vez (ou seja, uma execução quente), o Chrome pega tanto o arquivo quanto os metadados do cache e entrega ambos ao V8. O V8 desserializa os metadados e pode pular a etapa de compilação.
Em resumo:

Com base nessa descrição, podemos dar nossas melhores dicas para melhorar o uso dos caches de código em seu website.
Dica 1: não faça nada
Idealmente, a melhor coisa que você, como desenvolvedor de JS, pode fazer para melhorar o cache de código é “nada”. Isso na verdade significa duas coisas: não fazer nada passivamente e não fazer nada ativamente.
O cache de código é, no final das contas, um detalhe de implementação do navegador; uma otimização baseada em heurísticas de comércio entre dados/espaço, cuja implementação e heurísticas podem (e com certeza vão!) mudar regularmente. Nós, como engenheiros do V8, fazemos o nosso melhor para que essas heurísticas funcionem para todos na web em evolução, e otimizar excessivamente para os detalhes atuais de implementação de cache de código pode causar decepção após algumas versões, quando esses detalhes mudarem. Além disso, outros motores de JavaScript provavelmente têm heurísticas diferentes para a implementação de cache de código. Então, de muitas maneiras, nosso melhor conselho para conseguir que o código seja armazenado em cache é como nosso conselho para escrever JS: escreva um código limpo e idiomático, e faremos o nosso melhor para otimizar como o armazenamos em cache.
Além de não fazer nada passivamente, você também deve se esforçar ao máximo para não fazer nada ativamente. Qualquer forma de cache é inerentemente dependente de as coisas não mudarem, portanto, não fazer nada é a melhor maneira de permitir que os dados em cache permaneçam em cache. Existem algumas maneiras de você não fazer nada ativamente.
Não altere o código
Isso pode ser óbvio, mas vale a pena explicitar — sempre que você enviar um novo código, esse código ainda não está em cache. Sempre que o navegador faz uma solicitação HTTP para uma URL de script, ele pode incluir a data da última busca dessa URL e, se o servidor souber que o arquivo não foi alterado, ele pode enviar uma resposta 304 Not Modified, que mantém nosso cache de código ativo. Caso contrário, uma resposta 200 OK atualiza nosso recurso em cache e limpa o cache de código, revertendo-o para um estado frio.

É tentador sempre enviar suas últimas alterações de código imediatamente, especialmente se você quiser medir o impacto de uma determinada alteração, mas para os caches é muito melhor deixar o código como está, ou pelo menos atualizá-lo o menor número de vezes possível. Considere impor um limite de ≤ x implantações por semana, onde x é o controle deslizante que você pode ajustar para equilibrar cache vs. desatualização.
Não altere as URLs
Os caches de código estão (atualmente) associados ao URL de um script, pois isso os torna fáceis de localizar sem a necessidade de ler o conteúdo real do script. Isso significa que alterar a URL de um script (incluindo quaisquer parâmetros de consulta!) cria uma nova entrada de recurso em nosso cache de recursos e, com ela, uma nova entrada de cache frio.
É claro que isso também pode ser usado para forçar a limpeza do cache, embora isso também seja um detalhe de implementação; podemos, um dia, decidir associar os caches ao texto-fonte em vez do URL-fonte, e este conselho não será mais válido.
Não altere o comportamento de execução
Uma das otimizações mais recentes para nossa implementação de cache de código é apenas serializar o código compilado após ele ser executado. Isso é para tentar capturar funções compiladas de forma preguiçosa, que são compiladas somente durante a execução, não durante a compilação inicial.
Essa otimização funciona melhor quando cada execução do script executa o mesmo código ou pelo menos as mesmas funções. Isso pode ser um problema se, por exemplo, você tiver testes A/B que dependam de uma decisão em tempo de execução:
if (Math.random() > 0.5) {
A();
} else {
B();
}
Nesse caso, somente A() ou B() é compilado e executado na execução quente e adicionado ao cache de código, embora qualquer um dos dois possa ser executado em execuções subsequentes. Em vez disso, tente manter sua execução determinística para mantê-la no caminho em cache.
Dica 2: faça algo
Certamente, o conselho de “não fazer nada”, seja passivamente ou ativamente, não é muito satisfatório. Portanto, além de “não fazer nada”, dadas as nossas heurísticas e implementação atuais, há algumas coisas que você pode fazer. No entanto, lembre-se de que heurísticas podem mudar, este conselho pode mudar e não há substituto para o profiling.

Separe bibliotecas do código que as usa
O cache de código é feito em uma base grosseira, por script, o que significa que alterações em qualquer parte do script invalidam o cache de todo o script. Se o código enviado consiste em partes estáveis e mutáveis em um único script, por exemplo, bibliotecas e lógica de negócios, então alterações na lógica de negócios invalidam o cache do código da biblioteca.
Em vez disso, você pode separar o código de biblioteca estável em um script separado e incluí-lo separadamente. Assim, o código da biblioteca pode ser armazenado em cache uma vez e permanecer em cache quando a lógica de negócios mudar.
Isso tem benefícios adicionais se as bibliotecas forem compartilhadas em diferentes páginas do seu site: como o cache de código está associado ao script, o cache de código para as bibliotecas também é compartilhado entre as páginas.
Mescle bibliotecas com o código que as usa
O cache de código é feito após a execução de cada script, o que significa que o cache de código de um script incluirá exatamente as funções nesse script que foram compiladas quando a execução do script for concluída. Isso tem várias consequências importantes para o código da biblioteca:
- O cache de código não incluirá funções de scripts anteriores.
- O cache de código não incluirá funções compiladas preguiçosamente chamadas por scripts posteriores.
Em particular, se uma biblioteca consistir inteiramente de funções compiladas preguiçosamente, essas funções não serão armazenadas em cache, mesmo que sejam usadas posteriormente.
Uma solução para isso é mesclar bibliotecas e seus usos em um único script, de modo que o cache de código "veja" quais partes da biblioteca são usadas. Infelizmente, isso é o oposto exato do conselho acima, porque não existem soluções mágicas. Em geral, não recomendamos a fusão de todos os seus scripts JS em um único pacote grande; dividi-los em vários scripts menores tende a ser mais benéfico no geral por razões que vão além do cache de código (por exemplo, várias solicitações de rede, compilação em fluxo, interatividade da página, etc.).
Aproveite as heurísticas de IIFE
Somente as funções que são compiladas no momento em que o script termina de executar contam para o cache de código, então há muitos tipos de funções que não serão armazenadas em cache, apesar de serem executadas em algum momento posterior. Manipuladores de eventos (mesmo onload), cadeias de promessas, funções de biblioteca não utilizadas e qualquer outra coisa que seja compilada de forma preguiçosa sem ser chamada até </script> ser visto, permanecem preguiçosas e não são armazenadas em cache.
Uma maneira de forçar o armazenamento em cache dessas funções é forçando a compilação, e uma maneira comum de forçá-la é usando as heurísticas de IIFE. IIFEs (expressões de função invocadas imediatamente) são um padrão onde uma função é chamada imediatamente após ser criada:
(function foo() {
// …
})();
Como as IIFEs são chamadas imediatamente, a maioria dos mecanismos de JavaScript tenta detectá-las e compilá-las imediatamente, para evitar o custo da compilação preguiçosa seguida pela compilação completa. Existem várias heurísticas para detectar IIFEs cedo (antes que a função tenha que ser analisada), a mais comum sendo um ( antes da palavra-chave function.
Como essa heurística é aplicada cedo, ela dispara uma compilação mesmo que a função não seja realmente invocada imediatamente:
const foo = function() {
// Ignorada preguiçosamente
};
const bar = (function() {
// Compilada com antecedência
});
Isso significa que funções que deveriam estar no cache de código podem ser forçadas nele ao serem envolvidas entre parênteses. No entanto, isso pode prejudicar o tempo de inicialização se a dica for aplicada incorretamente e, em geral, isso é um uso inadequado das heurísticas, portanto, nossa recomendação é evitar fazer isso, a menos que seja necessário.
Agrupar arquivos pequenos
O Chrome possui um tamanho mínimo para caches de código, atualmente definido em 1 KiB de código-fonte. Isso significa que scripts menores não são armazenados em cache, já que consideramos os custos indiretos maiores que os benefícios.
Caso seu site possua muitos desses scripts pequenos, o cálculo de custos indiretos pode não se aplicar da mesma maneira. Considere mesclar esses scripts para que ultrapassem o tamanho mínimo de código e também se beneficiem da redução geral dos custos indiretos dos scripts.
Evite scripts inline
Tags de script cujo conteúdo está embutido no HTML não têm um arquivo de origem externo associado, e, portanto, não podem ser armazenadas em cache pelo mecanismo acima. O Chrome tenta armazenar scripts inline em cache, anexando o cache ao recurso do documento HTML, mas esses caches dependem que o documento HTML inteiro não seja alterado e não são compartilhados entre páginas.
Portanto, para scripts não triviais que poderiam se beneficiar do cache de código, evite inseri-los diretamente no HTML e prefira incluí-los como arquivos externos.
Use caches de service worker
Os service workers são um mecanismo para que seu código intercepte solicitações de rede para recursos em sua página. Em particular, eles permitem que você construa um cache local de alguns de seus recursos e sirva o recurso do cache sempre que forem solicitados. Isso é particularmente útil para páginas que precisam continuar funcionando offline, como PWAs.
Um exemplo típico de um site usando um service worker é registrar o service worker em algum arquivo de script principal:
// main.mjs
navigator.serviceWorker.register('/sw.js');
E o service worker adiciona manipuladores de eventos para instalação (criando um cache) e busca (fornecendo recursos, potencialmente do cache).
// sw.js
self.addEventListener('install', (event) => {
async function buildCache() {
const cache = await caches.open(cacheName);
return cache.addAll([
'/main.css',
'/main.mjs',
'/offline.html',
]);
}
event.waitUntil(buildCache());
});
self.addEventListener('fetch', (event) => {
async function cachedFetch(event) {
const cache = await caches.open(cacheName);
let response = await cache.match(event.request);
if (response) return response;
response = await fetch(event.request);
cache.put(event.request, response.clone());
return response;
}
event.respondWith(cachedFetch(event));
});
Esses caches podem incluir recursos JS armazenados em cache. No entanto, temos heurísticas ligeiramente diferentes para eles, uma vez que podemos fazer suposições diferentes. Como o cache do service worker segue as regras de armazenamento gerenciado por cotas, é mais provável que seja preservado por mais tempo e o benefício do armazenamento em cache será maior. Além disso, podemos inferir maior importância dos recursos quando eles são pré-cacheados antes do carregamento.
As maiores diferenças heurísticas ocorrem quando o recurso é adicionado ao cache do service worker durante o evento de instalação do service worker. O exemplo acima demonstra tal uso. Nesse caso, o cache de código é criado imediatamente quando o recurso é colocado no cache do service worker. Além disso, geramos um cache de código "completo" para esses scripts - não compilamos mais funções de forma preguiçosa, mas sim compilamos tudo e colocamos no cache. Isso tem a vantagem de ter um desempenho rápido e previsível, sem dependências de ordem de execução, embora com o custo de um maior uso de memória.
Se um recurso JS for armazenado via a API Cache fora do evento de instalação do service worker, o cache de código não será gerado imediatamente. Em vez disso, se um service worker responder com essa resposta do cache, o "cache de código normal" será gerado na primeira carga. Esse cache de código estará então disponível para consumo na segunda carga; uma carga mais rápido do que no cenário típico de cache de código. Recursos podem ser armazenados na API Cache fora do evento de instalação ao "progrressivamente" armazenar em cache recursos no evento de busca ou se a API Cache for atualizada a partir da janela principal em vez do service worker.
Observe que o cache de código "completo" pré-cacheado pressupõe que a página onde o script será executado usará codificação UTF-8. Se a página acabar usando uma codificação diferente, o cache de código será descartado e substituído por um "cache de código normal".
Além disso, o cache de código "completo" pré-cacheado pressupõe que a página carregará o script como um script clássico de JS. Se a página acabar carregando como um módulo ES, o cache de código será descartado e substituído por um "cache de código normal".
Rastreamento
Nenhuma das sugestões acima é garantida para acelerar seu aplicativo web. Infelizmente, as informações de cache de código atualmente não estão disponíveis no DevTools, então a maneira mais robusta de descobrir quais scripts do seu aplicativo web estão sendo armazenados no cache de código é usar o chrome://tracing em um nível levemente inferior.
chrome://tracing registra rastreamentos instrumentados do Chrome durante algum período de tempo, onde a visualização do rastreamento resultante se parece com isso:
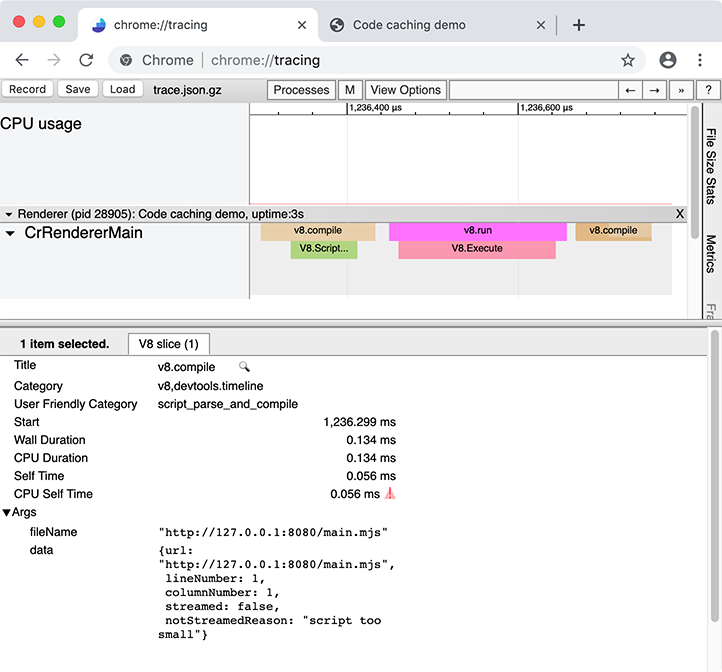
O rastreamento registra o comportamento de todo o navegador, incluindo outras abas, janelas e extensões, então funciona melhor quando feito em um perfil de usuário limpo, com extensões desativadas e sem outras abas do navegador abertas:
# Iniciar uma nova sessão do navegador Chrome com um perfil de usuário limpo e extensões desativadas
google-chrome --user-data-dir="$(mktemp -d)" --disable-extensions
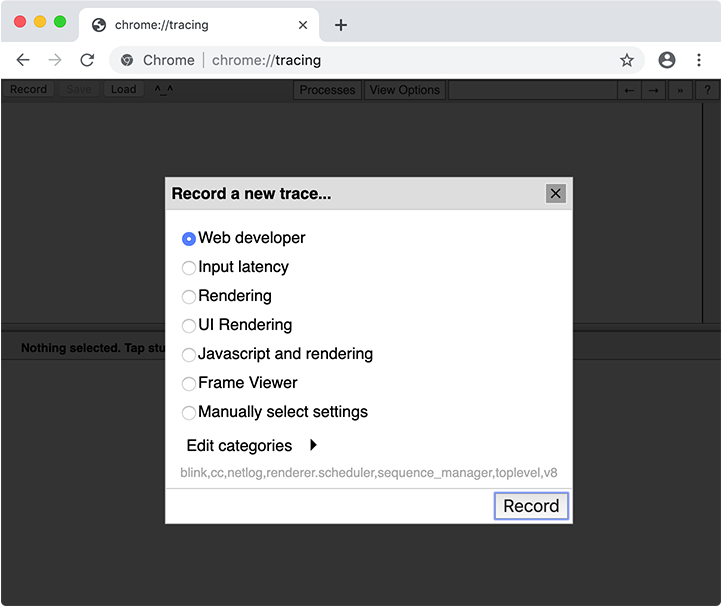
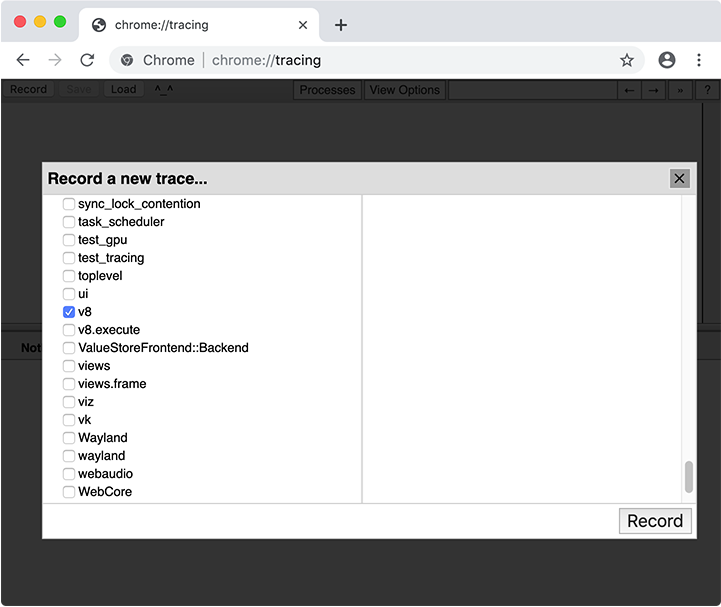
Ao coletar um rastreamento, você precisa selecionar quais categorias rastrear. Na maioria dos casos, você pode simplesmente selecionar o conjunto de categorias "Desenvolvedor web", mas também pode escolher categorias manualmente. A categoria importante para cache de código é v8.
Após gravar um rastreamento com a categoria v8, procure por fragmentos v8.compile no rastreamento. (Alternativamente, você pode digitar v8.compile na caixa de busca da interface do rastreamento.) Esses listam o arquivo sendo compilado e alguns metadados sobre a compilação.
Em uma execução fria de um script, não há informações sobre cache de código — isso significa que o script não estava envolvido na produção ou consumo de dados do cache.
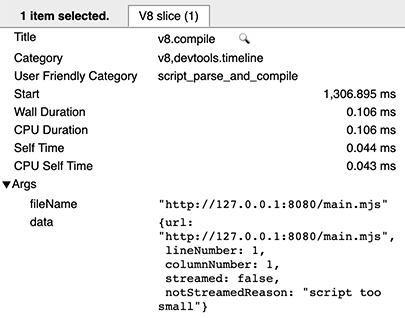
Em uma execução morna, há duas entradas v8.compile por script: uma para a compilação real (como acima), e outra (após a execução) para produzir o cache. Você pode reconhecer a última, pois ela possui os campos de metadados cacheProduceOptions e producedCacheSize.
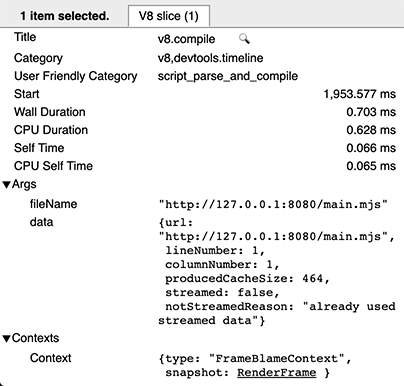
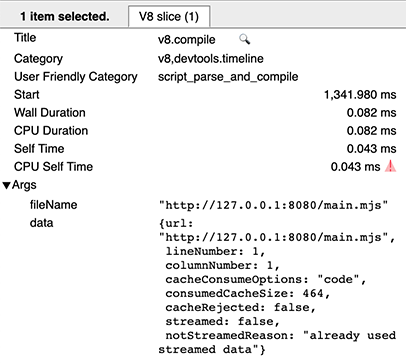
Em uma execução quente, você verá uma entrada v8.compile para consumir o cache, com campos de metadados cacheConsumeOptions e consumedCacheSize. Todos os tamanhos são expressos em bytes.
Conclusão
Para a maioria dos desenvolvedores, o cache de código deve "funcionar automaticamente". Ele funciona melhor, como qualquer cache, quando as coisas permanecem inalteradas, e opera com heurísticas que podem mudar entre versões. No entanto, o cache de código tem comportamentos que podem ser utilizados, e limitações que podem ser evitadas, e uma análise cuidadosa usando chrome://tracing pode ajudá-lo a ajustar e otimizar o uso de caches pelo seu aplicativo web.