Liftoff: V8에서 WebAssembly의 새로운 기본 컴파일러
V8 v6.9에는 WebAssembly의 새로운 기본 컴파일러인 Liftoff가 포함되어 있습니다. Liftoff는 데스크탑 시스템에서 기본적으로 활성화되어 있습니다. 이 글에서는 다른 컴파일 단계 추가의 동기를 상세히 설명하고 Liftoff의 구현 및 성능에 대해 설명합니다.

WebAssembly가 출시된 지 1년이 넘은 현재, 웹에서의 채택이 꾸준히 증가하고 있습니다. WebAssembly를 목표로 하는 대형 애플리케이션이 나타나고 있습니다. 예를 들어, Epic의 ZenGarden 벤치마크는 39.5MB 크기의 WebAssembly 바이너리로 구성되며, AutoDesk는 36.8MB의 바이너리로 제공됩니다. 컴파일 시간은 바이너리 크기에 본질적으로 비례하기 때문에, 이러한 애플리케이션은 시작하는 데 상당한 시간이 소요됩니다. 많은 기기에서 30초 이상 걸리며, 이는 좋은 사용자 경험을 제공하지 못합니다.
하지만 왜 WebAssembly 애플리케이션은 이처럼 시작하는 데 오래 걸릴까요? 유사한 JavaScript 애플리케이션은 훨씬 빠르게 시작되는데 말이죠. 그 이유는 WebAssembly가 예측 가능한 성능을 제공하도록 설계되었기 때문입니다. 즉, 애플리케이션이 실행 중인 동안에는 성능 목표를 지속적으로 충족하도록 보장됩니다 (예: 초당 60 프레임 렌더링, 오디오 지연 또는 아티팩트 없음 등). 이를 달성하기 위해, WebAssembly 코드는 V8에서 사전 컴파일 됩니다. 이렇게 하면 Just-In-Time 컴파일러로 인한 컴파일 중단이 발생해 애플리케이션에 눈에 띄는 지연이 생기는 것을 방지할 수 있습니다.
기존 컴파일 파이프라인 (TurboFan)
V8의 WebAssembly 컴파일 접근 방식은 JavaScript 및 asm.js를 위해 설계된 최적화 컴파일러 TurboFan에 의존해왔습니다. TurboFan은 그래프 기반의 *중간 표현(IR)*을 사용하여 강도 감소, 인라이닝, 코드 이동, 명령어 결합, 복잡한 레지스터 할당 등의 고급 최적화를 가능하게 하는 강력한 컴파일러입니다. TurboFan의 설계는 JavaScript 컴파일을 지원하기 위해 필요한 많은 단계를 건너뛰고 기계 코드에 더 가까운 단계에서 파이프라인 진입을 지원합니다. WebAssembly 코드를 TurboFan의 IR로 변환하는 과정은 (SSA-구성 포함) 단일 패스를 통해 간단하게 이루어지기 때문에 매우 효율적입니다. 이는 부분적으로 WebAssembly의 구조화된 제어 흐름 덕분입니다. 그러나 컴파일 과정의 백엔드는 여전히 상당한 시간과 메모리를 소비합니다.
새로운 컴파일 파이프라인 (Liftoff)
Liftoff의 목표는 WebAssembly 기반 애플리케이션의 시작 시간을 줄이는 것입니다. 이를 위해 가능한 한 빠르게 코드를 생성합니다. 코드 품질은 부차적인 문제이며, 열띤 코드(hot code)는 어차피 TurboFan으로 다시 컴파일됩니다. Liftoff는 IR을 구축하는 데 필요한 시간과 메모리 오버헤드를 피하고, WebAssembly 함수의 바이트코드를 한 번에 처리하여 기계 코드를 생성합니다.

위 다이어그램에서 알 수 있듯이 Liftoff는 파이프라인이 두 단계만으로 구성되어 있으므로 TurboFan보다 훨씬 빠르게 코드를 생성할 수 있습니다. 실제로 펑션 바디 디코더는 원시 WebAssembly 바이트를 단일 패스로 처리하며 콜백을 통해 후속 단계와 상호작용하므로 함수 본문을 디코딩 및 검증하는 동안 코드 생성이 수행됩니다. WebAssembly의 *스트리밍 API*와 함께, 이는 V8이 네트워크를 통해 다운로드하면서 WebAssembly 코드를 기계 코드로 컴파일할 수 있게 해줍니다.
Liftoff에서의 코드 생성
Liftoff는 간단하고 빠른 코드 생성기입니다. 함수의 opcode를 한 번만 수행하며, 각 opcode에 대해 한 번에 하나씩 코드를 생성합니다. 산술과 같은 간단한 opcode의 경우 일반적으로 하나의 기계 명령으로 처리되지만, 호출과 같은 다른 경우에는 더 복잡할 수 있습니다. Liftoff는 연산 스택에 대한 메타데이터를 유지하여 각 연산의 입력이 현재 어디에 저장되어 있는지를 파악합니다. 이 "가상 스택"은 컴파일 중에만 존재합니다. WebAssembly의 구조적 제어 흐름과 검증 규칙은 이러한 입력 위치를 정적으로 결정할 수 있음을 보장합니다. 따라서 피연산자를 푸시하고 팝하는 실제 런타임 스택은 필요하지 않습니다. 실행 중에는 가상 스택의 각 값이 레지스터에 저장되거나 해당 함수의 물리적 스택 프레임에 떨어집니다. 작은 정수 상수 (i32.const로 생성된 경우)의 경우 Liftoff는 가상 스택에서 상수 값만 기록하고 코드를 생성하지 않습니다. 상수가 후속 연산에서 사용될 때에만 상수를 방출하거나 연산과 결합하여 x64에서 addl <reg>, <const> 명령을 직접 방출하는 방식으로 처리됩니다. 이는 레지스터에 상수를 로드하지 않고 더 나은 코드를 생성하게 됩니다.
Liftoff가 코드 생성을 수행하는 방법을 보기 위해 간단한 함수를 살펴보겠습니다.

이 예제 함수는 두 개의 매개변수를 받아서 그 합을 반환합니다. Liftoff가 이 함수의 바이트를 디코딩하면 먼저 로컬 변수에 대해 WebAssembly 함수 호출 규칙에 따라 내부 상태를 초기화합니다. x64의 경우 V8의 호출 규칙은 두 매개변수를 rax 및 rdx 레지스터에 전달합니다.
get_local 명령의 경우 Liftoff는 코드를 생성하지 않고 대신 이 레지스터 값이 이제 가상 스택에 푸시되었음을 나타내도록 내부 상태를 업데이트합니다. i32.add 명령은 두 레지스터를 팝한 후 결과 값을 저장할 레지스터를 선택합니다. 결과를 저장하기 위해 입력 레지스터를 사용할 수는 없습니다. 로컬 변수를 유지하기 위해 두 레지스터가 여전히 스택에 나타납니다. 이를 덮어쓰면 나중에 get_local 명령에서 반환된 값이 변경됩니다. 따라서 Liftoff는 사용 가능한 레지스터를 선택하고, 이 경우 rcx를 선택하여 rax와 rdx의 합을 해당 레지스터에 저장합니다. 그런 다음 rcx가 가상 스택에 푸시됩니다.
i32.add 명령 후 함수 본문이 완료되므로 Liftoff는 함수 반환을 조립해야 합니다. 예제 함수는 하나의 반환값을 갖고 있으므로, 함수 본문 끝에는 가상 스택에 정확히 하나의 값이 있어야 함을 검증합니다. Liftoff는 rcx에 저장된 반환값을 적절한 반환 레지스터 rax로 이동시킨 뒤 함수에서 반환하는 코드를 생성합니다.
간단히 하기 위해, 위의 예제는 블록(if, loop 등) 또는 분기를 포함하지 않습니다. WebAssembly 블록은 제어 병합을 도입하며, 코드가 상위 블록으로 분기하거나 if 블록이 건너뛰어질 수 있습니다. 이러한 병합 지점은 서로 다른 스택 상태에서 도달할 수 있습니다. 하지만 후속 코드는 특정 스택 상태를 가정하고 코드를 생성해야 합니다. 따라서 Liftoff는 현재 가상 스택 상태를 새 블록이 따라갈 상태로 스냅샷합니다(예: 우리가 현재 있는 제어 레벨로 돌아갈 때). 새 블록은 현재 활성 상태를 계속 사용하며, 스택 값 또는 로컬이 저장된 위치를 변경할 수 있습니다. 일부는 스택에 저장되거나 다른 레지스터에 유지될 수 있습니다. 다른 블록으로 분기하거나 블록을 끝낼 때(Liftoff는 부모 블록으로 분기하는 것과 동일), Liftoff는 현재 상태를 해당 시점에서 예상 상태로 조정하는 코드를 생성해야 하며, 이를 통해 목표에 대해 방출된 코드가 예상 위치에서 올바른 값을 찾을 수 있습니다. 검증은 현재 가상 스택 높이가 예상 상태 높이와 일치함을 보장하므로 Liftoff는 레지스터와/또는 물리적 스택 프레임 사이에서 값을 이동시키는 코드만 생성하면 됩니다(아래와 같이).
이제 그 예를 살펴보겠습니다.

위의 예제는 피연산자 스택에 두 개의 값을 가진 가상 스택을 가정합니다. 새 블록을 시작하기 전에, 가상 스택의 최상위 값이 if 명령의 인수로 팝됩니다. 남은 스택 값은 다른 레지스터에 위치해야 하는데, 현재 첫 번째 매개변수를 가리기 때문입니다. 그러나 이 상태로 다시 분기할 때 스택 값과 매개변수를 나타내기 위해 두 가지 다른 값을 유지해야 할 수도 있습니다. 이 경우 Liftoff는 이를 rcx 레지스터에 중복 제거합니다. 그런 다음 이 상태를 스냅샷하고 블록 내에서 활성 상태를 수정합니다. 블록 끝에서는 묵시적으로 부모 블록으로 분기하므로 rbx 레지스터를 rcx로 이동시키고 스택 프레임에서 rdx 레지스터를 다시 로드하여 스냅샷이 현재 상태와 병합됩니다.
Liftoff에서 TurboFan으로의 단계적 향상
Liftoff 및 TurboFan을 통해 V8은 이제 WebAssembly를 위한 두 가지 컴파일 계층을 갖추고 있습니다: 빠른 시작을 위한 기본 컴파일러로서의 Liftoff와 최대 성능을 위한 최적화 컴파일러인 TurboFan. 이 두 컴파일러를 결합하여 최상의 전체 사용자 경험을 제공하는 방법에 대해 고민할 필요가 있습니다.
JavaScript의 경우, V8은 Ignition 인터프리터와 TurboFan 컴파일러를 사용하며 동적 단계적 향상 전략을 채택합니다. 각 함수는 먼저 Ignition에서 실행되고, 핫스팟이 되면 TurboFan이 이를 고도로 최적화된 기계 코드로 컴파일합니다. 유사한 접근 방식이 Liftoff에도 적용될 수 있지만, 여기서의 트레이드오프는 약간 다릅니다:
- WebAssembly는 빠른 코드를 생성하기 위해 타입 피드백을 필요로 하지 않습니다. JavaScript가 타입 피드백을 수집하여 크게 이득을 보는 반면, WebAssembly는 정적으로 타입이 지정되므로 엔진이 바로 최적화된 코드를 생성할 수 있습니다.
- WebAssembly 코드는 긴 워밍업 단계 없이 예측 가능하게 빠르게 실행되어야 합니다. 애플리케이션이 WebAssembly를 목표로 하는 이유 중 하나는 예측 가능한 높은 성능으로 웹에서 실행하기 위해서입니다. 따라서 너무 오랫동안 비최적화된 코드를 실행하거나 실행 중 컴파일 중단을 용인할 수 없습니다.
- JavaScript용 Ignition 인터프리터의 중요한 설계 목표 중 하나는 함수를 전혀 컴파일하지 않음으로써 메모리 사용량을 줄이는 것입니다. 그러나 WebAssembly 인터프리터는 예측 가능한 빠른 성능 목표를 충족시키기에는 너무 느리다는 것을 발견했습니다. 실제로 그러한 인터프리터를 구축했지만, 컴파일된 코드보다 20배 이상 느려, 메모리를 얼마나 절약하든 디버깅 용도로만 유용했습니다. 이에 따라 엔진은 결국 컴파일된 코드를 저장해야 하고, 가장 압축되고 효율적인 TurboFan 최적화 코드를 저장해야 합니다.
이러한 제약 조건을 바탕으로 우리는 현재 V8의 WebAssembly 구현에 대해 동적 단계 업그레이드는 적절한 선택이 아니라고 결론지었습니다. 이는 코드 크기를 증가시키고 일정 기간 동안 성능을 저하시킬 수 있기 때문입니다. 대신 우리는 즉각적인 단계 업그레이드 전략을 선택했습니다. 모듈의 Liftoff 컴파일이 끝나자마자 WebAssembly 엔진은 백그라운드 스레드를 시작하여 해당 모듈의 최적화된 코드를 생성합니다. 이를 통해 V8이 코드를 빠르게 실행할 수 있게 하고(Liftoff 완료 후), TurboFan의 가장 성능 좋은 코드를 가능한 한 빨리 이용하게 합니다.
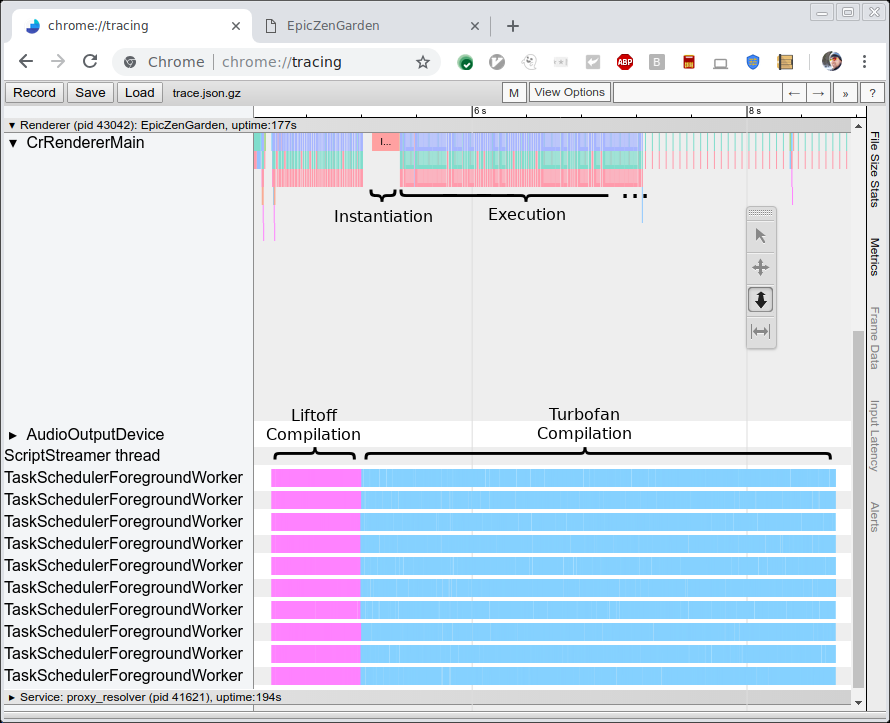
아래 그림은 EpicZenGarden 벤치마크의 컴파일 및 실행 과정을 보여줍니다. Liftoff 컴파일이 끝난 직후 WebAssembly 모듈을 인스턴스화하고 실행을 시작할 수 있음을 보여줍니다. TurboFan 컴파일은 여전히 몇 초 더 걸리므로, 단계 업그레이드 기간 동안 개별 TurboFan 함수가 완료되는 즉시 사용되면서 관찰되는 실행 성능이 점진적으로 증가합니다.
성능
새로운 Liftoff 컴파일러의 성능을 평가하려면 두 가지 지표가 흥미롭습니다. 첫 번째는 TurboFan과 비교한 컴파일 속도(즉, 코드 생성 시간)이며, 두 번째는 생성된 코드의 성능(즉, 실행 속도)입니다. 여기서는 Liftoff가 가능한 한 빨리 코드를 생성함으로써 시작 시간을 줄이는 것이 목표이기 때문에 첫 번째 측정치가 더 흥미롭습니다. 한편, 생성된 코드가 저사양 하드웨어에서도 몇 초에서 몇 분 동안 실행될 수 있으므로 해당 코드의 성능도 상당히 우수해야 합니다.
코드 생성 성능
컴파일러 성능 자체를 측정하기 위해 여러 벤치마크를 실행하고 트레이싱을 사용하여 원시 컴파일 시간을 측정했습니다(위 그림 참조). HP Z840 기계(2 x Intel Xeon E5-2690 @2.6GHz, 24코어, 48스레드)와 Macbook Pro(Intel Core i7-4980HQ @2.8GHz, 4코어, 8스레드)에서 두 벤치마크를 실행했습니다. Chrome은 현재 10개 이상의 백그라운드 스레드를 사용하지 않으므로 Z840 기계의 대부분의 코어는 사용되지 않습니다.
세 가지 벤치마크를 실행합니다:
- EpicZenGarden: Epic 프레임워크에서 실행되는 ZenGarden 데모
- Tanks!: Unity 엔진의 데모
- AutoDesk
- PSPDFKit
각 벤치마크에 대해 위에서 보여준 것처럼 트레이싱 출력을 사용하여 원시 컴파일 시간을 측정합니다. 이 수치는 벤치마크 자체가 보고한 시간보다 더 안정적입니다. 이는 작업이 메인 스레드에서 스케줄링되지 않으며 실제 WebAssembly 인스턴스를 생성하는 등의 관련 없는 작업을 포함하지 않기 때문입니다.
아래 그래프는 이러한 벤치마크의 결과를 보여줍니다. 각 벤치마크는 세 번 실행되었으며 평균 컴파일 시간을 보고합니다.


예상대로 Liftoff 컴파일러는 고성능 데스크톱 워크스테이션과 MacBook 모두에서 훨씬 더 빠르게 코드를 생성합니다. Liftoff가 TurboFan보다 덜 강력한 MacBook 하드웨어에서 더 큰 속도 향상을 보입니다.
생성된 코드의 성능
생성된 코드의 성능이 부차적인 목표이긴 하지만, 라이프오프 코드가 몇 초 동안 또는 TurboFan 코드가 완료되기 전까지 실행될 수 있으므로 시작 단계에서 높은 성능으로 사용자 경험을 유지하고자 합니다.
Liftoff 코드 성능을 측정하기 위해 우리는 단계 업그레이드를 비활성화하고 순수한 Liftoff 실행을 측정했습니다. 이 설정에서 두 가지 벤치마크를 실행합니다:
-
Unity 헤드리스 벤치마크
이는 Unity 프레임워크에서 실행되는 여러 벤치마크입니다. 헤드리스로 실행되므로 d8 셸에서 직접 실행할 수 있습니다. 각 벤치마크는 점수를 보고하며, 점수가 실행 성능에 비례하지는 않지만 성능을 비교하기에 충분합니다.
-
이 벤치마크는 PDF 문서에서 다양한 작업을 수행하는 데 걸리는 시간과 WebAssembly 모듈을 인스턴스화(컴파일 포함)하는 데 걸리는 시간을 보고합니다.
이전과 마찬가지로, 각 벤치마크를 세 번 실행하고 세 실행의 평균을 사용합니다. 기록된 숫자의 규모가 벤치마크마다 상당히 다르기 때문에, Liftoff 대비 TurboFan의 상대적인 성능을 보고합니다. 값이 *+30%*라면 Liftoff 코드가 TurboFan보다 30% 느리게 실행됨을 의미합니다. 음수는 Liftoff가 더 빠르게 실행된다는 것을 나타냅니다. 결과는 다음과 같습니다:

Unity에서 Liftoff 코드는 데스크톱 머신에서는 평균적으로 TurboFan 코드보다 약 50% 느리게, 맥북에서는 70% 느리게 실행됩니다. 흥미롭게도, 특정 사례(Mandelbrot Script)에서는 Liftoff 코드가 TurboFan 코드보다 더 나은 성능을 보입니다. 예를 들어 TurboFan의 레지스터 할당기가 반복 루프에서 제대로 작동하지 않는 경우 같은 이례적인 상황일 가능성이 있습니다. 이는 TurboFan이 이 사례를 더 잘 처리할 수 있도록 개선할 수 있는지 조사 중입니다.

PSPDFKit 벤치마크에서 Liftoff 코드는 최적화된 코드에 비해 18-54% 더 느리게 실행되지만, 초기화는 예상대로 크게 개선됩니다. 이러한 수치는 브라우저와 JavaScript 호출을 통해 상호작용하는 실제 코드에서 비최적화 코드의 성능 손실이 더 계산 집중적인 벤치마크에서보다 일반적으로 낮음을 보여줍니다.
또한, 이러한 숫자는 tier-up을 완전히 꺼버린 상태에서 측정된 것이므로 Liftoff 코드만 실행되었습니다. 실제 환경에서는 Liftoff 코드는 점진적으로 TurboFan 코드로 교체되어 Liftoff 코드의 낮은 성능이 짧은 기간 동안만 유지됩니다.
향후 작업
Liftoff의 첫 번째 출시 이후, 우리는 시작 시간을 더욱 개선하고 메모리 사용량을 줄이며 더 많은 사용자에게 Liftoff의 이점을 제공하기 위해 작업 중입니다. 특히, 다음 사항을 개선하기 위해 노력 중입니다:
- Liftoff를 ARM 및 ARM64로 포팅하여 모바일 장치에서도 사용할 수 있도록 합니다. 현재 Liftoff는 Intel 플랫폼(32 및 64비트)에만 구현되어 데스크톱을 주로 다룹니다. 모바일 사용자에게도 도달하려면 Liftoff를 더 많은 아키텍처로 포팅해야 합니다.
- 모바일 장치용으로 동적 tier-up을 구현합니다. 모바일 장치의 경우 데스크톱 시스템보다 사용할 수 있는 메모리가 훨씬 적기 때문에 이 장치들에 맞는 tiering 전략을 조정해야 합니다. TurboFan으로 모든 기능을 재컴파일하면 최소한 임시로(바로 Liftoff 코드가 제거되기 전까지) 모든 코드를 유지하는 데 필요한 메모리가 두 배로 늘어납니다. 대신, Liftoff의 지연 컴파일과 TurboFan 내에서의 주요 함수의 동적 tier-up을 결합한 방법을 실험 중입니다.
- Liftoff 코드 생성의 성능을 개선합니다. 초기 구현은 종종 최고의 구현이 아닙니다. Liftoff의 컴파일 속도를 더욱 향상시킬 수 있는 여러 가지 조정 가능 사항이 있습니다. 이는 향후 릴리스에서 점진적으로 개선될 것입니다.
- Liftoff 코드의 성능을 개선합니다. 컴파일러 자체 외에도 생성된 코드의 크기와 속도 역시 개선될 수 있습니다. 이것도 향후 릴리스에서 점진적으로 개선될 것입니다.
결론
V8에는 이제 WebAssembly용 새로운 기본 컴파일러인 Liftoff가 포함됩니다. Liftoff는 간단하고 빠른 코드 생성기로 WebAssembly 애플리케이션의 시작 시간을 대폭 단축합니다. 데스크톱 시스템에서는 V8이 TurboFan을 사용하여 모든 코드를 백그라운드에서 다시 컴파일함으로써 여전히 최대 성능을 달성합니다. Liftoff는 V8 v6.9(Chrome 69)에 기본적으로 활성화되어 있으며 각각 --liftoff/--no-liftoff 및 chrome://flags/#enable-webassembly-baseline 플래그로 명시적으로 제어할 수 있습니다.