V8에 ES2015 프록시를 최적화하기
프록시는 ES2015 이래 JavaScript에서 중요한 부분이었습니다. 이들은 객체에 대해 근본적인 작업을 가로채고 동작을 사용자 정의할 수 있게 해줍니다. 프록시는 jsdom 및 Comlink RPC 라이브러리와 같은 프로젝트의 핵심 부분을 형성합니다. 최근에 우리는 V8에서 프록시 성능을 개선하기 위해 많은 노력을 기울였습니다. 이 글은 V8에서의 일반적인 성능 개선 패턴과 특히 프록시에 대해 설명합니다.
프록시는 “객체에 대해 근본적인 동작(예: 속성 검색, 할당, 열거, 함수 호출 등)을 사용자 정의하는 데 사용되는 객체”입니다 (MDN의 정의). 더 많은 정보는 전체 사양을 참조하세요. 예를 들어, 다음 코드 스니펫은 객체의 모든 속성 접근에 대해 로깅을 추가합니다:
const target = {};
const callTracer = new Proxy(target, {
get: (target, name, receiver) => {
console.log(`get was called for: ${name}`);
return target[name];
}
});
callTracer.property = 'value';
console.log(callTracer.property);
// get was called for: property
// value
프록시 생성
우리가 집중할 첫 번째 특징은 프록시의 생성입니다. 여기에서는 ECMAScript 사양을 단계별로 따르는 원래의 C++ 구현이 최소 4번의 C++과 JS 런타임 간 점프를 발생시켰습니다. 우리는 이를 CodeStubAssembler (CSA)로 포팅하여, 플랫폼 독립적인 JS 런타임에서 실행되도록 만들고자 했습니다. 이는 언어 런타임 간의 점프 수를 최소화합니다. CEntryStub 및 JSEntryStub는 아래 그림에서 런타임을 나타냅니다. 점선은 JS와 C++ 런타임 간의 경계를 나타냅니다. 다행히도 이미 많은 도우미 술어가 어셈블러에 구현되어 있어 초기 버전을 간결하게 읽기 쉽게 만들었습니다.
아래 그림은 다음 샘플 코드로 생성된 프록시에 대해 임의의 프록시 트랩(이 예에서는 함수로 사용될 때 호출되는 apply)을 호출하는 실행 흐름을 보여줍니다:
function foo(…) { … }
const g = new Proxy({ … }, {
apply: foo,
});
g(1, 2);
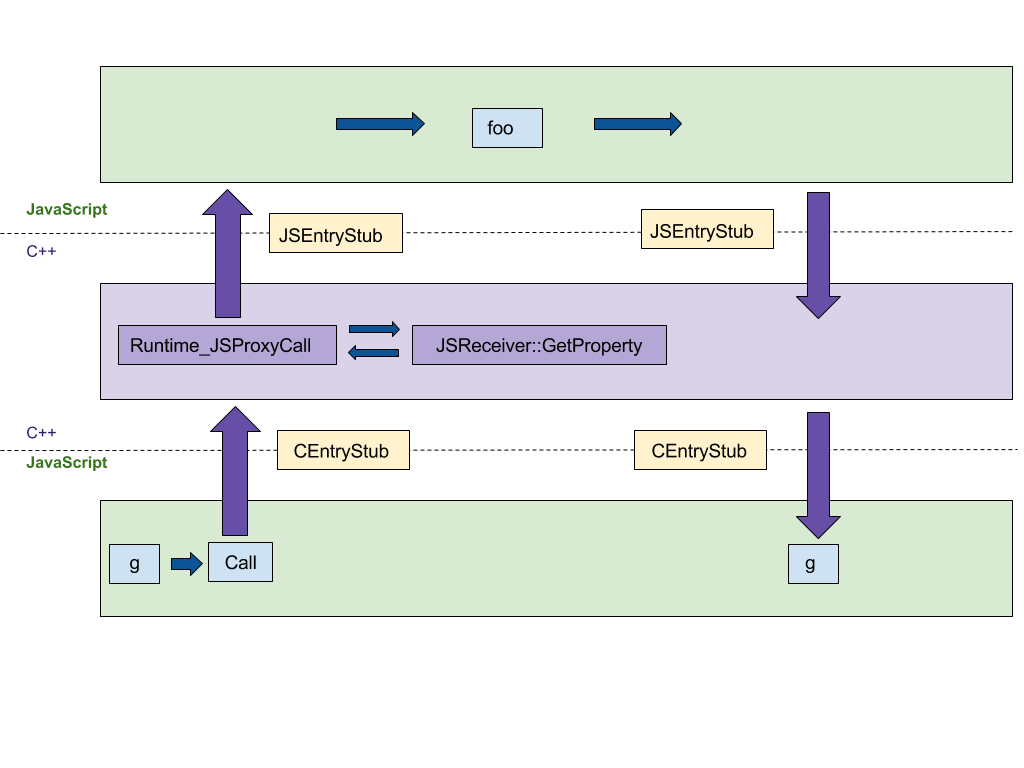
트랩 실행을 CSA로 포팅한 후 모든 실행이 JS 런타임에서 발생하여 언어 간의 점프 수가 4에서 0으로 줄어들었습니다.
이 변경은 다음과 같은 성능 개선을 가져왔습니다:
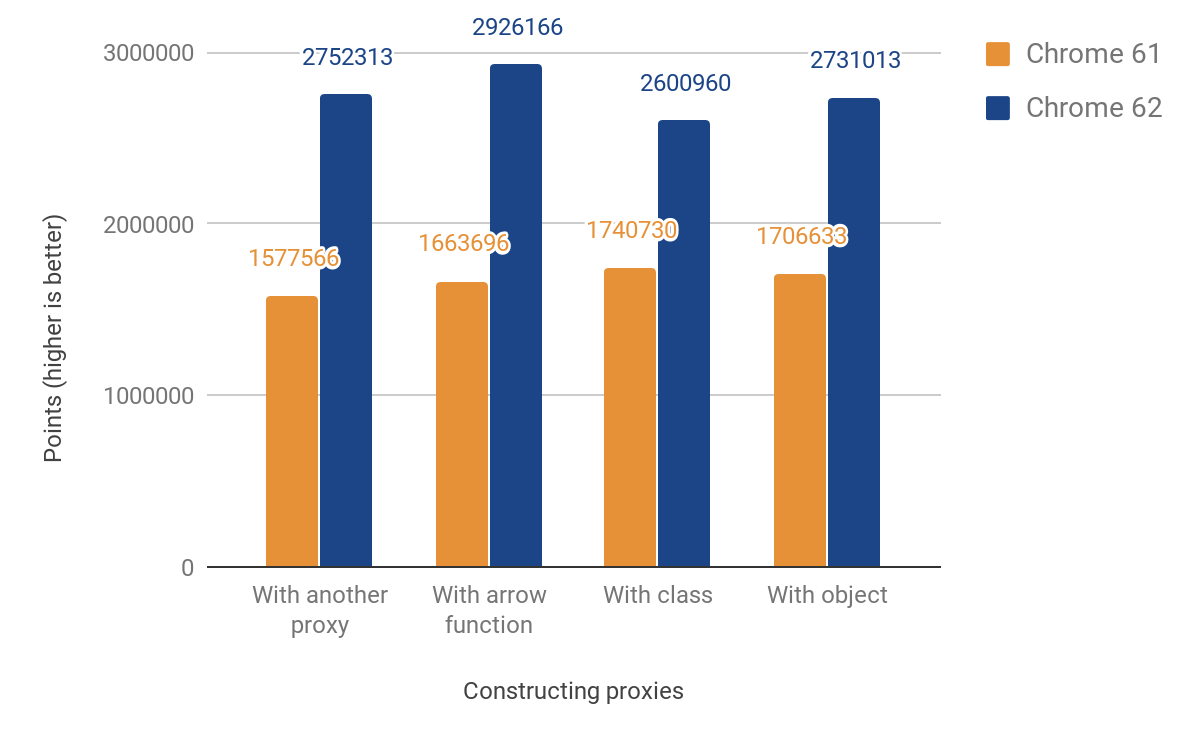
우리의 JS 성능 점수는 49%에서 74% 사이로 개선되었습니다. 이 점수는 주어진 마이크로벤치마크를 1000ms 동안 실행할 수 있는 횟수를 대략적으로 측정합니다. 일부 테스트의 경우 타이머 해상도를 고려해 정확한 측정을 위해 코드를 여러 번 실행합니다. 모든 벤치마크의 코드는 우리의 js-perf-test 디렉토리에서 확인할 수 있습니다.
호출 및 생성 트랩
다음 섹션은 호출 및 생성 트랩(즉, "apply" 및 "construct")을 최적화한 결과를 보여줍니다.

프록시를 _호출_할 때의 성능 개선은 매우 두드러지며 최대 500% 더 빠릅니다! 하지만 프록시 생성의 개선은 다소 미미하며, 특히 실제 트랩이 정의되지 않은 경우에는 약 **25%**의 향상만 있습니다. 우리는 이를 d8 셸을 사용해 다음 명령을 실행하여 조사했습니다:
$ out/x64.release/d8 --runtime-call-stats test.js
> run: 120.104000
런타임 함수/C++ 내장 시간 횟수
========================================================================================
NewObject 59.16ms 48.47% 100000 24.94%
JS_Execution 23.83ms 19.53% 1 0.00%
RecompileSynchronous 11.68ms 9.57% 20 0.00%
AccessorNameGetterCallback 10.86ms 8.90% 100000 24.94%
AccessorNameGetterCallback_FunctionPrototype 5.79ms 4.74% 100000 24.94%
Map_SetPrototype 4.46ms 3.65% 100203 25.00%
… SNIPPET …
test.js의 소스는 다음과 같습니다:
function MyClass() {}
MyClass.prototype = {};
const P = new Proxy(MyClass, {});
function run() {
return new P();
}
const N = 1e5;
console.time('run');
for (let i = 0; i < N; ++i) {
run();
}
console.timeEnd('run');
대부분의 시간이 NewObject와 그로 인해 호출된 함수들에서 소비된다는 사실을 발견했고, 이를 미래 버전에서 가속화할 계획을 세우기 시작했습니다.
Get 트랩
다음 섹션에서는 프록시를 통해 속성을 가져오고 설정하는 가장 일반적인 작업을 최적화한 방법을 설명합니다. get 트랩은 V8의 인라인 캐시의 고유한 동작 때문에 이전 사례보다 더 복잡합니다. 인라인 캐시에 대한 자세한 설명은 이 강연을 참고하세요.
결국 다음 결과로 CSA로의 작동 포트를 구현할 수 있었습니다:
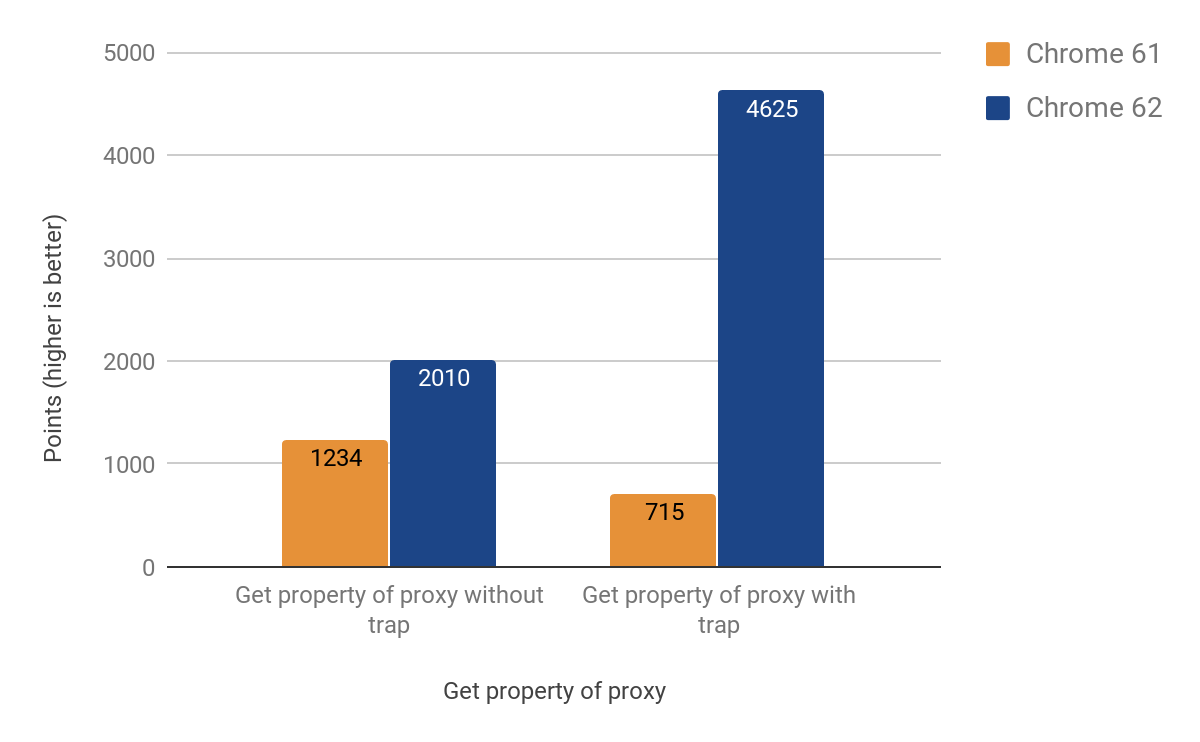
변경 사항이 적용된 후, Chrome의 Android .apk 크기가 예상보다 많게 약 160KB 증가한 것을 확인했습니다. 이는 대략 20줄짜리 도우미 함수로 예상 범위를 초과한 것이었지만, 다행히도 이러한 통계를 추적하고 있습니다. 문제의 원인은 공격적인 인라이닝에 있었습니다. 결국 인라인 함수를 별도의 코드 스텁으로 전환하여 문제를 해결했고, 최종적으로 .apk 크기 증가가 단지 약 19KB로 감소했습니다.
Has 트랩
다음 섹션은 has 트랩을 최적화한 결과를 보여줍니다. 처음에는 더 쉬울 것이라고 생각했지만(get 트랩 코드를 대부분 재사용할 수 있을 것이라 여겼습니다), 고유한 특성이 있다는 것을 발견했습니다. 특히 어려웠던 문제는 in 연산자를 호출할 때 프로토타입 체인을 탐색하는 것이었습니다. 향상 결과는 71%에서 428% 사이에서 다양합니다. 다시 말해, 트랩이 있는 상황에서 개선 효과가 두드러집니다.
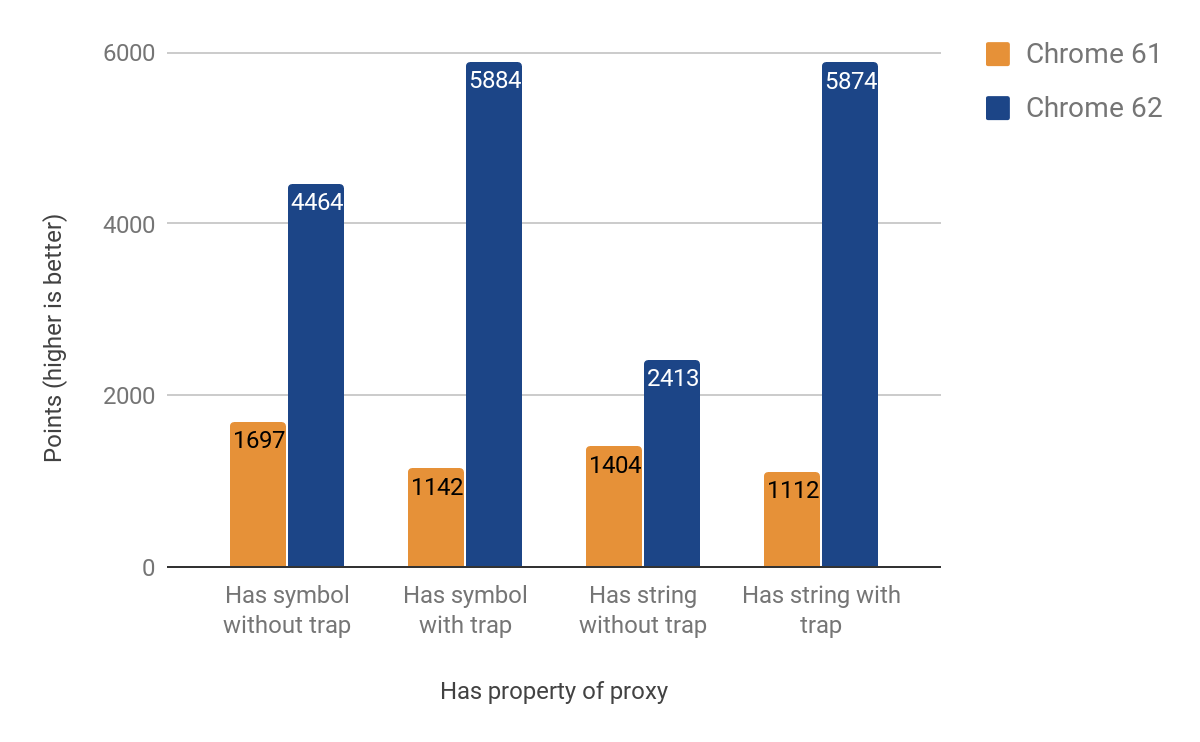
Set 트랩
다음 섹션은 set 트랩을 포팅하는 것에 대해 다룹니다. 이 경우에는 이름 기반 속성과 인덱스 속성(요소)을 구분해야 했습니다. 이 두 주요 유형은 JS 언어의 일부는 아니지만 V8의 효율적인 속성 저장에 필수적입니다. 초기 구현에서는 요소에 대해 런타임으로 복귀했으며, 이는 언어 경계를 다시 넘는 원인이 됩니다. 그럼에도 불구하고, 트랩이 설정되어 있는 경우 27%에서 438% 사이의 개선을 이룰 수 있었습니다. 반면, 트랩이 없는 경우에는 최대 **23%**까지 감소하는 결과를 초래했습니다. 인덱스 속성의 경우 아직 개선 사항은 없습니다. 여기에 전체 결과가 나와 있습니다:
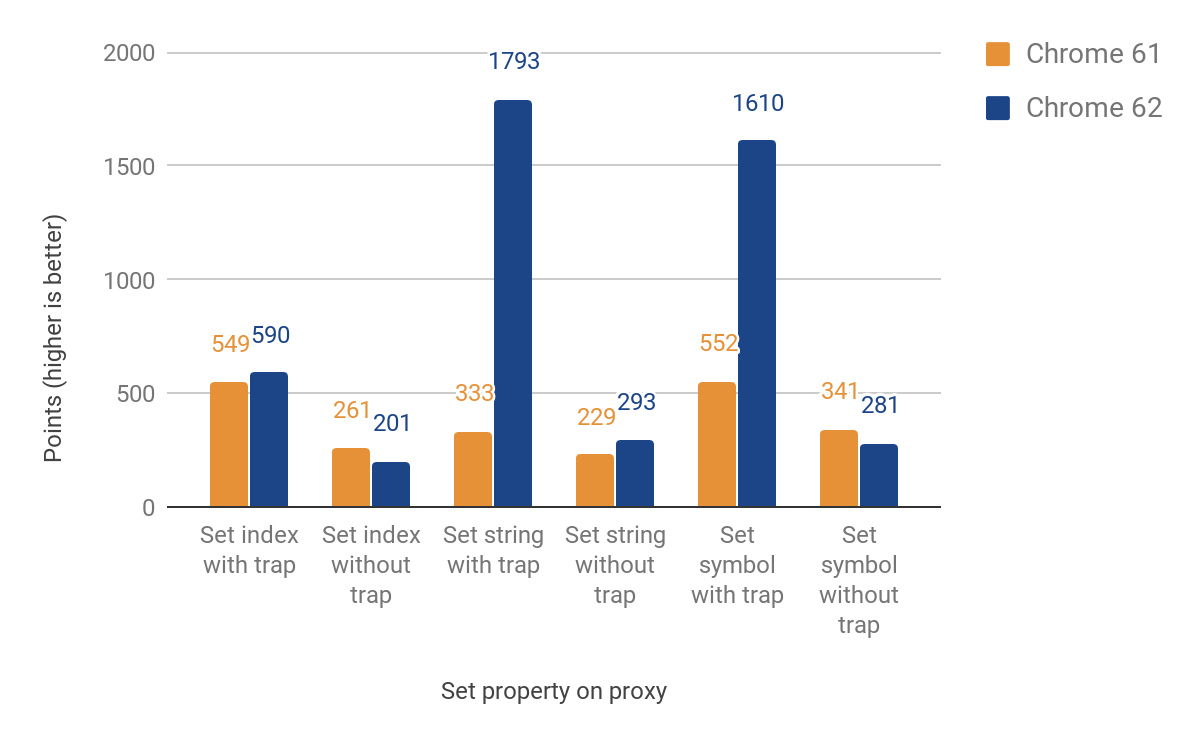
실제 사용 시나리오
jsdom-proxy-benchmark 결과
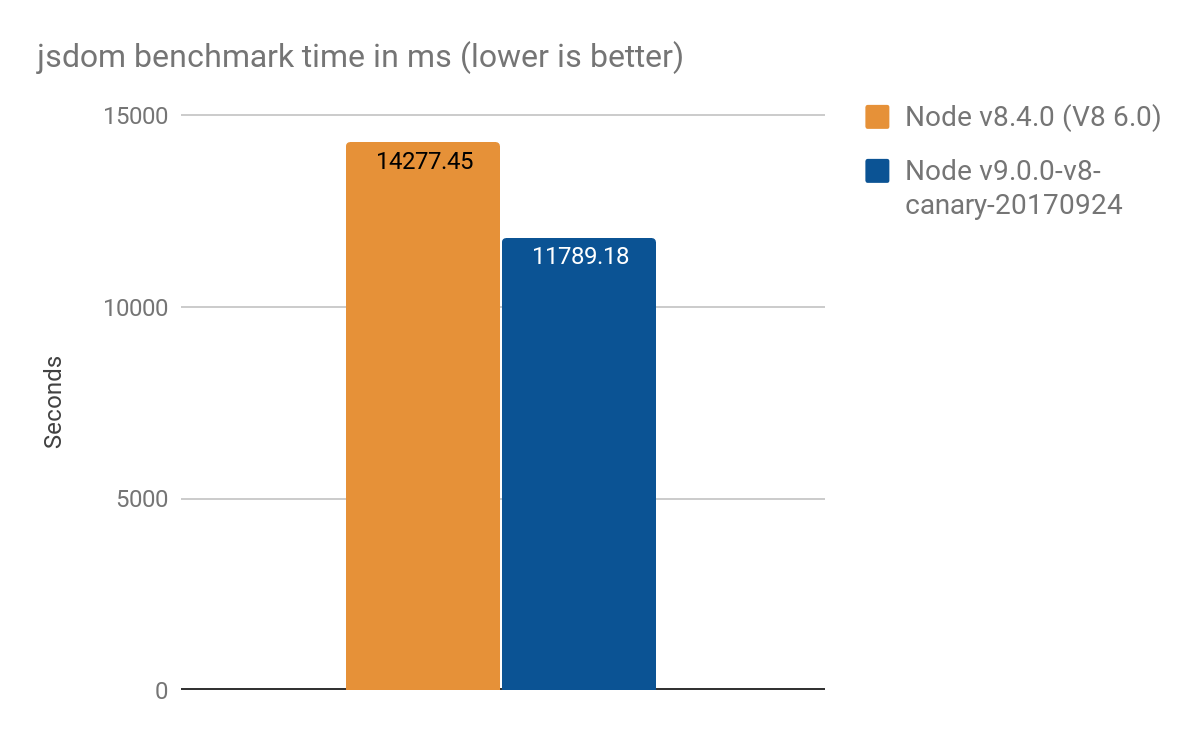
jsdom-proxy-benchmark 프로젝트는 ECMAScript 명세를 Ecmarkup 도구를 사용하여 컴파일합니다. v11.2.0 기준으로 jsdom 프로젝트(이 프로젝트는 Ecmarkup의 기반을 이룹니다)는 프록시를 사용하여 데이터 구조 NodeList와 HTMLCollection을 구현합니다. 우리는 이 벤치마크를 사용하여 합성 마이크로 벤치마크보다 더 현실적인 사용의 개요를 얻었으며, 평균 100회 실행에서 다음 결과를 얻었습니다:
- Node v8.4.0 (Proxy 최적화 없음): 14277 ± 159 ms
- Node v9.0.0-v8-canary-20170924 (트랩의 절반만 포팅됨): 11789 ± 308 ms
- 약 2.4초의 속도 향상, 이는 약 17% 개선
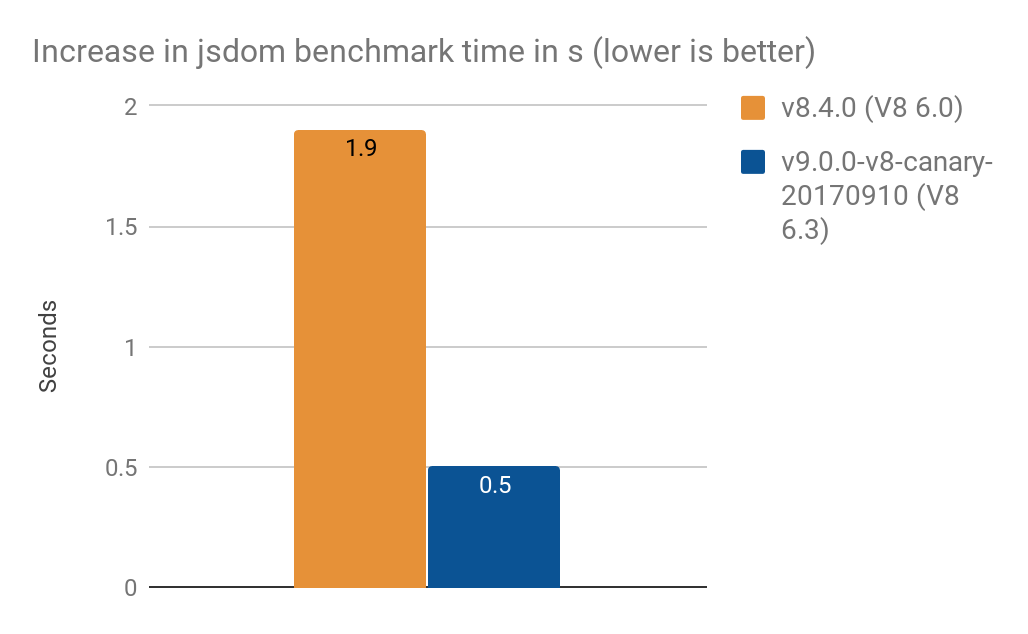
NamedNodeMap을 Proxy로 변환하면 처리 시간이 다음과 같이 증가했습니다- V8 6.0 (Node v8.4.0)에서 1.9초
- V8 6.3 (Node v9.0.0-v8-canary-20170910)에서 0.5초
참고: 이 결과는 Timothy Gu가 제공했습니다. 감사합니다!
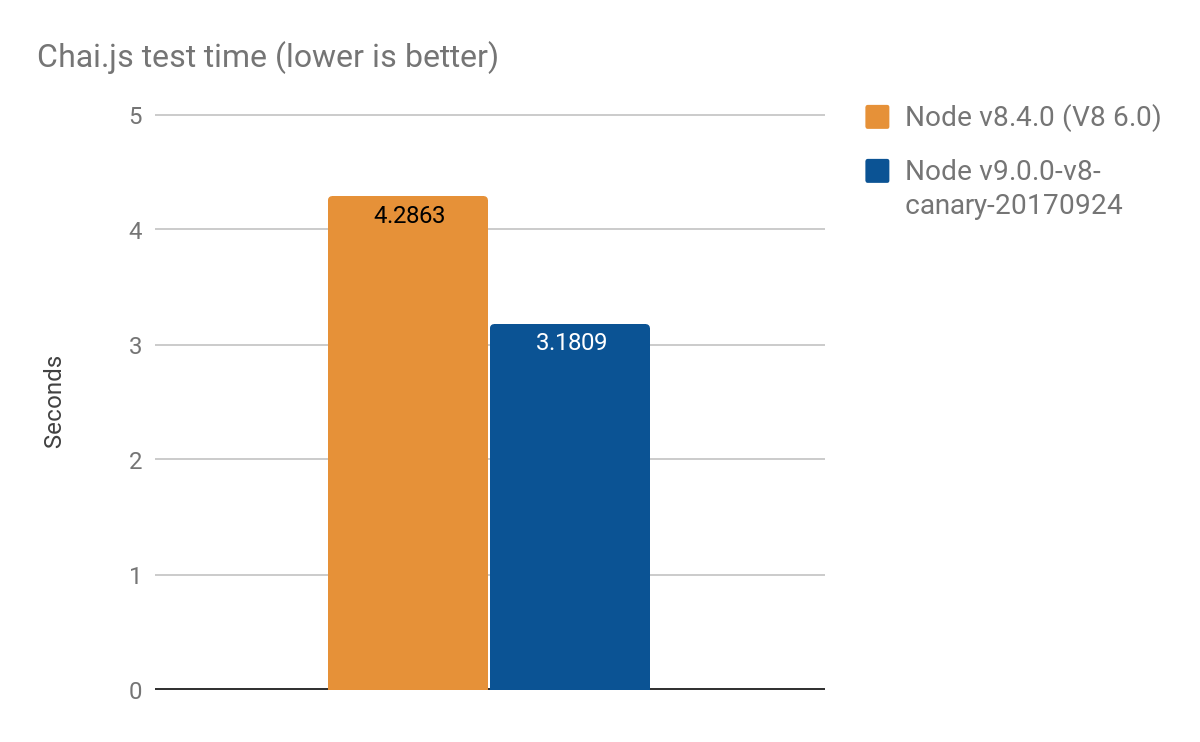
Chai.js 의 결과
Chai.js는 프록시를 많이 사용하는 인기 있는 단언 라이브러리입니다. 다양한 버전의 V8에서 테스트를 실행하여 일종의 실제 벤치마크를 만들었으며, 평균 100회 실행에서 약 4초 중 1초 개선되었습니다:
- Node v8.4.0 (프록시 최적화 없이): 4.2863 ± 0.14 초
- Node v9.0.0-v8-canary-20170924 (트랩의 절반만 포팅됨): 3.1809 ± 0.17 초
최적화 접근 방식
우리는 일반적인 최적화 계획을 사용하여 성능 문제를 자주 해결합니다. 이번 작업에 대해 우리가 따른 주요 접근 방식은 다음 단계를 포함했습니다:
- 특정 하위 기능에 대한 성능 테스트 구현
- 추가적인 명세 호환성 테스트 작성 (또는 처음부터 작성)
- 원래 C++ 구현 조사
- 플랫폼에 독립적인 CodeStubAssembler로 하위 기능 포팅
- TurboFan 구현을 수작업으로 최적화하여 코드 더욱 개선
- 성능 개선 측정.
이 접근 방식은 일반적인 최적화 작업에 적용할 수 있습니다.