내장 빌트인
V8 내장 함수(빌트인 함수)는 V8의 모든 인스턴스에서 메모리를 소비합니다. 빌트인 함수의 개수, 평균 크기, 그리고 크롬 브라우저 탭당 V8 인스턴스 수는 크게 증가해 왔습니다. 이 블로그 게시물에서는 지난 1년 동안 웹사이트당 평균 V8 힙 크기를 19% 줄이는 방법을 설명합니다.
배경
V8은 방대한 JavaScript(Javascript, JS) 내장 함수 라이브러리를 제공합니다. 많은 빌트인은 RegExp.prototype.exec나 Array.prototype.sort와 같이 자바스크립트 내장 객체에 설치된 함수로 JS 개발자들에게 직접 노출됩니다; 다른 빌트인은 다양한 내부 기능을 구현합니다. 빌트인 함수에 대한 기계 코드는 V8의 자체 컴파일러에 의해 생성되며 초기화 시 모든 V8 아이솔레이트(고립 상태)에 대한 관리 힙 상태로 로드됩니다. 아이솔레이트는 V8 엔진의 고립된 인스턴스를 나타내며, 크롬의 모든 브라우저 탭에는 최소 하나의 아이솔레이트가 포함됩니다. 아이솔레이트는 자체 관리 힙을 가지며, 따라서 모든 빌트인 함수의 복사본을 가지게 됩니다.
2015년으로 돌아가면, 빌트인 함수는 대부분 자체적으로 호스팅된 JS 또는 네이티브 어셈블리, 또는 C++로 구현되었습니다. 그것들은 비교적 작은 규모였으며 모든 아이솔레이트에 복사본을 만드는 것은 덜 문제였습니다.
지난 몇 년 동안 이 분야에서 많은 변화가 있었습니다.
2016년 V8은 CodeStubAssembler (CSA)를 사용하여 구현된 빌트인 함수를 실험하기 시작했습니다. 이는 플랫폼 독립적이고 가독성이 좋다는 장점과 더불어 효율적인 코드를 생성하는 데 유용한 것으로 밝혀졌으며, CSA 빌트인은 보편화되었습니다. 다양한 이유로 CSA 빌트인은 더 큰 코드를 생성하는 경향이 있으며, CSA로 포팅되는 빌트인의 수가 증가함에 따라 V8 빌트인의 크기가 대략 3배로 증가했습니다. 2017년 중반까지 아이솔레이트당 오버헤드가 크게 증가했고, 우리는 체계적인 해결책에 대해 생각하기 시작했습니다.
2017년 후반에 우리는 첫 단계로 게으른 빌트인(및 바이트코드 핸들러) 역직렬화를 구현했습니다. 초기 분석 결과 대부분의 사이트에서 모든 빌트인의 절반 이하만을 사용하고 있다는 것이 나타났습니다. 게으른 역직렬화와 함께, 빌트인은 필요할 때만 로드되고 사용되지 않은 빌트인은 아이솔레이트에 로드되지 않습니다. 게으른 역직렬화는 크롬 64에서 유망한 메모리 절약 효과와 함께 제공되었습니다. 그러나 빌트인 메모리 오버헤드는 여전히 아이솔레이트 수에 따라 선형적으로 증가했습니다.
그런 다음 Spectre가 공개되었으며, 크롬은 결국 그 효과를 완화하기 위해 사이트 아이솔레이션을 켰습니다. 사이트 아이솔레이션은 크롬 렌더러 프로세스를 단일 출처의 문서로 제한합니다. 따라서 사이트 아이솔레이션과 함께 많은 브라우저 탭이 더 많은 렌더러 프로세스와 더 많은 V8 아이솔레이트를 생성합니다. 아이솔레이트별 오버헤드를 관리하는 것이 항상 중요했지만, 사이트 아이솔레이션으로 인해 더욱 중요해졌습니다.
내장 빌트인
이 프로젝트의 목표는 아이솔레이트당 빌트인 오버헤드를 완전히 제거하는 것이었습니다.
그 뒤에 있는 아이디어는 간단했습니다. 개념적으로, 빌트인은 아이솔레이트 간에 동일하며 구현 세부사항 때문에 아이솔레이트에 바인딩되어 있습니다. 빌트인을 진정으로 아이솔레이트 독립적으로 만들 수 있다면 메모리에 단일 복사본을 유지하고 모든 아이솔레이트 간에 공유할 수 있습니다. 그리고 그것들을 프로세스 독립적으로 만들 수 있다면, 프로세스 간에도 공유할 수 있습니다.
실제로 우리는 몇 가지 도전에 직면했습니다. 생성된 빌트인 코드에는 아이솔레이트와 프로세스 특화 데이터에 대한 임베드된 포인터가 포함되어 있기 때문에 아이솔레이트나 프로세스 독립적이지 않았습니다. V8은 관리 힙 외부에 위치한 생성된 코드를 실행하는 개념이 없었습니다. 빌트인은 프로세스 간에 공유되어야 했으며, 이상적으로는 기존 OS 메커니즘을 재사용해야 했습니다. 그리고 마지막으로(이는 긴 꼬리로 드러났습니다), 성능이 눈에 띄게 저하되지 않아야 했습니다.
다음 섹션에서는 우리의 솔루션을 자세히 설명합니다.
아이솔레이트 및 프로세스 독립적 코드
빌트인은 V8의 컴파일러 내부 파이프라인에 의해 생성되며, 힙 상수(아이솔레이트의 관리 힙에 위치), 호출 대상(Code 객체, 역시 관리 힙에 위치), 및 아이솔레이트 및 프로세스 특정 주소(C 런타임 함수 또는 아이솔레이트 자체에 대한 포인터로도 불리는 ’외부 참조’)에 대한 참조를 코드에 직접 포함합니다. x64 어셈블리에서 이러한 객체를 로드하는 것은 다음과 같이 보일 수 있습니다:
// 임베디드 주소를 레지스터 rbx로 로드합니다.
REX.W movq rbx,0x56526afd0f70
V8에는 이동 가능한 가비지 컬렉터가 있으며, 대상 객체의 위치는 시간이 지남에 따라 변경될 수 있습니다. 컬렉션 중에 대상이 이동하면 GC는 생성된 코드를 업데이트하여 새로운 위치를 가리키게 합니다.
x64(및 대부분의 다른 아키텍처)에서는 다른 Code 객체에 대한 호출에 현재 프로그램 카운터에서 오프셋을 지정하여 호출 대상을 효율적으로 호출하는 호출 명령어를 사용합니다(흥미로운 세부사항: V8은 시작 시 모든 가능성 있는 Code 객체들이 서로 주소 가능한 오프셋 내에 있음을 보장하기 위해 관리 힙의 전체 CODE_SPACE를 예약합니다). 호출 순서와 관련된 부분은 다음과 같습니다:
// [pc + <offset>] 위치에 위치한 호출 명령.
call <offset>
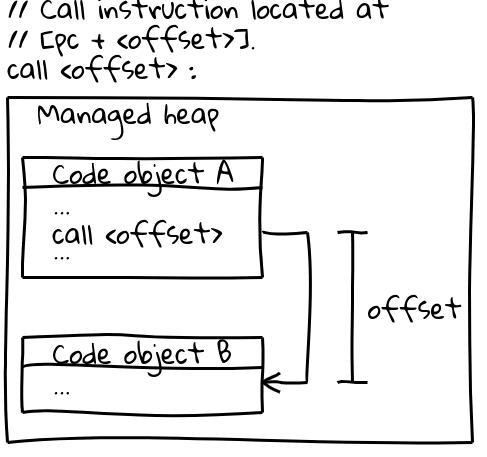
Code 객체 자체는 관리 힙에서 운영되며 이동 가능성이 있습니다. 이동될 경우, GC는 모든 관련 호출 위치에서 오프셋을 업데이트합니다.
프로세스 간에 내장 기능을 공유하려면 생성된 코드가 불변적이고, 아이솔레이트 및 프로세스 독립적이어야 합니다. 위의 두 가지 명령 순서는 이 요구 사항을 충족하지 못합니다: 코드는 주소를 직접 포함하고 있으며, 런타임에 GC에 의해 수정됩니다.
이 두 가지 문제를 해결하기 위해, 현재 Isolate 내의 알려진 위치에 대한 포인터를 보유하는 전용, 이른바 루트 레지스터를 통한 간접 참조를 도입했습니다.
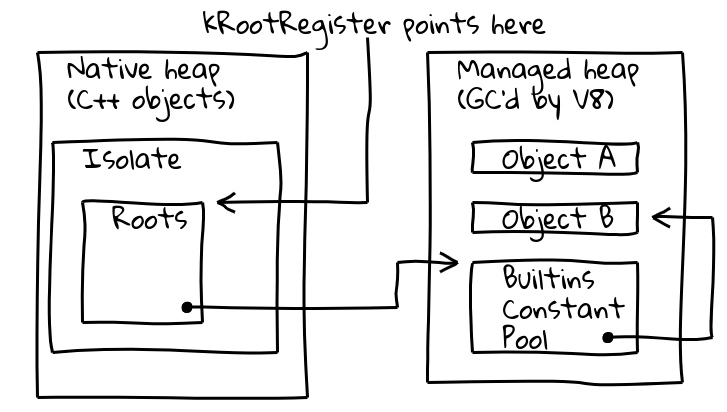
V8의 Isolate 클래스에는 루트 테이블이 포함되어 있으며, 이 테이블 자체는 관리 힙에 루트 객체에 대한 포인터를 포함합니다. 루트 레지스터는 항상 루트 테이블의 주소를 유지합니다.
이로 인해 루트 객체를 로드하는 새로운 아이솔레이트 및 프로세스 독립적 방법이 다음과 같이 됩니다:
// 루트에서 주어진 오프셋에 위치한
// 상수 주소를 로드합니다.
REX.W movq rax,[kRootRegister + <offset>]
루트 힙 상수는 위와 같이 루트 목록에서 직접 로드할 수 있습니다. 다른 힙 상수는 루트 목록 자체에 저장된 글로벌 내장 상수 풀을 통해 추가 간접 참조를 사용합니다:
// 내장 상수 풀을 로드한 다음
// 원하는 상수를 로드합니다.
REX.W movq rax,[kRootRegister + <offset>]
REX.W movq rax,[rax + 0x1d7]
Code 대상을 위해, 초기에는 위와 같이 글로벌 내장 상수 풀에서 대상 Code 객체를 로드하고, 대상 주소를 레지스터로 로드하며, 마지막으로 간접 호출을 수행하는 더 복잡한 호출 시퀀스를 사용했습니다.
이러한 변경 사항 덕분에 생성된 코드는 아이솔레이트 및 프로세스 독립적이 되었고, 프로세스 간에 이를 공유하는 작업을 시작할 수 있었습니다.
프로세스 간 공유
처음에는 두 가지 대안을 평가했습니다. 내장 기능은 데이터 블롭 파일을 메모리에 mmap하여 공유하거나, 바이너리에 직접 내장될 수 있었습니다. 후자의 방법을 택했는데, 이는 메모리를 프로세스 간에 공유하기 위해 OS의 표준 메커니즘을 자동으로 재사용할 수 있으며, Chrome과 같은 V8 임베더에서 추가 논리를 요구하지 않는 이점이 있었습니다. 이 접근법은 이미 Dart의 AOT 컴파일이 생성된 코드를 성공적으로 바이너리에 내장한 경험이 있었기에 자신 있었습니다.
실행 가능한 바이너리 파일은 여러 섹션으로 나뉩니다. 예를 들어, ELF 바이너리는 .data(초기화된 데이터), .ro_data(초기화된 읽기 전용 데이터), .bss(초기화되지 않은 데이터) 섹션에 데이터를 포함하며, 네이티브 실행 코드는 .text에 배치됩니다. 우리의 목표는 네이티브 코드와 함께 내장된 코드를 .text 섹션에 포장하는 것이었습니다.
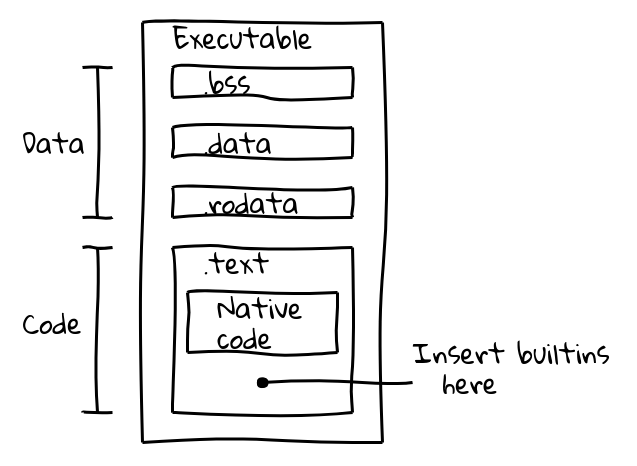
이는 V8의 내부 컴파일러 파이프라인을 사용하여 모든 내장 기능에 대한 네이티브 코드를 생성하고 그 내용을 embedded.cc에 출력하는 새로운 빌드 단계를 도입함으로써 이루어졌습니다. 이 파일은 이후 최종 V8 바이너리로 컴파일됩니다.

embedded.cc 파일 자체는 메타데이터와 생성된 내장 기계 코드를 포함하며, C++ 컴파일러(우리의 경우 clang 또는 gcc)가 지정된 바이트 시퀀스를 출력 객체 파일(나중에는 실행 파일)에 직접 배치하도록 지시하는 .byte 지시어 시리즈로 되어 있습니다.
// 내장된 내장 기능에 대한 정보는
// 메타데이터 테이블에 포함됩니다.
V8_EMBEDDED_TEXT_HEADER(v8_Default_embedded_blob_)
__asm__(".byte 0x65,0x6d,0xcd,0x37,0xa8,0x1b,0x25,0x7e\n"
[메타데이터 생략]
// 이어지는 생성된 기계 코드.
__asm__(V8_ASM_LABEL("Builtins_RecordWrite"));
__asm__(".byte 0x55,0x48,0x89,0xe5,0x6a,0x18,0x48,0x83\n"
[내장 코드 생략]
.text 섹션의 내용은 런타임에 읽기 전용 실행 메모리에 매핑되며, OS는 재배치 가능한 심볼 없이 위치 독립적 코드만 포함된 경우 메모리를 프로세스 간에 공유합니다. 이는 우리가 원하던 바로 그것입니다.
하지만 V8의 Code 객체는 명령어 스트림뿐만 아니라 일부는 isolate에 종속적인 다양한 메타데이터 조각들로 구성되어 있습니다. 일반적인 Code 객체는 관리 힙에 있는 가변 크기의 Code 객체에 메타데이터와 명령어 스트림을 모두 포함합니다.
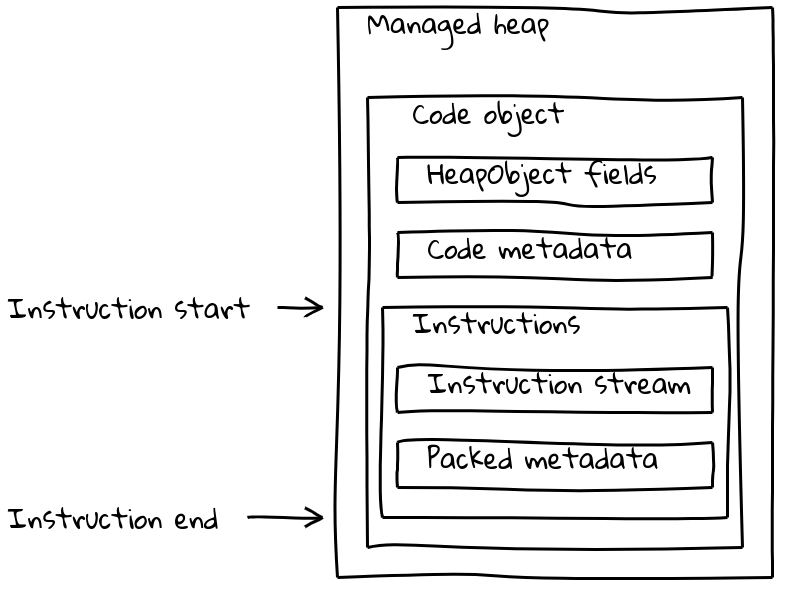
우리가 본 것처럼, 임베디드 빌트인은 네이티브 명령어 스트림이 관리 힙 외부, .text 섹션에 삽입됩니다. 메타데이터를 유지하기 위해 각 임베디드 빌트인은 관리 힙에 관련된 작은 Code 객체도 가지고 있는데, 이를 _오프 힙 트램펄린_이라고 합니다. 메타데이터는 표준 Code 객체와 같이 트램펄린에 저장되며, 인라인된 명령어 스트림은 단순히 삽입된 명령어의 주소를 로드하고 거기로 점프하는 짧은 시퀀스를 포함합니다.
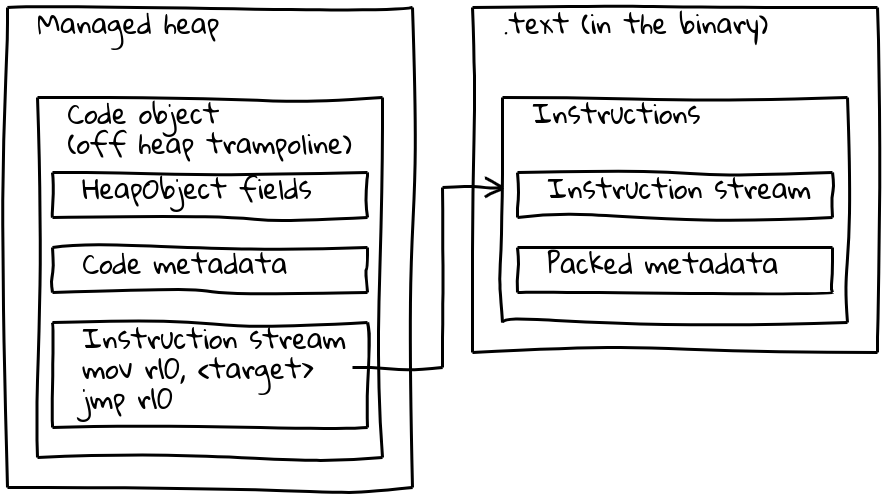
이 트램펄린은 V8이 모든 Code 객체를 동일하게 처리할 수 있도록 합니다. 대부분의 목적에서 보면, 주어진 Code 객체가 관리 힙의 표준 코드인지 임베디드 빌트인인지 여부는 중요하지 않습니다.
성능 최적화
이전 섹션에서 설명한 솔루션을 통해 임베디드 빌트인은 본질적으로 기능이 완성되었지만, 벤치마크 결과 상당한 속도 저하가 있음을 알게 되었습니다. 예를 들어 초기 솔루션은 Speedometer 2.0 성능을 전체적으로 5% 이상 감소시켰습니다.
우리는 최적화 기회를 찾기 시작하여 주요 속도 저하 원인을 식별했습니다. 생성된 코드는 isolate 및 프로세스 종속 객체에 접근하기 위해 빈번한 참조를 사용해야 했기 때문에 느렸습니다. 루트 상수는 루트 리스트에서 로드되며 (1단계 참조), 다른 힙 상수는 전역 빌트인 상수 풀에서 로드됩니다 (2단계 참조). 외부 참조는 추가적으로 힙 객체 내부에서 풀어야 했습니다 (3단계 참조). 가장 큰 문제는 새로운 호출 순서였고, 트램펄린 Code 객체를 로드하고 이를 호출한 뒤 대상 주소로 점프해야 했습니다. 그리고 관리 힙과 바이너리 임베디드 코드 간의 호출은 본질적으로 느렸던 것으로 보입니다. 이는 CPU의 분기 예측에 간섭하는 긴 점프 거리 때문일 가능성이 있습니다.
따라서 우리의 작업은 1. 참조 단계를 줄이고, 2. 빌트인 호출 순서를 개선하는 데 집중되었습니다. 첫 번째 문제를 해결하기 위해 Isolate 객체 레이아웃을 변경하여 대부분의 객체 로드를 단일 루트 상대 로드로 전환했습니다. 전역 빌트인 상수 풀은 여전히 존재하지만, 드물게 참조되는 객체만 포함합니다.
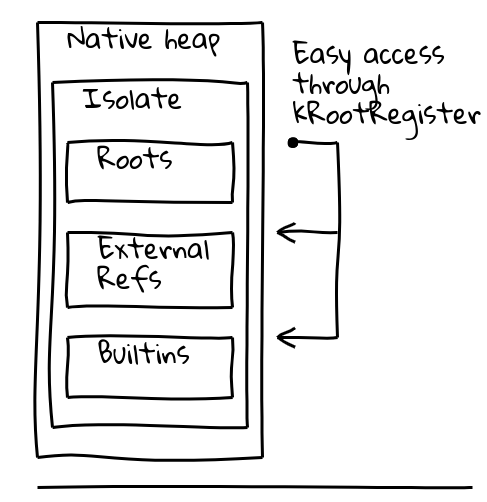
호출 순서는 두 가지 측면에서 크게 개선되었습니다. 빌트인 간 호출은 단일 pc 상대 호출 명령어로 변환되었습니다. 이는 pc 상대 오프셋이 최대 32비트 값을 초과할 수 있기 때문에 런타임 생성 JIT 코드에는 불가능했습니다. 거기서 우리는 오프 힙 트램펄린을 모든 호출 사이트에 인라인하여 호출 순서를 6개 명령어에서 2개 명령어로 줄였습니다.
이 최적화를 통해 Speedometer 2.0의 성능 저하를 약 0.5%로 제한할 수 있었습니다.
결과
우리는 x64에서 임베디드 빌트인이 미치는 영향을 상위 10,000개의 가장 인기 있는 웹사이트에서 평가했으며, 위에서 설명한 게으른 역직렬화와 적극적인 역직렬화 모두와 비교했습니다.
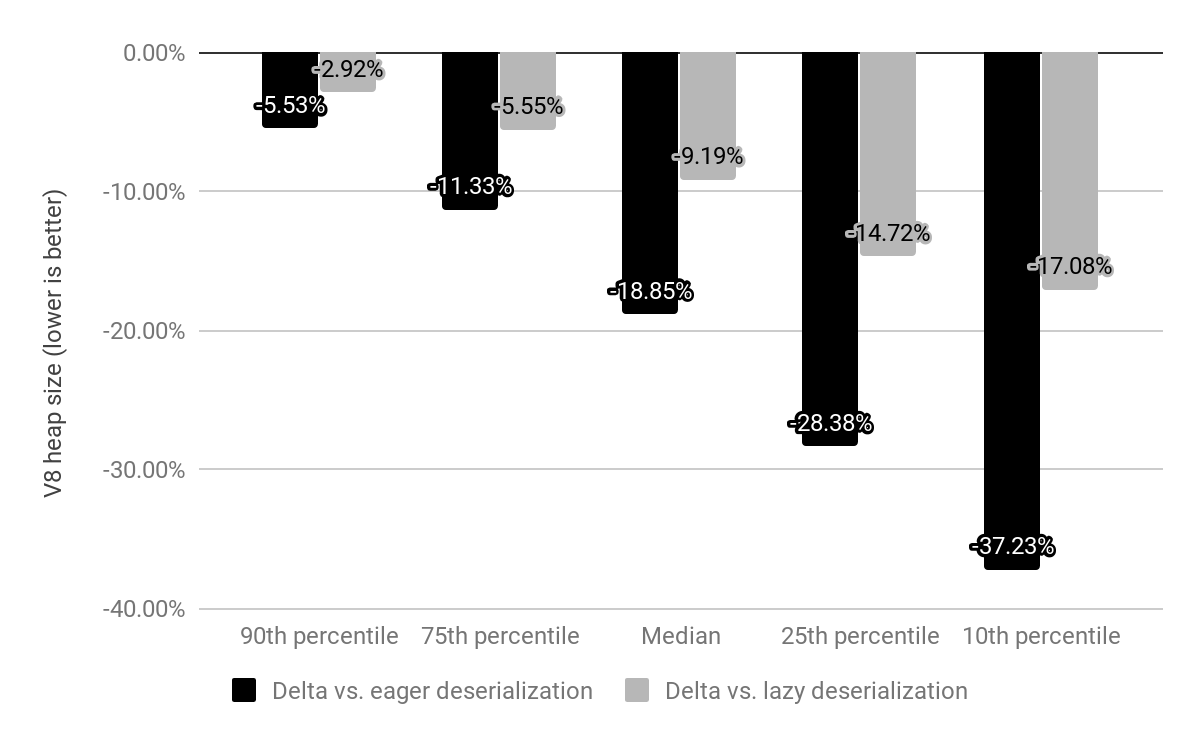
이전에는 Chrome이 각 Isolate에서 역직렬화하는 메모리 매핑된 스냅샷과 함께 제공되었으나, 이제 스냅샷은 여전히 메모리 매핑되지만 역직렬화가 필요하지 않은 임베디드 빌트인으로 대체되었습니다. 빌트인의 비용은 c*(1 + n)이었는데 여기서 n은 Isolate의 수이고 c는 모든 빌트인의 메모리 비용입니다. 하지만 이제 그 비용은 단순히 c * 1입니다. (실제로 오프 힙 트램펄린에 대한 소량의 Isolate별 오버헤드도 여전히 남습니다.)
적극적 역직렬화와 비교했을 때, 우리는 V8 힙 크기의 중앙값을 19% 줄였습니다. 사이트별 Chrome 렌더러 프로세스 크기의 중앙값은 4% 감소했습니다. 절대 숫자로 50번째 백분위 수는 사이트당 1.9 MB를 절약하고, 30번째 백분위 수는 3.4 MB를 절약하며, 10번째 백분위 수는 6.5 MB를 절약합니다.
바이트코드 핸들러가 바이너리로도 임베디드되면 추가적인 메모리 절약이 예상됩니다.
임베디드 빌트인은 Chrome 69에서 x64에 배포 중이며, 모바일 플랫폼은 Chrome 70에서 뒤따를 것입니다. ia32 지원은 2018년 말에 출시될 것으로 예상됩니다.
참고: 모든 다이어그램은 Vyacheslav Egorov의 멋진 Shaky Diagramming 도구를 사용하여 생성되었습니다.