스프레드 요소의 속도 향상
Hai Dang은 V8 팀에서 3개월 간의 인턴십 동안 [...array], [...string], [...set], [...map.keys()], 및 [...map.values()]의 성능을 개선하기 위해 작업했습니다. 그는 또한 Array.from(iterable) 역시 훨씬 빠르게 만들었습니다. 이 기사에서는 그의 수정 사항에 대한 상세 내용을 설명하며, 해당 변경 사항은 v7.2부터 V8에 포함되었습니다.
스프레드 요소
스프레드 요소는 ...iterable 형식의 배열 리터럴 구성 요소입니다. 이 요소들은 ES2015에서 반복 가능한 객체로 배열을 생성하는 방법으로 도입되었습니다. 예를 들어 배열 리터럴 [1, ...arr, 4, ...b]는 첫 번째 요소가 1이며, 배열 arr의 요소들, 4, 그리고 배열 b의 요소들로 이루어진 배열을 생성합니다:
const a = [2, 3];
const b = [5, 6, 7];
const result = [1, ...a, 4, ...b];
// → [1, 2, 3, 4, 5, 6, 7]
또한, 문자열은 펼쳐져 해당 문자를 포함하는 배열을 생성할 수 있습니다 (유니코드 코드 포인트로 표현됨):
const str = 'こんにちは';
const result = [...str];
// → ['こ', 'ん', 'に', 'ち', 'は']
마찬가지로 집합도 삽입 순서대로 정렬된 요소를 포함하는 배열로 펼칠 수 있습니다:
const s = new Set();
s.add('V8');
s.add('TurboFan');
const result = [...s];
// → ['V8', 'TurboFan']
일반적으로 배열 리터럴에서 ...x 형식의 스프레드 요소 문법은 x가 이터레이터를 제공한다는 가정하에 사용됩니다 (이는 x[Symbol.iterator]()를 통해 접근 가능). 이 이터레이터는 결과 배열에 삽입할 요소를 얻기 위해 사용됩니다.
배열 arr를 새 배열로 펼치는 간단한 사용 사례, 즉 [...arr]는 ES2015에서 arr를 얕게 복제하는 간결하고 관용적인 방법으로 간주됩니다. 불행히도, V8에서는 이 관용적 표현의 성능이 ES5와 비교해 크게 뒤처졌습니다. Hai의 인턴십 목표는 이를 변화시키는 것이었습니다!
왜 스프레드 요소가 (혹은 이전에는) 느렸을까?
배열 arr를 얕게 복제할 수 있는 방법은 여러 가지입니다. 예를 들어, arr.slice()를 사용할 수도 있고, arr.concat() 또는 [...arr]를 사용할 수도 있습니다. 또는 표준 for 루프를 사용하는 clone 함수를 작성할 수도 있습니다:
function clone(arr) {
// 배열의 크기를 미리 할당하여 증가시키는 과정을 피합니다.
const result = new Array(arr.length);
for (let i = 0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
이 모든 옵션은 이상적으로 비슷한 성능 특성을 가져야 합니다. 불행히도 V8에서 [...arr]를 선택할 경우, 이 방법은 clone보다 느릴 가능성이 있습니다! 그 이유는 V8이 본질적으로 [...arr]를 다음과 같은 반복으로 변환하기 때문이다:
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
이 코드는 다음의 몇 가지 이유로 clone보다 일반적으로 느릴 수 있습니다:
- 시작 시
Symbol.iterator속성을 로드하고 평가함으로써iterator를 생성해야 합니다. - 매 단계마다
iteratorResult객체를 생성하고 조회해야 합니다. - 반복의 각 단계에서
push를 호출하여result배열을 증가시키므로, 백업 저장소를 반복적으로 재할당해야 합니다.
이런 구현을 사용하는 이유는 앞서 언급한 바와 같이 스프레드는 배열뿐만 아니라 사실상 임의의 iterable 객체에 대해 수행될 수 있으며, 반복 프로토콜을 따라야 하기 때문입니다. 하지만 V8은 펼쳐지는 객체가 배열인지 인식할 수 있도록 충분히 스마트해야 하며, 낮은 수준에서 요소 추출을 수행하여:
- 이터레이터 객체 생성 피하기,
- 이터레이터 결과 객체 생성 피하기,
- 결과 배열을 지속적으로 성장시키고 재할당 피하기 (요소 수를 미리 알고 있음).
우리는 이 간단한 아이디어를 빠른 배열, 즉 가장 일반적인 6가지 요소 유형 중 하나를 사용하는 배열에 대해 CSA를 통해 구현했습니다. 이 최적화는 배열 리터럴 시작 부분에서 펼침이 발생하는 일반적인 실제 시나리오에 적용됩니다. 아래 그래프에 표시된 대로 이 새로운 빠른 경로는 길이가 100,000인 배열을 펼칠 때 약 3배의 성능 향상을 제공하며, 수작업으로 작성된 clone 루프보다 약 25% 더 빠릅니다.
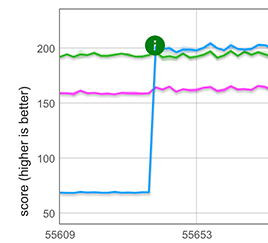
참고: 여기에는 표시되지 않았지만, 빠른 경로는 펼친 요소 뒤에 다른 구성 요소가 있을 때(예: [...arr, 1, 2, 3])에도 적용됩니다. 그러나 앞에 다른 요소가 있을 때(예: [1, 2, 3, ...arr])에는 적용되지 않습니다.
빠른 경로를 신중히 밟아야 합니다
이는 명확히 인상적인 속도 향상입니다. 하지만 이 빠른 경로를 선택하는 것이 올바른 경우에 대해 매우 신중해야 합니다. JavaScript에서는 프로그래머가 객체(심지어 배열 포함)의 반복 동작을 여러 방식으로 수정할 수 있습니다. 펼친 요소는 반복 프로토콜을 사용하도록 지정되어 있기 때문에 이러한 수정사항이 존중되도록 해야 합니다. 원래 반복 메커니즘이 변경되었을 경우에는 빠른 경로를 완전히 피함으로써 이를 달성합니다. 다음과 같은 상황이 이에 포함됩니다.
자체 Symbol.iterator 속성
일반적으로 배열 arr는 자체 Symbol.iterator 속성이 없습니다. 따라서 해당 기호를 찾을 때 배열의 프로토타입에서 찾게 됩니다. 아래 예에서는 arr 자체에 Symbol.iterator 속성을 직접 정의하여 프로토타입을 우회합니다. 이 수정 후, Symbol.iterator를 arr에서 찾으면 빈 반복기를 반환하며, 따라서 arr를 펼치면 요소가 없고 배열 리터럴은 빈 배열로 평가됩니다.
const arr = [1, 2, 3];
arr[Symbol.iterator] = function() {
return { next: function() { return { done: true }; } };
};
const result = [...arr];
// → []
수정된 %ArrayIteratorPrototype%
next 메서드는 %ArrayIteratorPrototype%, 즉 배열 반복기의 프로토타입에서 직접 수정할 수도 있습니다. 이는 모든 배열에 영향을 미칩니다.
Object.getPrototypeOf([][Symbol.iterator]()).next = function() {
return { done: true };
}
const arr = [1, 2, 3];
const result = [...arr];
// → []
노치가 있는 배열 처리
노치가 있는 배열, 즉 ['a', , 'c']처럼 일부 요소가 누락된 배열을 복사할 때도 추가로 주의가 필요합니다. 이러한 배열을 펼치면 반복 프로토콜을 준수하기 때문에 노치가 유지되지 않고, 대신 배열의 프로토타입에서 해당 인덱스에 발견된 값으로 채워집니다. 기본적으로 배열의 프로토타입에는 요소가 없으므로 어떤 노치는 undefined로 채워집니다. 예를 들어, [...['a', , 'c']]는 새로운 배열 ['a', undefined, 'c']로 평가됩니다.
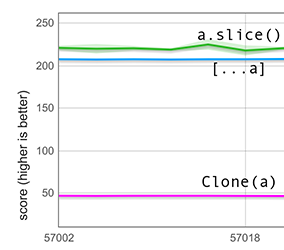
기본 상황에서는 우리의 빠른 경로가 노치를 처리할 만큼 충분히 스마트합니다. 입력 배열의 백업 저장소를 맹목적으로 복사하는 대신, 노치를 감지하고 이를 undefined 값으로 변경합니다. 아래 그래프는 600개의 정수(태그됨)를 제외하고 나머지는 노치가 있는 길이가 100,000인 입력 배열에 대한 측정을 포함하며, 이러한 노치가 있는 배열을 펼치는 것이 예전보다 4배 이상 빠르다는 것을 보여줍니다. (이전에 동일한 수준이었지만, 이는 그래프에 표시되지 않음).
그래프에는 slice도 포함되어 있지만, 이는 공정한 비교가 아닙니다. slice는 노치가 있는 배열에 대해 다른 의미론적 동작을 하며 모든 노치를 유지하므로 작업량이 훨씬 적습니다.
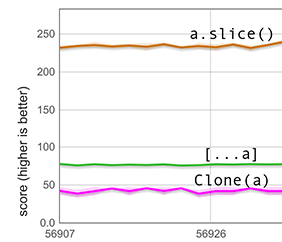
undefined로 노치를 채우는 것이 생각처럼 간단하지 않습니다: 이는 전체 배열을 다른 요소 유형으로 변환해야 할 수도 있습니다. 다음 그래프는 이러한 상황을 측정합니다. 설정은 위와 동일하지만 이번에는 600개의 배열 요소가 언박싱된 더블이고 배열은 HOLEY_DOUBLE_ELEMENTS 요소 유형을 가지고 있습니다. 이 요소 유형은 undefined와 같은 태그된 값을 가질 수 없으므로 펼치기는 비용이 많이 드는 요소 유형 전환을 포함하며, 이전 그래프보다 [...a]의 점수가 훨씬 낮습니다. 그럼에도 불구하고 clone(a)보다 훨씬 빠릅니다.
문자열, 세트 및 맵 펼치기
반복기 객체를 건너뛰고 결과 배열의 크기 증가를 방지하는 개념은 다른 표준 데이터 유형을 펼치는 경우에도 동일하게 적용됩니다. 실제로 원시 문자열, 세트 및 맵에 대해 유사한 빠른 경로를 구현했으며, 수정된 반복 동작이 있는 경우 이를 효과적으로 우회합니다.
세트의 경우, 빠른 경로는 세트를 직접 펼치기([...set])뿐만 아니라 키 반복기([...set.keys()])와 값 반복기([...set.values()])를 펼치는 것도 지원합니다. 우리의 마이크로 벤치마크에서 이러한 작업은 이전보다 약 18배 더 빠르다고 나타났습니다.
맵의 빠른 경로는 유사하지만 맵을 직접 펼치는 작업([...map])을 지원하지 않습니다. 이는 흔하지 않은 작업으로 간주하기 때문입니다. 동일한 이유로 빠른 경로는 entries() 반복자를 지원하지 않습니다. 마이크로 벤치마크에서 이러한 작업은 이전보다 약 14배 더 빨라졌습니다.
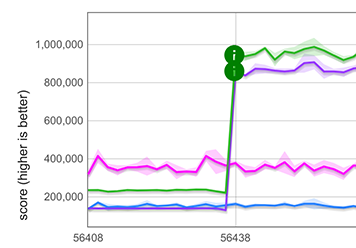
문자열 펼치기([...string])에 대해 약 5배의 개선을 측정했으며, 아래 그래프의 보라색과 녹색 선으로 표시됩니다. 이는 TurboFan으로 최적화된 for-of 루프(TurboFan은 문자열 반복을 이해하고 이에 대한 최적화된 코드를 생성할 수 있음)보다 더 빠릅니다. 그래프의 파란색과 분홍색 선이 이를 나타냅니다. 각 경우에 두 개의 그래프가 있는 이유는 마이크로 벤치마크가 두 가지 다른 문자열 표현(one-byte 문자열과 two-byte 문자열)에서 작동하기 때문입니다.
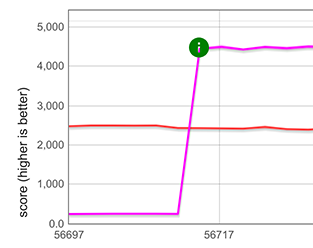
Array.from 성능 개선
다행히도, spread 요소에 대한 빠른 경로는 Array.from이 반복 가능한 객체와 매핑 함수 없이 호출되는 경우에 재사용될 수 있습니다. 예를 들어, Array.from([1, 2, 3]). 이 재사용이 가능한 이유는 이 경우 Array.from의 동작이 펼치기와 정확히 동일하기 때문입니다. 이는 아래에 100개의 더블이 포함된 배열에 대해 표시된 것처럼 엄청난 성능 향상을 가져옵니다.
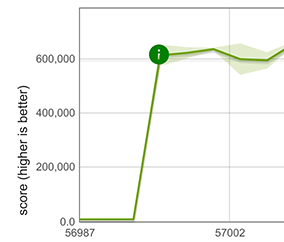
결론
V8 v7.2 / Chrome 72는 배열 리터럴 앞에 등장하는 spread 요소의 성능을 대폭 개선합니다. 예를 들어 [...x] 또는 [...x, 1, 2]. 이 개선 사항은 배열, 원시 문자열, 집합, 맵 키, 맵 값의 펼치기에 적용되며, 이를 확장하여 Array.from(x)에도 적용됩니다.