빠른 `for`-`in` V8
for-in은 많은 프레임워크에서 널리 사용되는 언어 기능입니다. 그 보편성에도 불구하고, 구현 관점에서는 비교적 모호한 언어 구조 중 하나입니다. V8은 이 기능을 가능한 한 빠르게 만들기 위해 많은 노력을 기울였습니다. 지난 1년 동안, for-in은 완전히 사양을 준수하게 되었고 문맥에 따라 최대 3배 빨라졌습니다.
많은 인기 웹사이트는 for-in을 상당히 많이 사용하며 최적화의 이점을 누리고 있습니다. 예를 들어, 2016년 초 Facebook은 시작 시 for-in 구현에서 JavaScript 시간의 약 7%를 소비했습니다. Wikipedia에서는 이 숫자가 약 8%로 더 높았습니다. 특정 느린 사례의 성능을 개선함으로써 Chrome 51은 이 두 웹사이트에서 성능을 크게 향상시켰습니다:


Wikipedia와 Facebook 모두 다양한 for-in 개선 덕분에 전체 스크립트 시간이 4% 줄었습니다. 동일 기간 동안 V8의 나머지 부분도 빨라져 최종적으로 4% 이상의 전체 스크립팅 개선 효과가 있었습니다.
이 블로그 게시물의 나머지 부분에서는 이 핵심 언어 기능을 어떻게 가속화했으며 동시에 오래된 사양 위반을 수정했는지 설명하겠습니다.
사양
요약: 성능상의 이유로 for-in 반복 구문은 모호하게 정의됩니다.
for-in의 사양 텍스트를 보면, 예상치 못하게 모호한 방식으로 작성되어 있으며 이는 다양한 구현에서 관찰됩니다. 적절한 트랩이 설정된 Proxy 객체를 반복할 때 예제를 살펴보겠습니다.
const proxy = new Proxy({ a: 1, b: 1},
{
getPrototypeOf(target) {
console.log('getPrototypeOf');
return null;
},
ownKeys(target) {
console.log('ownKeys');
return Reflect.ownKeys(target);
},
getOwnPropertyDescriptor(target, prop) {
console.log('getOwnPropertyDescriptor name=' + prop);
return Reflect.getOwnPropertyDescriptor(target, prop);
}
});
V8/Chrome 56에서 다음과 같은 출력이 나타납니다:
ownKeys
getPrototypeOf
getOwnPropertyDescriptor name=a
a
getOwnPropertyDescriptor name=b
b
대조적으로, Firefox 51에서는 동일한 코드 조각에 대해 명령어 순서가 다릅니다:
ownKeys
getOwnPropertyDescriptor name=a
getOwnPropertyDescriptor name=b
getPrototypeOf
a
b
두 브라우저 모두 사양을 준수하지만 사양에서는 명령어 순서를 명시적으로 지정하지 않습니다. 이런 빈틈을 제대로 이해하려면 사양 텍스트를 살펴보겠습니다:
EnumerateObjectProperties ( O ) 매개변수 O로 EnumerateObjectProperties 추상 작업을 호출하면, 다음 단계가 수행됩니다:
- 확인: O의 타입이 객체임을 확인합니다.
- 객체 O의 열거 가능한 속성의 문자열 키를 반복하는 next 메서드를 가지는 Iterator 객체(25.1.1.2)를 반환합니다. 이 iterator 객체는 ECMAScript 코드에서 직접 접근할 수 없습니다. 속성을 열거하는 메커니즘과 순서는 명시되지 않았지만, 아래에 명시된 규칙을 준수해야 합니다.
일반적으로 사양의 지침은 정확한 수행 단계를 명확히 정의합니다. 그러나 이 경우, 단순한 서술 목록을 참조하며 실행 순서조차 구현자에게 맡깁니다. 일반적으로 이러한 부분은 JavaScript 엔진이 이미 다른 구현을 가진 상태에서 사양이 후에 작성되었을 때 발생합니다. 사양은 다음 지침을 제공함으로써 헐거운 끝을 묶으려 합니다:
- 반복자의 throw 및 return 메서드는 null이며 호출되지 않습니다.
- 반복자의 next 메서드는 객체 속성을 처리하여 속성 키가 반복자 값으로 반환되어야 하는지 결정합니다.
- 반환된 속성 키는 Symbol을 포함하지 않습니다.
- 반복 도중 대상 객체의 속성이 삭제될 수 있습니다.
- 반복자의 next 메서드에 의해 처리되기 전에 삭제된 속성은 무시됩니다. 반복 중 대상 객체에 새 속성이 추가되더라도 활성 반복에서 처리될 보장은 없습니다.
- 속성 이름은 반복자의 next 메서드에 의해 단일 반복에서 최대 한 번만 반환됩니다.
- 대상 객체의 속성을 열거하는 것은 해당 프로토타입의 속성과 프로토타입의 프로토타입 등에 대해 순환적으로 속성을 열거하는 것을 포함하지만, 프로토타입의 속성이 이미 반복자의 next 메서드에 의해 처리된 속성과 동일한 이름을 가지고 있는 경우 해당 속성은 처리되지 않습니다.
- 프로토타입 객체의 속성이 이미 처리되었는지 확인할 때
[[Enumerable]]특성의 값은 고려되지 않습니다. - 프로토타입 객체의 열거 가능한 속성 이름은 프로토타입 객체를 인자로 전달하여 EnumerateObjectProperties를 호출하여 얻어야 합니다.
- EnumerateObjectProperties는 대상 객체의 자체 속성 키를
[[OwnPropertyKeys]]내부 메서드를 호출하여 얻어야 합니다.
이 단계들은 번거롭게 들릴 수 있지만, 명세서에는 명시적이고 훨씬 더 읽기 쉬운 구현 예제가 포함되어 있습니다:
function* EnumerateObjectProperties(obj) {
const visited = new Set();
for (const key of Reflect.ownKeys(obj)) {
if (typeof key === 'symbol') continue;
const desc = Reflect.getOwnPropertyDescriptor(obj, key);
if (desc && !visited.has(key)) {
visited.add(key);
if (desc.enumerable) yield key;
}
}
const proto = Reflect.getPrototypeOf(obj);
if (proto === null) return;
for (const protoKey of EnumerateObjectProperties(proto)) {
if (!visited.has(protoKey)) yield protoKey;
}
}
지금까지 진행되어 이전의 예제에서 확인했듯이, V8이 명세서의 예제 구현을 정확히 따르지 않는다는 것을 알아챘을 것입니다. 우선, 예제 for-in 생성기는 점진적으로 작동하는 반면, V8은 대부분 성능상의 이유로 처음부터 모든 키를 수집합니다. 이는 완전히 괜찮고 명세서에서도 A - J의 연산 순서는 정의되지 않았음을 명시적으로 언급하고 있습니다. 하지만, 이 글의 후반부에서 확인할 수 있듯이 V8은 2016년까지 명세서를 완전히 준수하지 않는 몇 가지 특이한 사례들이 있었습니다.
Enum 캐시
for-in 생성기의 예제 구현은 키를 수집하고 내보내는 점진적 패턴을 따릅니다. V8에서는 속성 키를 첫 단계에서 수집하고 나서야 반복 단계에서 사용됩니다. V8에서는 이를 통해 몇 가지 작업을 보다 쉽게 처리할 수 있습니다. 그 이유를 이해하려면 객체 모델을 살펴볼 필요가 있습니다.
{a:'value a', b:'value b', c:'value c'} 같은 간단한 객체는 자세한 속성에 관한 후속 게시물에서 보여드릴 V8 내 다양한 내부 표현을 가질 수 있습니다. 이는 우리가 가진 속성의 종류 — 객체 내 속성, 빠른 속성, 느린 속성 —에 따라 실제 속성 이름이 저장되는 위치가 달라지기 때문입니다. 따라서 열거 가능한 키를 수집하는 것은 간단한 일이 아닙니다.
V8은 숨겨진 클래스 또는 소위 맵을 통해 객체의 구조를 추적합니다. 동일한 맵을 가진 객체는 같은 구조를 가집니다. 또한 각 맵은 속성에 대한 세부 정보를 포함하는 공용 데이터 구조, 설명자 배열을 공유합니다. 여기에는 속성이 저장된 위치, 속성 이름, 열거 가능성과 같은 세부 정보가 포함됩니다.
우리의 JavaScript 객체가 최종 형태에 도달했으며 더 이상 속성이 추가되거나 제거되지 않는다고 가정해 봅시다. 이 경우 설명자 배열을 키의 소스로 사용할 수 있습니다. 이는 열거 가능한 속성만 있는 경우에만 작동합니다. 각 열거에서 비열거 속성을 필터링하는 작업의 오버헤드를 피하기 위해 V8은 맵's의 설명자 배열을 통해 액세스할 수 있는 별도의 EnumCache를 사용합니다.

V8은 느린 사전 객체가 자주 변경된다고 예상하기 때문에 (예: 속성을 추가하거나 제거하면서), 사전 속성이 있는 느린 객체에는 설명자 배열이 없습니다. 따라서 느린 속성에는 EnumCache를 제공하지 않습니다. 유사한 가정은 인덱싱된 속성에도 적용되며, 따라서 이들도 EnumCache에서 제외됩니다.
중요한 사실들을 요약합시다:
- 맵은 객체 형상을 추적하는 데 사용됩니다.
- 설명자 배열은 속성에 대한 정보(이름, 구성 가능성, 가시성)를 저장합니다.
- 맵 간 설명자 배열을 공유할 수 있습니다.
- 각 설명자 배열에는 열거 가능한 이름 키만 나열하는 EnumCache가 포함될 수 있으며, 인덱싱된 속성 이름은 포함되지 않습니다.
for-in의 메커니즘
이제 맵과 EnumCache가 설명자 배열과 어떻게 관련되는지 부분적으로 이해하셨습니다. V8은 Ignition, 바이트코드 인터프리터 및 TurboFan(최적화 컴파일러)을 통해 JavaScript를 실행하며 둘 다 for-in을 비슷한 방식으로 처리합니다. 간단히 설명하기 위해 내부적으로 for-in이 어떻게 구현되는지 의사 C++ 스타일을 사용해 보겠습니다:
// For-In Prepare:
FixedArray* keys = nullptr;
Map* original_map = object->map();
if (original_map->HasEnumCache()) {
if (object->HasNoElements()) {
keys = original_map->GetCachedEnumKeys();
} else {
keys = object->GetCachedEnumKeysWithElements();
}
} else {
keys = object->GetEnumKeys();
}
// For-In Body:
for (size_t i = 0; i < keys->length(); i++) {
// For-In Next:
String* key = keys[i];
if (!object->HasProperty(key) continue;
EVALUATE_FOR_IN_BODY();
}
for-in은 세 가지 주요 단계로 나눌 수 있습니다:
- 반복할 키 준비,
- 다음 키 가져오기,
for-in본문 평가.
"준비" 단계는 이 세 단계 중 가장 복잡하며 EnumCache가 사용되는 부분입니다. 위 예제에서 볼 수 있듯이, V8은 EnumCache가 존재하고 객체(및 그 프로토타입)에 요소(정수 인덱스 특성)가 없는 경우 직접적으로 EnumCache를 사용합니다. 인덱스화된 속성 이름이 있는 경우, V8은 C++로 구현된 런타임 함수로 이동하여 기존 enum 캐시에 이를 추가합니다. 다음 예제는 이를 설명합니다:
FixedArray* JSObject::GetCachedEnumKeysWithElements() {
FixedArray* keys = object->map()->GetCachedEnumKeys();
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* Map::GetCachedEnumKeys() {
// 공유될 수 있는 enum 캐시에서 열거 가능한 속성 키를 가져옴
FixedArray* keys_cache = descriptors()->enum_cache()->keys_cache();
if (enum_length() == keys_cache->length()) return keys_cache;
return keys_cache->CopyUpTo(enum_length());
}
FixedArray* FastElementsAccessor::PrependElementIndices(
JSObject* object, FixedArray* property_keys) {
Assert(object->HasFastElements());
FixedArray* elements = object->elements();
int nof_indices = CountElements(elements)
FixedArray* result = FixedArray::Allocate(property_keys->length() + nof_indices);
int insertion_index = 0;
for (int i = 0; i < elements->length(); i++) {
if (!HasElement(elements, i)) continue;
result[insertion_index++] = String::FromInt(i);
}
// 속성 키를 끝에 삽입
property_keys->CopyTo(result, nof_indices - 1);
return result;
}
기존 EnumCache가 없는 경우 다시 C++로 이동하여 처음에 제시된 사양 단계들을 따릅니다.
FixedArray* JSObject::GetEnumKeys() {
// 수신자의 enum 키를 가져옴
FixedArray* keys = this->GetOwnEnumKeys();
// 프로토타입 체인을 따라 이동
for (JSObject* object : GetPrototypeIterator()) {
// 중복되지 않은 키를 리스트에 추가
keys = keys->UnionOfKeys(object->GetOwnEnumKeys());
}
return keys;
}
FixedArray* JSObject::GetOwnEnumKeys() {
FixedArray* keys;
if (this->HasEnumCache()) {
keys = this->map()->GetCachedEnumKeys();
} else {
keys = this->GetEnumPropertyKeys();
}
if (this->HasFastProperties()) this->map()->FillEnumCache(keys);
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* FixedArray::UnionOfKeys(FixedArray* other) {
int length = this->length();
FixedArray* result = FixedArray::Allocate(length + other->length());
this->CopyTo(result, 0);
int insertion_index = length;
for (int i = 0; i < other->length(); i++) {
String* key = other->get(i);
if (other->IndexOf(key) == -1) {
result->set(insertion_index, key);
insertion_index++;
}
}
result->Shrink(insertion_index);
return result;
}
이 단순화된 C++ 코드는 2016년 초까지 V8 구현과 일치하며 UnionOfKeys 메서드가 검토되었습니다. 자세히 보면, 우리는 중복 항목을 제외하기 위해 리스트에 단순한 알고리즘을 사용했으며, 이는 프로토타입 체인에 많은 키가 있을 경우 성능이 저하될 수 있음을 알 수 있습니다. 이러한 이유로 다음 섹션에서 최적화를 추구하게 되었습니다.
for-in의 문제점
앞서 언급했듯이, UnionOfKeys 메서드는 최악의 성능을 보입니다. 이는 대부분의 객체가 빠른 속성을 가지며 EnumCache의 이점을 받는다는 유효한 가정에 기반합니다. 두 번째 가정은 프로토타입 체인에 열거 가능한 속성이 적어 중복을 찾는 데 필요한 시간이 제한된다는 것입니다. 그러나 객체에 느린 사전 속성이 있고 프로토타입 체인에 많은 키가 있는 경우 UnionOfKeys는 for-in에 진입할 때마다 열거 가능한 속성 이름을 수집해야 하므로 성능 병목현상이 됩니다.
성능 문제 외에도 기존 알고리즘은 사양에 부합하지 않는 또 다른 문제가 있었습니다. V8은 많은 해 동안 다음 예제를 잘못 처리했습니다.
var o = {
__proto__ : {b: 3},
a: 1
};
Object.defineProperty(o, 'b', {});
for (var k in o) console.log(k);
출력:
a
b
아마도 직관적이지 않게, 이는 a만 출력되어야 하며 a와 b는 출력되지 않아야 맞습니다. 이 글의 시작 부분에서 제공된 사양 텍스트를 다시 살펴보면, 단계 G와 J는 수신자의 비열거 속성이 프로토타입 체인의 속성을 가린다고 암시합니다.
문제를 더 복잡하게 만든 것은 ES6이 프록시 객체를 도입한 것입니다. 이로 인해 V8 코드의 많은 가정이 깨졌습니다. for-in을 사양에 부합하도록 구현하려면 총 13개의 프록시 트랩 중 다음 5가지를 실행해야 합니다.
| 내부 메서드 | 핸들러 메서드 |
|---|---|
[[GetPrototypeOf]] | getPrototypeOf |
[[GetOwnProperty]] | getOwnPropertyDescriptor |
[[HasProperty]] | has |
[[Get]] | get |
[[OwnPropertyKeys]] | ownKeys |
2016년 초, ES6 프록시와 그림자 속성 처리가 부족했던 점이 핵심 동기가 되어 for-in을 위한 모든 키를 추출하는 방법을 재구성했습니다. 원래의 GetEnumKeys 코드와 스펙 예시 구현을 더 가깝게 따르려고 했던 중복된 버전을 필요로 했습니다.
KeyAccumulator
우리는 KeyAccumulator라는 별도의 보조 클래스를 도입하여 for-in 키 수집의 복잡성을 다뤘습니다. ES6 스펙이 성장함에 따라, Object.keys나 Reflect.ownKeys 같은 새로운 기능은 키를 수집하는 약간 수정된 버전을 필요로 했습니다. 단일 구성 가능한 장소를 가짐으로써 for-in의 성능을 개선하고 코드 중복을 방지할 수 있었습니다.
KeyAccumulator는 제한된 작업 세트를 지원하지만 이를 매우 효율적으로 수행할 수 있는 빠른 부분으로 구성됩니다. 느린 누적기는 ES6 프록시같은 모든 복잡한 케이스를 지원합니다.

그림자 속성을 올바르게 걸러내려면 지금까지 본 비열거 가능한 속성의 별도 목록을 유지해야 합니다. 성능상의 이유로 객체의 프로토타입 체인에 열거 가능한 속성이 있음을 파악한 후에만 이를 수행합니다.
성능 개선
KeyAccumulator가 제자리에 있는 상태에서 몇 가지 패턴을 더 최적화할 수 있게 되었습니다. 첫 번째는 느린 코너 케이스를 초래하던 원래의 UnionOfKeys 메서드의 중첩 루프를 피하는 것이었습니다. 두 번째 단계에서는 기존 EnumCaches를 활용하고 불필요한 복사 단계를 피하기 위해 더욱 상세한 사전 검사를 수행했습니다.
스펙 준수 구현이 더 빠르다는 것을 보여주기 위해 다음 네 가지 다른 객체를 살펴보겠습니다:
var fastProperties = {
__proto__ : null,
'property 1': 1,
…
'property 10': n
};
var fastPropertiesWithPrototype = {
'property 1': 1,
…
'property 10': n
};
var slowProperties = {
__proto__ : null,
'dummy': null,
'property 1': 1,
…
'property 10': n
};
delete slowProperties['dummy']
var elements = {
__proto__: null,
'1': 1,
…
'10': n
}
fastProperties객체는 표준 빠른 속성을 가지고 있습니다.fastPropertiesWithPrototype객체는Object.prototype을 사용하여 프로토타입 체인에 추가적으로 비열거 가능한 속성을 가지고 있습니다.slowProperties객체는 느린 사전 속성을 가지고 있습니다.elements객체는 인덱싱된 속성만 가지고 있습니다.
다음 그래프는 최적화 컴파일러의 도움 없이 밀집 루프에서 for-in 루프를 백만 번 실행한 원래 성능을 비교합니다.
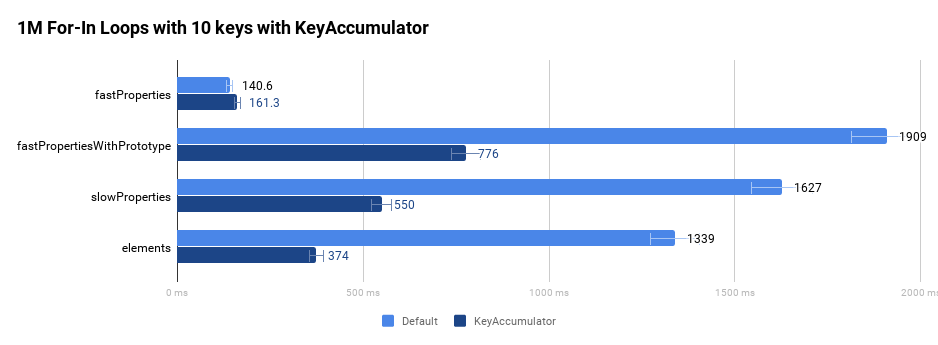
소개에서 언급했듯이, 이러한 개선은 특히 Wikipedia와 Facebook에서 매우 두드러지게 나타났습니다.
Chrome 51에서 제공되는 초기 개선 외에도 두 번째 성능 조정을 통해 또 다른 의미 있는 개선을 이뤄냈습니다. 다음 그래프는 Facebook 페이지 시작 중 스크립팅에 소비된 총 시간을 보여줍니다. 선택된 V8 수정본 37937 경계는 추가적으로 4%의 성능 개선에 해당합니다!

for-in을 개선하는 것이 얼마나 중요한지를 강조하기 위해 2016년에 우리가 만든 도구 데이터를 활용할 수 있습니다. 이 도구는 다양한 웹사이트 세트에서 V8 측정을 추출하도록 합니다. 다음 표는 약 25개의 대표적인 실제 웹사이트에서 Chrome 49의 V8 C++ 진입점(runtime 함수와 빌트인)에 소비된 상대적 시간을 보여줍니다.
| 순위 | 이름 | 총 시간 |
|---|---|---|
| 1 | CreateObjectLiteral | 1.10% |
| 2 | NewObject | 0.90% |
| 3 | KeyedGetProperty | 0.70% |
| 4 | GetProperty | 0.60% |
| 5 | ForInEnumerate | 0.60% |
| 6 | SetProperty | 0.50% |
| 7 | StringReplaceGlobalRegExpWithString | 0.30% |
| 8 | HandleApiCallConstruct | 0.30% |
| 9 | RegExpExec | 0.30% |
| 10 | ObjectProtoToString | 0.30% |
| 11 | ArrayPush | 0.20% |
| 12 | NewClosure | 0.20% |
| 13 | NewClosure_Tenured | 0.20% |
| 14 | ObjectDefineProperty | 0.20% |
| 15 | HasProperty | 0.20% |
| 16 | StringSplit | 0.20% |
| 17 | ForInFilter | 0.10% |