Builtin embutidos
As funções embutidas do V8 (builtins) consomem memória em cada instância do V8. A contagem de builtins, o tamanho médio e o número de instâncias do V8 por aba do navegador Chrome aumentaram significativamente. Este post descreve como reduzimos o tamanho mediano do heap do V8 por site em 19% no último ano.
Contexto
V8 vem com uma biblioteca extensiva de funções embutidas (builtins) em JavaScript (JS). Muitos builtins são diretamente acessíveis a desenvolvedores JS como funções instaladas em objetos embutidos de JS, como RegExp.prototype.exec e Array.prototype.sort; outros builtins implementam diversas funcionalidades internas. Código de máquina para builtins é gerado pelo próprio compilador do V8 e carregado no estado de heap gerenciado para cada Isolate do V8 durante a inicialização. Um Isolate representa uma instância isolada do motor V8, e cada aba do navegador Chrome contém pelo menos um Isolate. Cada Isolate possui seu próprio heap gerenciado, e, portanto, sua própria cópia de todos os builtins.
Em 2015, os builtins eram geralmente implementados em JS auto-hospedado, montagem nativa ou em C++. Eram relativamente pequenos, e criar uma cópia para cada Isolate era menos problemático.
Muito mudou nesse espaço ao longo dos últimos anos.
Em 2016, o V8 começou a experimentar com builtins implementados em CodeStubAssembler (CSA). Isso provou ser tanto conveniente (independente de plataforma, legível) quanto produzir código eficiente, então os builtins de CSA se tornaram ubíquos. Por uma variedade de razões, os builtins de CSA tendem a produzir código maior, e o tamanho dos builtins do V8 aproximadamente triplicou conforme mais e mais foram deslocados para o CSA. Em meados de 2017, sua sobrecarga por Isolate havia crescido significativamente e começamos a pensar em uma solução sistemática.
No final de 2017, implementamos desserialização preguiçosa de builtins (e manipuladores de bytecode) como um primeiro passo. Nossa análise inicial mostrou que a maioria dos sites utilizava menos da metade de todos os builtins. Com a desserialização preguiçosa, os builtins são carregados sob demanda, e os builtins não utilizados nunca são carregados no Isolate. A desserialização preguiçosa foi lançada no Chrome 64 com economias promissoras de memória. No entanto, a sobrecarga de memória dos builtins ainda era linear no número de Isolates.
Depois, Spectre foi divulgado, e o Chrome acabou ativando isolamento de site para mitigar seus efeitos. O isolamento de site limita um processo renderizador do Chrome a documentos de uma única origem. Portanto, com isolamento de site, muitas abas de navegação criam mais processos renderizadores e mais Isolates do V8. Apesar de sempre ter sido importante gerenciar a sobrecarga por Isolate, o isolamento de site tornou isso ainda mais crucial.
Builtins embutidos
Nosso objetivo para este projeto era eliminar completamente a sobrecarga de builtins por Isolate.
A ideia por trás disso era simples. Conceitualmente, os builtins são idênticos entre Isolates, e estão vinculados a um Isolate apenas por detalhes de implementação. Se conseguíssemos tornar os builtins verdadeiramente independentes de Isolate, poderíamos manter uma única cópia na memória e compartilhá-los entre todos os Isolates. E se conseguíssemos torná-los independentes de processo, poderiam até mesmo ser compartilhados entre processos.
Na prática, enfrentamos vários desafios. O código gerado para builtins não era independente de Isolate nem de processo devido a ponteiros incorporados para dados específicos de Isolate e de processo. O V8 não tinha conceito de executar código gerado localizado fora do heap gerenciado. Os builtins precisavam ser compartilhados entre processos, idealmente reutilizando mecanismos já existentes do sistema operacional. E, finalmente (isso acabou sendo o longo caminho), o desempenho não poderia regredir perceptivelmente.
As seções a seguir descrevem nossa solução em detalhe.
Código independente de Isolate e processo
Os builtins são gerados pela pipeline interna do compilador do V8, que incorpora referências a constantes de heap (localizadas no heap gerenciado do Isolate), alvos de chamada (objetos Code, também no heap gerenciado) e endereços específicos de Isolate e processo (por exemplo: funções de runtime C ou um ponteiro para o próprio Isolate, também chamados de 'referências externas') diretamente no código. Em montagem x64, o carregamento de um desses objetos poderia ser assim:
// Carregar um endereço embutido no registrador rbx.
REX.W movq rbx,0x56526afd0f70
O V8 possui um coletor de lixo móvel, e a localização do objeto-alvo pode mudar com o tempo. Caso o alvo seja movido durante a coleta, o GC atualiza o código gerado para apontar para a nova localização.
No x64 (e na maioria das outras arquiteturas), chamadas para outros objetos Code utilizam uma instrução de chamada eficiente que especifica o alvo da chamada por um deslocamento do contador de programa atual (um detalhe interessante: o V8 reserva todo o seu CODE_SPACE na pilha gerenciada durante a inicialização para garantir que todos os objetos Code possíveis permaneçam dentro de um deslocamento endereçável entre si). A parte relevante da sequência de chamada se parece com isto:
// Instrução de chamada localizada em [pc + <offset>].
call <offset>
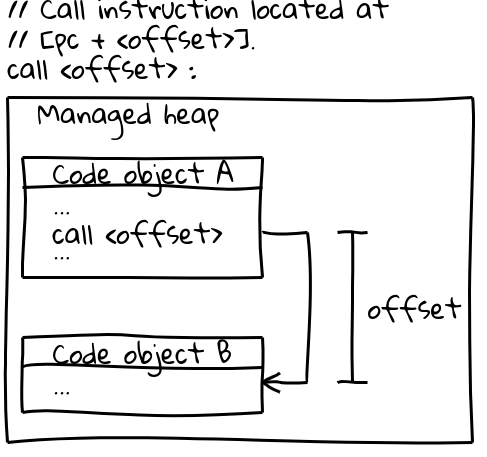
Os objetos Code em si vivem na pilha gerenciada e são móveis. Quando são movidos, o GC atualiza o deslocamento em todos os locais de chamada relevantes.
Para compartilhar builtins entre processos, o código gerado deve ser imutável, bem como independente de isolamento e de processos. Ambas sequências de instrução acima não atendem a esse requisito: elas incorporam diretamente endereços no código e são corrigidas em tempo de execução pelo GC.
Para tratar ambos os problemas, introduzimos uma indireção por meio de um registro dedicado, chamado registro raiz, que mantém um ponteiro em uma localização conhecida dentro do Isolate atual.

A classe Isolate do V8 contém a tabela de raízes, que por si só contém ponteiros para objetos raiz na pilha gerenciada. O registro raiz mantém permanentemente o endereço da tabela de raízes.
O novo método independente de isolamento e de processo para carregar um objeto raiz torna-se:
// Carrega o endereço constante localizado no
// deslocamento dado a partir das raízes.
REX.W movq rax,[kRootRegister + <offset>]
Constantes na pilha de raízes podem ser carregadas diretamente da lista de raízes conforme acima. Outras constantes da pilha utilizam uma indireção adicional por meio de um pool de constantes de builtins global, armazenado na própria lista de raízes:
// Carrega o pool de constantes de builtins, depois a
// constante desejada.
REX.W movq rax,[kRootRegister + <offset>]
REX.W movq rax,[rax + 0x1d7]
Para alvos Code, inicialmente mudamos para uma sequência de chamada mais detalhada que carrega o objeto Code alvo do pool de constantes de builtins global conforme acima, carrega o endereço alvo em um registrador e, finalmente, realiza uma chamada indireta.
Com essas mudanças, o código gerado tornou-se independente de isolamento e processo, e pudemos começar a trabalhar no compartilhamento entre processos.
Compartilhando entre processos
Inicialmente avaliamos duas alternativas. Builtins poderiam ser compartilhados pelo mapeamento (mmap) de um arquivo blob de dados na memória; ou, poderiam ser incorporados diretamente no binário. Optamos pela última abordagem, pois ela tinha a vantagem de reutilizar automaticamente os mecanismos padrão do SO para compartilhar memória entre processos, e a alteração não exigiria lógica adicional de integrações do V8, como o Chrome. Estávamos confiantes nesta abordagem, pois a compilação AOT do Dart já havia incorporado com sucesso código gerado em binários.
Um arquivo binário executável é dividido em várias seções. Por exemplo, um binário ELF contém dados nas seções .data (dados inicializados), .ro_data (dados inicializados somente leitura) e .bss (dados não inicializados), enquanto o código executável nativo é colocado em .text. Nosso objetivo era empacotar o código de builtins na seção .text junto com código nativo.
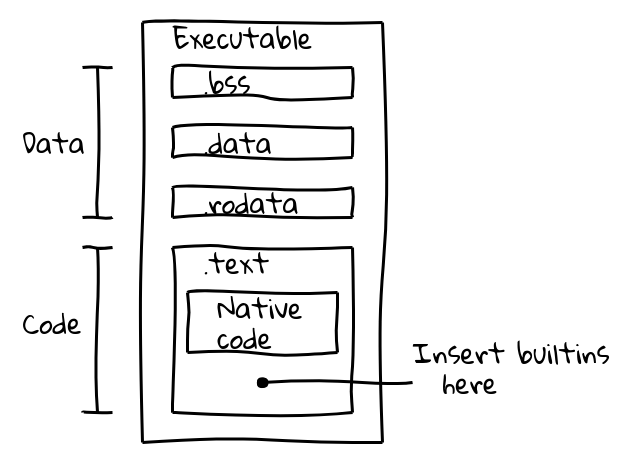
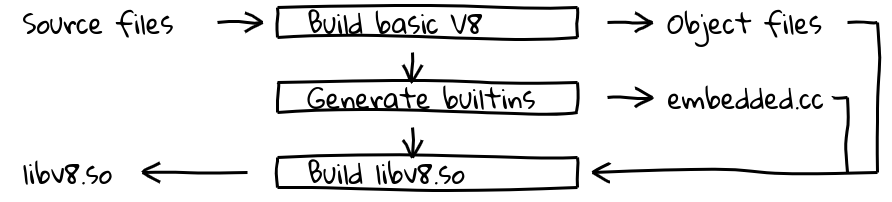
Isso foi feito introduzindo uma nova etapa de construção que utilizava o pipeline de compilador interno do V8 para gerar código nativo para todos os builtins e produzir seus conteúdos em embedded.cc. Este arquivo é então compilado no binário final do V8.
O próprio arquivo embedded.cc contém tanto metadados quanto código de máquina gerado de builtins como uma série de diretivas .byte que instruem o compilador C++ (neste caso, clang ou gcc) a colocar a sequência de bytes especificada diretamente no arquivo de objeto de saída (e posteriormente no executável).
// Informações sobre builtins incorporados são incluídas em
// uma tabela de metadados.
V8_EMBEDDED_TEXT_HEADER(v8_Default_embedded_blob_)
__asm__(".byte 0x65,0x6d,0xcd,0x37,0xa8,0x1b,0x25,0x7e\n"
[metadados truncados]
// Seguido pelo código de máquina gerado.
__asm__(V8_ASM_LABEL("Builtins_RecordWrite"));
__asm__(".byte 0x55,0x48,0x89,0xe5,0x6a,0x18,0x48,0x83\n"
[código de builtins truncado]
Os conteúdos da seção .text são mapeados na memória executável somente leitura em tempo de execução, e o sistema operacional compartilhará memória entre processos enquanto contiver apenas código independente de posição sem símbolos relocáveis. Era exatamente isso que queríamos.
Mas os objetos Code do V8 consistem não apenas no fluxo de instruções, mas também possuem vários pedaços de metadados (às vezes dependentes do isolamento). Objetos Code comuns combinam tanto metadados quanto o fluxo de instruções em um objeto Code de tamanho variável que está localizado no heap gerenciado.
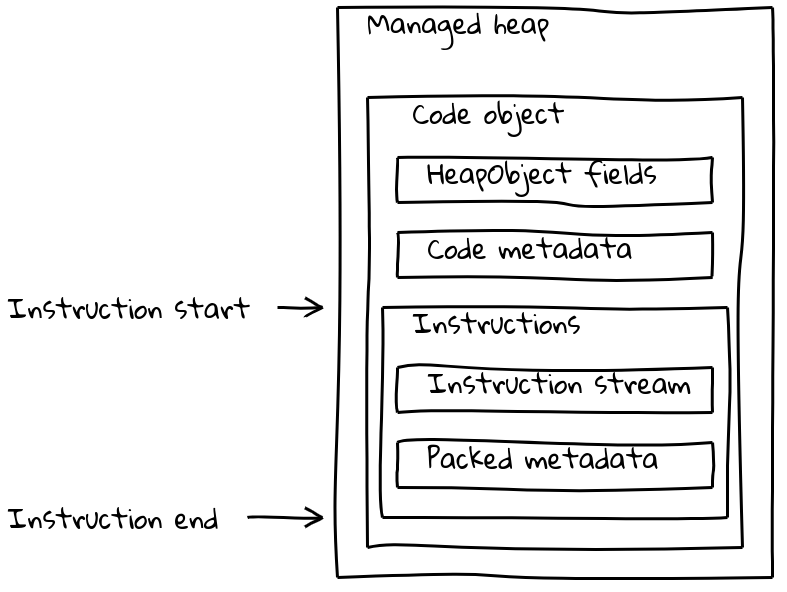
Como vimos, os builtins incorporados têm seu fluxo de instruções nativo localizado fora do heap gerenciado, integrado na seção .text. Para preservar seus metadados, cada builtin incorporado também tem um pequeno objeto Code associado no heap gerenciado, chamado de trampolim fora do heap. Os metadados são armazenados no trampolim, assim como acontece com os objetos Code padrão, enquanto o fluxo de instruções embutido contém, simplesmente, uma pequena sequência que carrega o endereço das instruções incorporadas e salta para ele.
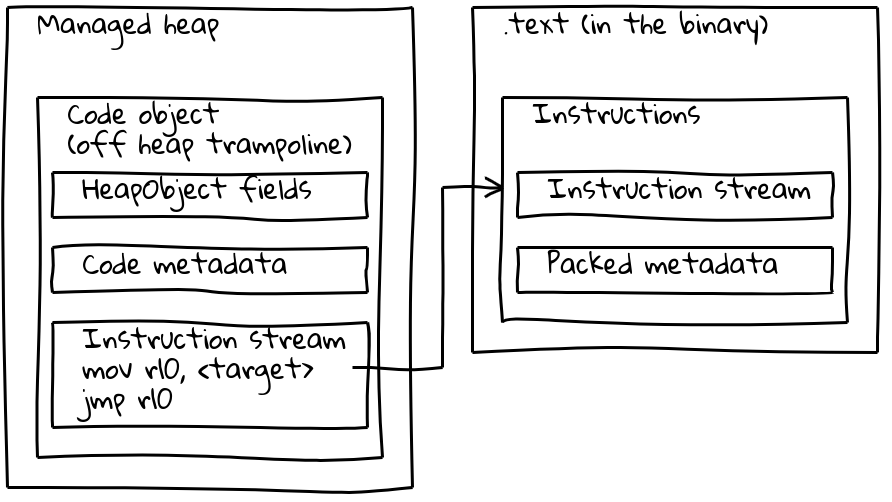
O trampolim permite que o V8 manipule todos os objetos Code de maneira uniforme. Para a maioria dos propósitos, é irrelevante se o objeto Code dado se refere a código padrão no heap gerenciado ou a um builtin incorporado.
Otimizando para desempenho
Com a solução descrita nas seções anteriores, os builtins incorporados estavam essencialmente prontos, mas benchmarks mostraram que eles vinham com desacelerações significativas. Por exemplo, nossa solução inicial regrediu o Speedometer 2.0 em mais de 5% no total.
Começamos a buscar oportunidades de otimização e identificamos as principais fontes de desaceleração. O código gerado era mais lento devido a desvios frequentes realizados para acessar objetos dependentes do isolamento e do processo. Constantes principais eram carregadas da lista raiz (1 desvio), outras constantes do heap do pool de constantes dos builtins globais (2 desvios), e referências externas ainda precisavam ser desempacotadas de dentro de um objeto do heap (3 desvios). O pior culpado era nossa nova sequência de chamadas, que precisava carregar o objeto Code do trampolim, chamá-lo, apenas para então saltar para o endereço de destino. Finalmente, parece que as chamadas entre o heap gerenciado e o código incorporado binário eram intrinsecamente mais lentas, possivelmente devido à longa distância de salto interferindo na predição de ramificações da CPU.
Nosso trabalho se concentrou, portanto, em 1. reduzir os desvios e 2. melhorar a sequência de chamadas dos builtins. Para abordar o primeiro ponto, alteramos o layout do objeto Isolate para transformar a maioria dos carregamentos de objetos em apenas um carregamento relativo à raiz. O pool de constantes dos builtins globais ainda existe, mas contém apenas objetos acessados com pouca frequência.
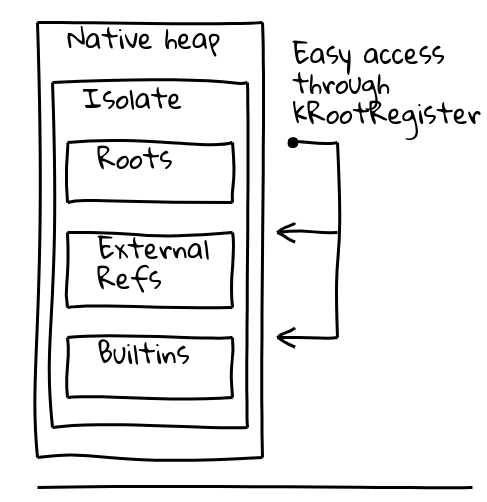
As sequências de chamadas foram significativamente melhoradas em duas frentes. Chamadas builtin-para-builtin foram convertidas para uma única instrução de chamada relativa ao pc. Isso não era possível para código JIT gerado em tempo de execução, uma vez que o deslocamento relativo ao pc poderia exceder o valor máximo de 32 bits. Nesse caso, integramos o trampolim fora do heap em todos os locais de chamada, reduzindo a sequência de chamadas de 6 para apenas 2 instruções.
Com essas otimizações, conseguimos limitar as regressões no Speedometer 2.0 para aproximadamente 0,5%.
Resultados
Avaliamos o impacto dos builtins incorporados no x64 em mais de 10 mil dos sites mais populares e comparamos com a desserialização preguiçosa e ansiosa (descritas acima).
Enquanto anteriormente o Chrome era enviado com um snapshot mapeado na memória que desserializávamos em cada Isolate, agora o snapshot é substituído por builtins incorporados que ainda estão mapeados na memória, mas não precisam ser desserializados. O custo para builtins costumava ser c*(1 + n) onde n é o número de Isolates e c o custo de memória de todos os builtins, enquanto agora é apenas c * 1 (na prática, uma pequena quantidade de overhead por Isolate também permanece para trampolins fora do heap).
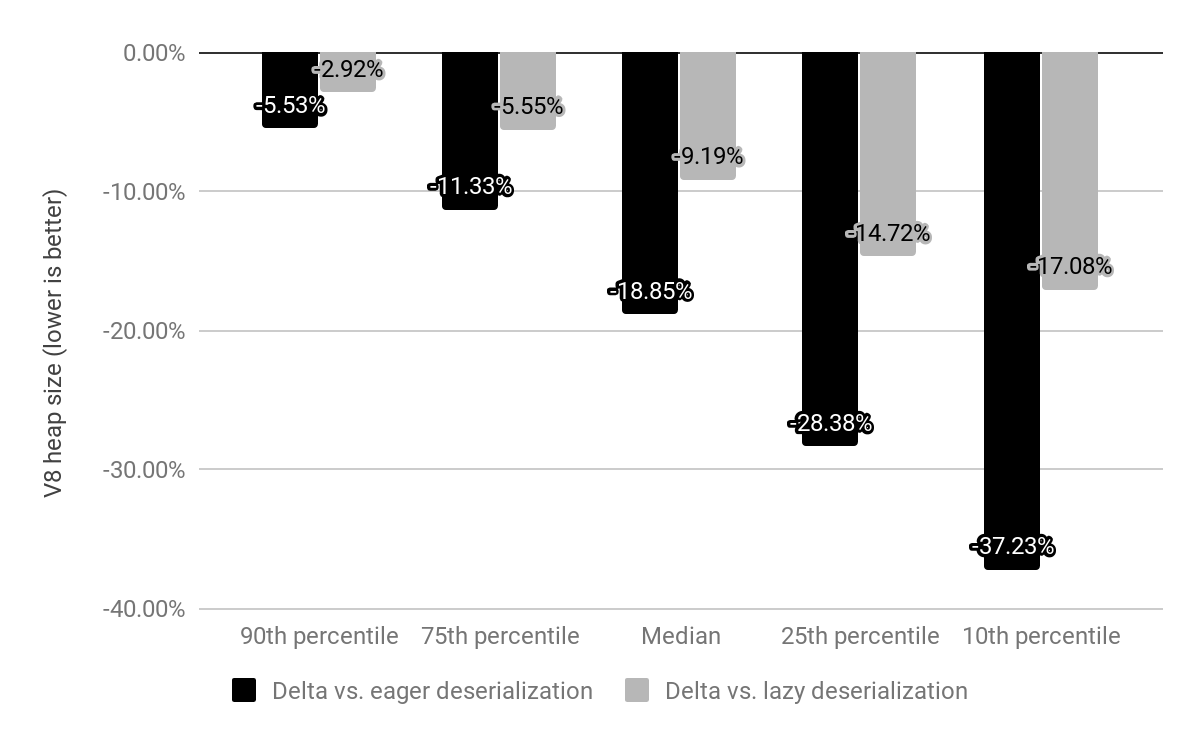
Comparado com a desserialização ansiosa, reduzimos o tamanho mediano do heap do V8 em 19%. O tamanho do processo de renderização do Chrome por site diminuiu 4%. Em números absolutos, o percentil 50 economiza 1,9 MB, o percentil 30 economiza 3,4 MB e o percentil 10 economiza 6,5 MB por site.
Economias significativas adicionais de memória são esperadas uma vez que os manipuladores de bytecode também sejam incorporados binariamente.
Os builtins incorporados estão sendo lançados no x64 no Chrome 69, e plataformas móveis seguirão no Chrome 70. Espera-se que o suporte para ia32 seja lançado no final de 2018.
Nota: Todos os diagramas foram gerados usando a incrível ferramenta Shaky Diagramming de Vyacheslav Egorov.