Decolagem: um novo compilador baseline para WebAssembly no V8
V8 v6.9 inclui Decolagem, um novo compilador baseline para WebAssembly. Decolagem agora está habilitado por padrão em sistemas desktop. Este artigo detalha a motivação para adicionar outro nível de compilação e descreve a implementação e performance de Decolagem.

Desde que WebAssembly foi lançado há mais de um ano, sua adoção na web tem aumentado constantemente. Grandes aplicações direcionadas ao WebAssembly começaram a aparecer. Por exemplo, o benchmark ZenGarden da Epic inclui um binário de WebAssembly de 39,5 MB, e a AutoDesk é entregue como um binário de 36,8 MB. Como o tempo de compilação é essencialmente linear em relação ao tamanho do binário, essas aplicações demoram um tempo considerável para serem iniciadas. Em muitas máquinas, esse tempo ultrapassa 30 segundos, o que não proporciona uma experiência ideal para o usuário.
Mas por que demora tanto para iniciar um aplicativo WebAssembly, se aplicativos similares em JS iniciam muito mais rápido? A razão é que o WebAssembly promete entregar performance previsível, então, uma vez que o app está em execução, você pode ter certeza de que os objetivos de performance serão consistentemente atingidos (por exemplo, renderizando 60 quadros por segundo, sem lag ou artefatos de áudio...). Para alcançar isso, o código WebAssembly é compilado antecipadamente no V8, para evitar qualquer pausa de compilação introduzida por um compilador just-in-time que poderia resultar em engasgos visíveis no aplicativo.
O pipeline de compilação existente (TurboFan)
A abordagem do V8 para compilar WebAssembly tem se baseado no TurboFan, o compilador otimizador que projetamos para JavaScript e asm.js. TurboFan é um compilador poderoso com uma representação intermediária (IR) baseada em gráfico, adequada para otimizações avançadas como redução de força, inlining, movimento de código, combinação de instruções e alocação sofisticada de registradores. O design do TurboFan suporta entrar no pipeline muito tarde, mais próximo do código de máquina, o que ignora muitas etapas necessárias para suportar a compilação de JavaScript. Por design, transformar código WebAssembly em IR do TurboFan (incluindo construção SSA) em uma única passagem simples é muito eficiente, parcialmente devido ao fluxo de controle estruturado do WebAssembly. No entanto, o backend do processo de compilação ainda consome tempo e memória consideráveis.
O novo pipeline de compilação (Decolagem)
O objetivo do Decolagem é reduzir o tempo de inicialização para aplicativos baseados em WebAssembly, gerando código o mais rápido possível. A qualidade do código é secundária, já que o código quente é eventualmente recompilado com TurboFan de qualquer maneira. Decolagem evita o tempo e a memória gastos para construir um IR e gera código de máquina em uma única passagem sobre o bytecode de uma função WebAssembly.

A partir do diagrama acima, é óbvio que Decolagem deve ser capaz de gerar código muito mais rápido do que TurboFan, uma vez que o pipeline consiste apenas de duas etapas. De fato, o decodificador de corpo de função faz uma única passagem sobre os bytes brutos do WebAssembly e interage com a etapa subsequente por meio de callbacks, então a geração de código é realizada enquanto decodifica e valida o corpo da função. Junto com as APIs de streaming do WebAssembly, isso permite que V8 compile código WebAssembly para código de máquina enquanto o download é feito pela rede.
Geração de código no Decolagem
Liftoff é um gerador de código simples e rápido. Ele realiza apenas uma passagem pelos opcodes de uma função, gerando código para cada opcode, um de cada vez. Para opcodes simples, como operações aritméticas, isso geralmente resulta em uma única instrução de máquina, mas pode ser mais complexo para outros, como chamadas. Liftoff mantém metadados sobre a pilha de operandos para saber onde os inputs de cada operação estão atualmente armazenados. Essa pilha virtual existe apenas durante a compilação. O fluxo de controle estruturado e as regras de validação do WebAssembly garantem que a localização desses inputs possa ser determinada estaticamente. Assim, uma pilha em tempo de execução real, onde os operandos são empurrados e retirados, não é necessária. Durante a execução, cada valor na pilha virtual será mantido em um registrador ou será gravado na pilha física da função. Para constantes inteiras pequenas (geradas por i32.const), Liftoff apenas registra o valor da constante na pilha virtual e não gera nenhum código. Somente quando a constante é usada por uma operação subsequente, ela é emitida ou combinada com a operação, por exemplo, emitindo diretamente uma instrução addl <reg>, <const> em x64. Isso evita carregar essa constante em um registrador, resultando em um código melhor.
Vamos analisar uma função muito simples para ver como o Liftoff gera código para ela.

Essa função de exemplo recebe dois parâmetros e retorna a soma deles. Quando Liftoff decodifica os bytes dessa função, ele começa inicializando seu estado interno para as variáveis locais de acordo com a convenção de chamada para funções WebAssembly. Para x64, a convenção de chamada do V8 passa os dois parâmetros nos registradores rax e rdx.
Para as instruções get_local, Liftoff não gera nenhum código, mas apenas atualiza seu estado interno para refletir que esses valores de registradores agora estão empilhados na pilha virtual. A instrução i32.add então retira os dois registradores e escolhe um registrador para o valor do resultado. Não podemos usar nenhum dos registradores de entrada para o resultado, já que ambos ainda aparecem na pilha como variáveis locais. Substituí-los mudaria o valor retornado por uma instrução get_local posterior. Assim, Liftoff escolhe um registrador livre, neste caso rcx, e produz a soma de rax e rdx nesse registrador. rcx é então empilhado na pilha virtual.
Após a instrução i32.add, o corpo da função está concluído, então o Liftoff deve montar o retorno da função. Como nossa função de exemplo tem um valor de retorno, a validação requer que haja exatamente um valor na pilha virtual no final do corpo da função. Assim, Liftoff gera um código que move o valor de retorno mantido em rcx para o registrador de retorno adequado rax e, em seguida, retorna da função.
Por motivo de simplicidade, o exemplo acima não contém blocos (if, loop ...) ou ramificações. Blocos no WebAssembly introduzem fusões de controle, já que o código pode ramificar para qualquer bloco pai, e blocos if podem ser ignorados. Esses pontos de fusão podem ser alcançados a partir de diferentes estados da pilha. No entanto, o código seguinte deve assumir um estado específico da pilha para gerar código. Assim, Liftoff salva um instantâneo do estado atual da pilha virtual como o estado que será assumido para o código após o novo bloco (ou seja, ao retornar ao nível de controle onde estamos atualmente). O novo bloco continuará com o estado ativo atual, potencialmente mudando onde os valores da pilha ou locais são armazenados: alguns podem ser gravados na pilha ou mantidos em outros registradores. Ao ramificar para outro bloco ou terminar um bloco (o que é o mesmo que ramificar para o bloco pai), o Liftoff deve gerar código que adapta o estado atual ao estado esperado nesse ponto, de forma que o código emitido para o destino para o qual ramificamos encontre os valores corretos onde espera. A validação garante que a altura da pilha virtual atual corresponda à altura do estado esperado, então Liftoff só precisa gerar código para reorganizar valores entre registradores e/ou a moldura da pilha física, conforme mostrado abaixo.
Vamos dar uma olhada em um exemplo disso.

O exemplo acima assume uma pilha virtual com dois valores na pilha de operandos. Antes de iniciar o novo bloco, o valor do topo da pilha virtual é retirado como argumento para a instrução if. O valor restante da pilha precisa ser colocado em outro registrador, já que atualmente ele está ofuscando o primeiro parâmetro, mas ao ramificar de volta para esse estado, podemos precisar manter dois valores diferentes para o valor da pilha e o parâmetro. Neste caso, Liftoff opta por desduplicá-lo no registrador rcx. Este estado é então salvo em um instantâneo e o estado ativo é modificado dentro do bloco. No final do bloco, ramificamos implicitamente de volta para o bloco pai, então mesclamos o estado atual no instantâneo movendo o registrador rbx para rcx e recarregando o registrador rdx da moldura da pilha.
Escalando do Liftoff para o TurboFan
Com Liftoff e TurboFan, o V8 agora tem dois níveis de compilação para WebAssembly: Liftoff como compilador inicial para inicialização rápida e TurboFan como compilador otimizador para desempenho máximo. Isso levanta a questão de como combinar os dois compiladores para oferecer a melhor experiência geral ao usuário.
Para JavaScript, o V8 usa o interpretador Ignition e o compilador TurboFan e aplica uma estratégia dinâmica de subida de nível. Cada função é executada primeiro no Ignition, e se a função se tornar quente, o TurboFan a compila em código de máquina altamente otimizado. Uma abordagem semelhante também poderia ser usada para Liftoff, mas os trade-offs aqui são um pouco diferentes:
- WebAssembly não requer feedback de tipo para gerar código rápido. Enquanto JavaScript se beneficia muito em coletar feedback de tipo, WebAssembly é estaticamente tipado, de modo que o mecanismo pode gerar código otimizado imediatamente.
- O código WebAssembly deve executar com desempenho previsível, sem uma fase de aquecimento prolongada. Um dos motivos pelos quais as aplicações utilizam WebAssembly é para executar na web com desempenho elevado e previsível. Assim, não podemos tolerar a execução de código subótimo por muito tempo, nem aceitar pausas para compilação durante a execução.
- Um objetivo importante do design do interpretador Ignition para JavaScript é reduzir o uso de memória ao não compilar funções. No entanto, descobrimos que um interpretador para WebAssembly é muito lento para cumprir o objetivo de desempenho previsível e rápido. Na verdade, construímos tal interpretador, mas sendo 20 vezes ou mais lento do que o código compilado, ele só é útil para depuração, independentemente de quanto memória economiza. Dado isso, o motor deve armazenar o código compilado de qualquer forma; no final, ele deve armazenar apenas o código mais compacto e eficiente, que é o código otimizado do TurboFan.
Com base nessas restrições, concluímos que a subida dinâmica de tier não é a escolha certa para a implementação do WebAssembly no V8 neste momento, pois aumentaria o tamanho do código e reduziria o desempenho por um período indeterminado. Em vez disso, optamos por uma estratégia de subida antecipada de tier. Imediatamente após a compilação de um módulo pelo Liftoff ser concluída, o motor WebAssembly inicia threads em segundo plano para gerar código otimizado para o módulo. Isso permite que o V8 comece a executar o código rapidamente (após a conclusão do Liftoff), mas ainda tenha o código TurboFan mais eficiente disponível o mais cedo possível.
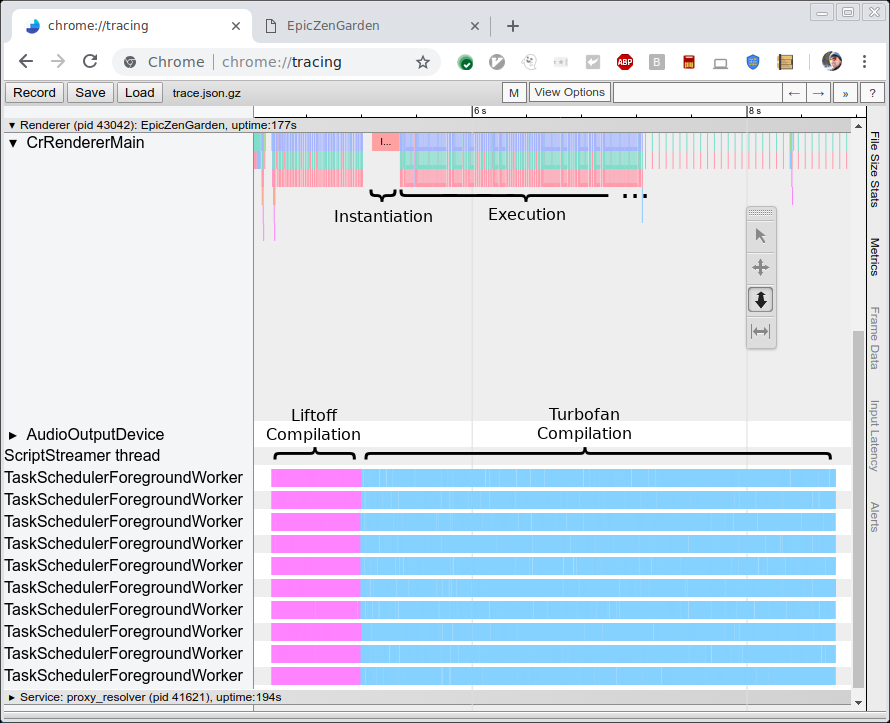
A imagem abaixo mostra o rastreamento da compilação e execução do benchmark EpicZenGarden. Ela mostra que logo após a compilação pelo Liftoff podemos instanciar o módulo WebAssembly e começar a executá-lo. A compilação TurboFan ainda leva vários segundos, então durante este período de subida de tier o desempenho observado gradualmente aumenta, à medida que funções individuais do TurboFan são usadas assim que estão concluídas.
Desempenho
Dois métricas são interessantes para avaliar o desempenho do novo compilador Liftoff. Primeiro, queremos comparar a velocidade de compilação (ou seja, o tempo para gerar o código) com o TurboFan. Segundo, queremos medir o desempenho do código gerado (ou seja, a velocidade de execução). A primeira métrica é a mais interessante aqui, já que o objetivo do Liftoff é reduzir o tempo de inicialização ao gerar código o mais rapidamente possível. Por outro lado, o desempenho do código gerado ainda deve ser muito bom, já que esse código pode ainda ser executado por vários segundos ou até minutos em hardware menos potente.
Desempenho na geração de código
Para medir o desempenho do compilador em si, executamos vários benchmarks e medimos o tempo bruto de compilação usando rastreamento (veja a imagem acima). Executamos os benchmarks em uma máquina HP Z840 (2 x Intel Xeon E5-2690 @2.6GHz, 24 núcleos, 48 threads) e em um MacBook Pro (Intel Core i7-4980HQ @2.8GHz, 4 núcleos, 8 threads). Note que o Chrome atualmente não usa mais de 10 threads em segundo plano, então a maioria dos núcleos da máquina Z840 ficam inutilizados.
Executamos três benchmarks:
- EpicZenGarden: A demo ZenGarden executando na estrutura Epic.
- Tanks!: Uma demo do motor Unity.
- AutoDesk
- PSPDFKit
Para cada benchmark, medimos o tempo bruto de compilação usando o rastreamento mostrado acima. Esse número é mais estável do que qualquer tempo relatado pelo benchmark em si, já que não depende de uma tarefa ser agendada na thread principal e não inclui trabalho não relacionado como criar a instância real do WebAssembly.
Os gráficos abaixo mostram os resultados desses benchmarks. Cada benchmark foi executado três vezes, e relatamos o tempo médio de compilação.


Como esperado, o compilador Liftoff gera código muito mais rápido tanto na estação de trabalho de mesa de alto desempenho quanto no MacBook. O avanço de velocidade do Liftoff sobre o TurboFan é ainda maior no hardware menos capaz do MacBook.
Desempenho do código gerado
Embora o desempenho do código gerado seja um objetivo secundário, queremos preservar a experiência do usuário com alto desempenho na fase de inicialização, já que o código Liftoff pode ser executado por vários segundos antes que o código TurboFan seja concluído.
Para medir o desempenho do código Liftoff, desativamos a subida de tier para medir apenas a execução pura do Liftoff. Neste cenário, executamos dois benchmarks:
-
Benchmarks headless do Unity
Estes são diversos benchmarks executando na estrutura Unity. Eles são headless, portanto podem ser executados diretamente no shell d8. Cada benchmark reporta um score, que não é necessariamente proporcional ao desempenho de execução, mas suficiente para comparar o desempenho.
-
Este benchmark relata o tempo necessário para realizar diferentes ações em um documento PDF e o tempo necessário para instanciar o módulo WebAssembly (incluindo a compilação).
Tal como antes, executamos cada benchmark três vezes e utilizamos a média das três execuções. Como a escala dos números registrados difere significativamente entre os benchmarks, relatamos o desempenho relativo do Liftoff em comparação com o TurboFan. Um valor de +30% significa que o código do Liftoff é 30% mais lento do que o TurboFan. Números negativos indicam que o Liftoff é mais rápido. Aqui estão os resultados:

No Unity, o código do Liftoff executa em média cerca de 50% mais lento do que o código do TurboFan na máquina desktop e 70% mais lento no MacBook. Curiosamente, há um caso (Script Mandelbrot) onde o código do Liftoff supera o código do TurboFan. Provavelmente este é um caso excepcional onde, por exemplo, o alocador de registro do TurboFan está funcionando de forma inadequada em um loop intenso. Estamos investigando para ver se o TurboFan pode ser melhorado para lidar melhor com este caso.

No benchmark do PSPDFKit, o código do Liftoff executa 18-54% mais lento do que o código otimizado, enquanto a inicialização melhora significativamente, como esperado. Esses números mostram que para código do mundo real que também interage com o navegador por meio de chamadas JavaScript, a perda de desempenho do código não otimizado é geralmente menor do que em benchmarks mais intensivos em computação.
E novamente, vale notar que para esses números desligamos completamente o escalonamento de nível, então apenas o código do Liftoff foi executado. Em configurações de produção, o código do Liftoff será gradualmente substituído pelo código do TurboFan, de modo que o desempenho mais baixo do código do Liftoff dure somente por um curto período de tempo.
Trabalho Futuro
Após o lançamento inicial do Liftoff, estamos trabalhando para melhorar ainda mais o tempo de inicialização, reduzir o uso de memória e levar os benefícios do Liftoff para mais usuários. Em particular, estamos trabalhando na melhoria das seguintes coisas:
- Portar o Liftoff para arm e arm64 para também usá-lo em dispositivos móveis. Atualmente, o Liftoff é implementado apenas para plataformas Intel (32 e 64 bits), que captam principalmente os casos de uso em desktops. Para alcançar usuários móveis, iremos portar o Liftoff para mais arquiteturas.
- Implementar o escalonamento dinâmico de nível para dispositivos móveis. Como dispositivos móveis tendem a ter muito menos memória disponível do que sistemas de desktop, precisamos adaptar nossa estratégia de escalonamento para esses dispositivos. A simples recompilação de todas as funções com o TurboFan dobra facilmente a memória necessária para carregar todo o código, pelo menos temporariamente (até que o código do Liftoff seja descartado). Em vez disso, estamos experimentando uma combinação de compilação preguiçosa com Liftoff e escalonamento dinâmico de funções intensivas no TurboFan.
- Melhorar o desempenho da geração de código do Liftoff. A primeira iteração de uma implementação raramente é a melhor. Há várias coisas que podem ser ajustadas para acelerar ainda mais a velocidade de compilação do Liftoff. Isso ocorrerá gradualmente nas próximas versões.
- Melhorar o desempenho do código do Liftoff. Além do próprio compilador, o tamanho e a velocidade do código gerado também podem ser melhorados. Isso também acontecerá gradualmente nas próximas versões.
Conclusão
O V8 agora contém o Liftoff, um novo compilador de base para WebAssembly. O Liftoff reduz drasticamente o tempo de inicialização de aplicativos WebAssembly com um gerador de código simples e rápido. Em sistemas desktop, o V8 ainda alcança desempenho máximo recompilando todo o código em segundo plano usando o TurboFan. O Liftoff está ativado por padrão no V8 v6.9 (Chrome 69), e pode ser controlado explicitamente pelos flags --liftoff/--no-liftoff e chrome://flags/#enable-webassembly-baseline, respectivamente.