Rápido `for`-`in` no V8
for-in é um recurso de linguagem amplamente utilizado presente em muitos frameworks. Apesar de sua ubiquidade, é um dos recursos de linguagem mais obscuros do ponto de vista de implementação. O V8 fez grandes esforços para tornar esse recurso o mais rápido possível. Ao longo do último ano, o for-in tornou-se totalmente compatível com a especificação e até 3 vezes mais rápido, dependendo do contexto.
Muitos sites populares dependem fortemente do for-in e se beneficiam de sua otimização. Por exemplo, no início de 2016, o Facebook gastou aproximadamente 7% do tempo total de JavaScript na inicialização na implementação do próprio for-in. Na Wikipedia esse número era ainda maior, em torno de 8%. Ao melhorar o desempenho de certos casos lentos, o Chrome 51 melhorou significativamente o desempenho desses dois sites:


Wikipedia e Facebook melhoraram seu tempo total de script em 4% devido às várias melhorias no for-in. Observe que, durante o mesmo período, o restante do V8 também ficou mais rápido, o que resultou em uma melhoria total de scripting de mais de 4%.
No restante deste post de blog, explicaremos como conseguimos acelerar esse recurso central de linguagem e corrigir uma violação antiga da especificação ao mesmo tempo.
A especificação
TL;DR; A semântica de iteração do for-in é imprecisa por razões de desempenho.
Quando olhamos para o texto da especificação de for-in, ele está escrito de uma maneira inesperadamente imprecisa, o que é observável em implementações diferentes. Vamos observar um exemplo ao iterar sobre um objeto Proxy com os traps adequados configurados.
const proxy = new Proxy({ a: 1, b: 1},
{
getPrototypeOf(target) {
console.log('getPrototypeOf');
return null;
},
ownKeys(target) {
console.log('ownKeys');
return Reflect.ownKeys(target);
},
getOwnPropertyDescriptor(target, prop) {
console.log('getOwnPropertyDescriptor name=' + prop);
return Reflect.getOwnPropertyDescriptor(target, prop);
}
});
No V8/Chrome 56 você obtém a seguinte saída:
ownKeys
getPrototypeOf
getOwnPropertyDescriptor name=a
a
getOwnPropertyDescriptor name=b
b
Por outro lado, você obtém uma ordem diferente de declarações para o mesmo trecho de código no Firefox 51:
ownKeys
getOwnPropertyDescriptor name=a
getOwnPropertyDescriptor name=b
getPrototypeOf
a
b
Ambos os navegadores respeitam a especificação, mas pela primeira vez a especificação não impõe uma ordem explícita de instruções. Para entender essas lacunas adequadamente, vamos dar uma olhada no texto da especificação:
EnumerateObjectProperties ( O ) Quando a operação abstrata EnumerateObjectProperties é chamada com o argumento O, os seguintes passos são seguidos:
- Afirme: Type(O) é Object.
- Retorne um objeto Iterador (25.1.1.2) cujo método next itera sobre todas as chaves de propriedades String-valued enumeráveis de O. O objeto iterador nunca é diretamente acessível ao código ECMAScript. A mecânica e ordem de enumeração das propriedades não são especificadas, mas devem estar conformes às regras especificadas abaixo.
Agora, normalmente instruções de especificação são precisas em quais passos exatos são necessários. Mas neste caso referem-se a uma simples lista descrita em texto, e mesmo a ordem de execução é deixada para os implementadores. Tipicamente, a razão para isso é que essas partes da especificação foram escritas após o fato onde motores JavaScript já tinham implementações diferentes. A especificação tenta amarrar pontas soltas fornecendo as seguintes instruções:
- Os métodos throw e return do iterador são nulos e nunca são invocados.
- O método next do iterador processa propriedades do objeto para determinar se a chave da propriedade deve ser retornada como um valor do iterador.
- Chaves de propriedades retornadas não incluem chaves que são Símbolos.
- Propriedades do objeto alvo podem ser excluídas durante a enumeração.
- Uma propriedade que é excluída antes de ser processada pelo método next do iterador é ignorada. Se novas propriedades forem adicionadas ao objeto alvo durante a enumeração, as propriedades recém-adicionadas não têm garantia de serem processadas na enumeração ativa.
- Um nome de propriedade será retornado pelo método next do iterador, no máximo, uma vez em qualquer enumeração.
- Enumerar as propriedades do objeto alvo inclui enumerar propriedades de seu protótipo, e o protótipo do protótipo, e assim por diante, recursivamente; mas uma propriedade de um protótipo não é processada se tiver o mesmo nome de uma propriedade que já foi processada pelo método next do iterador.
- Os valores dos atributos
[[Enumerable]]não são considerados ao determinar se uma propriedade de um objeto protótipo já foi processada. - Os nomes das propriedades enumeráveis de objetos protótipo devem ser obtidos invocando
EnumerateObjectProperties, passando o objeto protótipo como argumento. EnumerateObjectPropertiesdeve obter as chaves das propriedades próprias do objeto alvo chamando seu método interno[[OwnPropertyKeys]].
Esses passos parecem tediosos, no entanto, a especificação também contém um exemplo de implementação que é explícito e muito mais legível:
function* EnumerateObjectProperties(obj) {
const visited = new Set();
for (const key of Reflect.ownKeys(obj)) {
if (typeof key === 'symbol') continue;
const desc = Reflect.getOwnPropertyDescriptor(obj, key);
if (desc && !visited.has(key)) {
visited.add(key);
if (desc.enumerável) yield key;
}
}
const proto = Reflect.getPrototypeOf(obj);
if (proto === null) return;
for (const protoKey of EnumerateObjectProperties(proto)) {
if (!visited.has(protoKey)) yield protoKey;
}
}
Agora que você chegou até aqui, pode ter notado pelo exemplo anterior que o V8 não segue exatamente a implementação de exemplo da especificação. Para começar, o gerador de for-in do exemplo funciona de forma incremental, enquanto o V8 coleta todas as chaves de uma vez - principalmente por motivos de desempenho. Isso é perfeitamente válido, e de fato o texto da especificação afirma explicitamente que a ordem das operações de A - J não está definida. No entanto, como você descobrirá mais tarde neste artigo, existem alguns casos específicos em que o V8 não respeitou totalmente a especificação até 2016.
O cache de enumeração
A implementação exemplo do gerador for-in segue um padrão incremental de coleta e fornecimento de chaves. No V8, as chaves das propriedades são coletadas em uma primeira etapa e só então utilizadas na fase de iteração. Para o V8, isso facilita algumas coisas. Para entender o motivo, precisamos dar uma olhada no modelo de objeto.
Um objeto simples como {a:'value a', b:'value b', c:'value c'} pode ter várias representações internas no V8, como mostraremos em uma postagem detalhada posterior sobre propriedades. Isso significa que, dependendo do tipo de propriedades que temos — no objeto, rápidas ou lentas — os nomes das propriedades reais são armazenados em lugares diferentes. Isso torna a coleta de chaves enumeráveis uma tarefa não trivial.
O V8 acompanha a estrutura do objeto por meio de uma classe oculta ou chamada de Map. Objetos com o mesmo Map têm a mesma estrutura. Além disso, cada Map possui uma estrutura de dados compartilhada, o array de descritores, que contém detalhes sobre cada propriedade, como onde as propriedades estão armazenadas no objeto, o nome da propriedade e detalhes como a possibilidade de enumeração.
Vamos assumir por um momento que nosso objeto JavaScript alcançou sua forma final e nenhuma propriedade será adicionada ou removida. Nesse caso, poderíamos usar o array de descritores como fonte para as chaves. Isso funciona se houver apenas propriedades enumeráveis. Para evitar o trabalho adicional de filtrar as propriedades não enumeráveis a cada vez, o V8 usa um EnumCache separado acessível por meio do array de descritores do Map.

Dado que o V8 espera que objetos lentos com dicionários mudem frequentemente (ou seja, por meio de adição e remoção de propriedades), não existe array de descritores para objetos lentos com propriedades de dicionário. Assim, o V8 não fornece um EnumCache para propriedades lentas. Suposições semelhantes são feitas para propriedades indexadas, e por isso elas também são excluídas do EnumCache.
Vamos resumir os fatos importantes:
Mapssão usados para acompanhar formas de objetos.- Arrays de descritores armazenam informações sobre propriedades (nome, configurabilidade, visibilidade).
- Arrays de descritores podem ser compartilhados entre
Maps. - Cada array de descritores pode ter um
EnumCachelistando apenas as chaves nomeadas enumeráveis, não os nomes de propriedades indexados.
A mecânica do for-in
Agora você já conhece parcialmente como funcionam os Maps e como o EnumCache se relaciona ao array de descritores. O V8 executa JavaScript por meio do Ignition, um interpretador de bytecode, e do TurboFan, o compilador otimizador, que lidam com o for-in de maneira semelhante. Para simplificar, usaremos um estilo pseudo-C++ para explicar como o for-in é implementado internamente:
// Preparação para For-In:
FixedArray* keys = nullptr;
Map* original_map = object->map();
if (original_map->HasEnumCache()) {
if (object->HasNoElements()) {
keys = original_map->GetCachedEnumKeys();
} else {
keys = object->GetCachedEnumKeysWithElements();
}
} else {
keys = object->GetEnumKeys();
}
// Corpo do For-In:
for (size_t i = 0; i < keys->length(); i++) {
// Próximo For-In:
String* key = keys[i];
if (!object->HasProperty(key) continue;
EVALUATE_FOR_IN_BODY();
}
O for-in pode ser separado em três etapas principais:
- Preparar as chaves para iterar,
- Obter a próxima chave,
- Avaliar o corpo do
for-in.
A etapa "prepare" é a mais complexa dessas três, e é aqui que o EnumCache entra em jogo. No exemplo acima, você pode ver que o V8 usa diretamente o EnumCache se ele existir e se não houver elementos (propriedades indexadas por inteiro) no objeto (e em seu protótipo). No caso de haver nomes de propriedades indexadas, o V8 salta para uma função de runtime implementada em C++, que os adiciona ao cache de enumeração existente, conforme ilustrado no exemplo a seguir:
FixedArray* JSObject::GetCachedEnumKeysWithElements() {
FixedArray* keys = object->map()->GetCachedEnumKeys();
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* Map::GetCachedEnumKeys() {
// Obter as chaves de propriedades enumeráveis de um cache de enumeração possivelmente compartilhado
FixedArray* keys_cache = descriptors()->enum_cache()->keys_cache();
if (enum_length() == keys_cache->length()) return keys_cache;
return keys_cache->CopyUpTo(enum_length());
}
FixedArray* FastElementsAccessor::PrependElementIndices(
JSObject* object, FixedArray* property_keys) {
Assert(object->HasFastElements());
FixedArray* elements = object->elements();
int nof_indices = CountElements(elements)
FixedArray* result = FixedArray::Allocate(property_keys->length() + nof_indices);
int insertion_index = 0;
for (int i = 0; i < elements->length(); i++) {
if (!HasElement(elements, i)) continue;
result[insertion_index++] = String::FromInt(i);
}
// Inserir chaves de propriedades no final.
property_keys->CopyTo(result, nof_indices - 1);
return result;
}
No caso de nenhum EnumCache existente ser encontrado, saltamos novamente para C++ e seguimos os passos da especificação apresentados inicialmente:
FixedArray* JSObject::GetEnumKeys() {
// Obter as chaves de enumeração do receptor.
FixedArray* keys = this->GetOwnEnumKeys();
// Subir na cadeia de protótipos.
for (JSObject* object : GetPrototypeIterator()) {
// Adicionar chaves não duplicadas à lista.
keys = keys->UnionOfKeys(object->GetOwnEnumKeys());
}
return keys;
}
FixedArray* JSObject::GetOwnEnumKeys() {
FixedArray* keys;
if (this->HasEnumCache()) {
keys = this->map()->GetCachedEnumKeys();
} else {
keys = this->GetEnumPropertyKeys();
}
if (this->HasFastProperties()) this->map()->FillEnumCache(keys);
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* FixedArray::UnionOfKeys(FixedArray* other) {
int length = this->length();
FixedArray* result = FixedArray::Allocate(length + other->length());
this->CopyTo(result, 0);
int insertion_index = length;
for (int i = 0; i < other->length(); i++) {
String* key = other->get(i);
if (other->IndexOf(key) == -1) {
result->set(insertion_index, key);
insertion_index++;
}
}
result->Shrink(insertion_index);
return result;
}
Este código simplificado em C++ corresponde à implementação no V8 até o início de 2016, quando começamos a examinar o método UnionOfKeys. Se observar com atenção, verá que usamos um algoritmo ingênuo para excluir duplicatas da lista, o que pode resultar em mau desempenho se tivermos muitas chaves na cadeia de protótipos. Foi assim que decidimos buscar as otimizações na seção seguinte.
Problemas com for-in
Como já sugerimos na seção anterior, o método UnionOfKeys tem um desempenho ruim em seu pior caso. Ele foi baseado na suposição válida de que a maioria dos objetos possui propriedades rápidas e, portanto, se beneficiará de um EnumCache. A segunda suposição é que há poucas propriedades enumeráveis na cadeia de protótipos, limitando o tempo gasto em encontrar duplicatas. No entanto, se o objeto tiver propriedades lentas de dicionário e muitas chaves na cadeia de protótipos, UnionOfKeys se torna um gargalo, pois precisamos coletar os nomes das propriedades enumeráveis toda vez que entramos no for-in.
Além de problemas de desempenho, havia outro problema com o algoritmo existente, já que ele não estava em conformidade com a especificação. O V8 interpretava o seguinte exemplo de maneira errada por muitos anos:
var o = {
__proto__ : {b: 3},
a: 1
};
Object.defineProperty(o, 'b', {});
for (var k in o) console.log(k);
Saída:
a
b
Talvez de forma contraintuitiva, isso deveria apenas imprimir a, em vez de a e b. Se você recordar o texto da especificação no início deste post, os passos G e J implicam que propriedades não enumeráveis no receptor ocultam propriedades na cadeia de protótipos.
Para complicar ainda mais, o ES6 introduziu o objeto proxy. Isso quebrou muitas suposições do código do V8. Para implementar for-in de maneira compatível com a especificação, precisamos acionar as 5 das 13 armadilhas de proxy diferentes.
| Método Interno | Método do Handler |
|---|---|
[[GetPrototypeOf]] | getPrototypeOf |
[[GetOwnProperty]] | getOwnPropertyDescriptor |
[[HasProperty]] | has |
[[Get]] | get |
[[OwnPropertyKeys]] | ownKeys |
Isso exigiu uma versão duplicada do código original GetEnumKeys, que tentou seguir a implementação de exemplo da especificação mais de perto. Proxies ES6 e a falta de tratamento de propriedades sombrias foram a principal motivação para nós refatorarmos como extraímos todas as chaves para for-in no início de 2016.
O KeyAccumulator
Introduzimos uma classe auxiliar separada, o KeyAccumulator, que lidava com as complexidades de coletar as chaves para for-in. Com o crescimento da especificação ES6, novos recursos como Object.keys ou Reflect.ownKeys exigiram sua própria versão ligeiramente modificada de coleta de chaves. Ao ter um único local configurável, pudemos melhorar o desempenho de for-in e evitar código duplicado.
O KeyAccumulator consiste em uma parte rápida que suporta apenas um conjunto limitado de ações, mas consegue completá-las de forma muito eficiente. O acumulador lento suporta todos os casos complexos, como Proxies ES6.

Para filtrar adequadamente propriedades sombrias, temos que manter uma lista separada de propriedades não enumeráveis que vimos até agora. Por razões de desempenho, só fazemos isso depois de identificar que há propriedades enumeráveis na cadeia de protótipos de um objeto.
Melhorias de desempenho
Com o KeyAccumulator em funcionamento, alguns padrões adicionais tornaram-se viáveis para otimizar. O primeiro foi evitar o loop aninhado do método original UnionOfKeys, que causava casos lentos extremos. Em um segundo passo, realizamos verificações prévias mais detalhadas para utilizar caches existentes de Enum e evitar etapas de cópia desnecessárias.
Para ilustrar que a implementação em conformidade com a especificação é mais rápida, vamos observar os seguintes quatro objetos diferentes:
var fastProperties = {
__proto__ : null,
'property 1': 1,
…
'property 10': n
};
var fastPropertiesWithPrototype = {
'property 1': 1,
…
'property 10': n
};
var slowProperties = {
__proto__ : null,
'dummy': null,
'property 1': 1,
…
'property 10': n
};
delete slowProperties['dummy']
var elements = {
__proto__: null,
'1': 1,
…
'10': n
}
- O objeto
fastPropertiestem propriedades padrão rápidas. - O objeto
fastPropertiesWithPrototypetem propriedades adicionais não enumeráveis na cadeia de protótipos usando oObject.prototype. - O objeto
slowPropertiestem propriedades de dicionário lentas. - O objeto
elementspossui apenas propriedades indexadas.
O seguinte gráfico compara o desempenho original ao executar um loop for-in um milhão de vezes em um loop apertado sem a ajuda de nosso compilador otimizado.
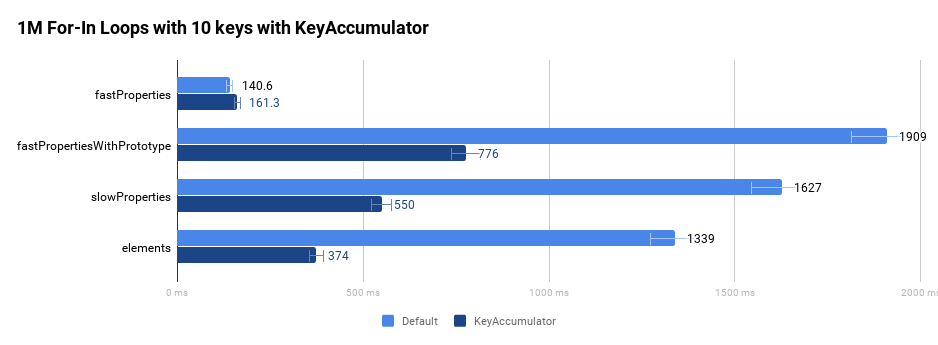
Como destacamos na introdução, essas melhorias tornaram-se muito visíveis no Wikipedia e no Facebook, em particular.
Além das melhorias iniciais disponíveis no Chrome 51, um segundo ajuste de desempenho gerou outra melhoria significativa. O gráfico a seguir mostra nossos dados de rastreamento do tempo total gasto no script durante a inicialização de uma página do Facebook. O intervalo selecionado ao redor da revisão V8 37937 corresponde a uma melhoria de desempenho adicional de 4%!

Para destacar a importância de melhorar for-in, podemos contar com dados de uma ferramenta que construímos em 2016, que nos permite extrair medições do V8 em um conjunto de sites. A tabela a seguir mostra o tempo relativo gasto em pontos de entrada do V8 C++ (funções runtime e embutidas) para Chrome 49 em um conjunto de aproximadamente 25 sites reais representativos.
| Posição | Nome | Tempo Total |
|---|---|---|
| 1 | CreateObjectLiteral | 1.10% |
| 2 | NewObject | 0.90% |
| 3 | KeyedGetProperty | 0.70% |
| 4 | GetProperty | 0.60% |
| 5 | ForInEnumerate | 0.60% |
| 6 | SetProperty | 0.50% |
| 7 | StringReplaceGlobalRegExpWithString | 0.30% |
| 8 | HandleApiCallConstruct | 0.30% |
| 9 | RegExpExec | 0.30% |
| 10 | ObjectProtoToString | 0.30% |
| 11 | ArrayPush | 0.20% |
| 12 | NewClosure | 0.20% |
| 13 | NewClosure_Tenured | 0.20% |
| 14 | ObjectDefineProperty | 0.20% |
| 15 | HasProperty | 0.20% |
| 16 | StringSplit | 0.20% |
| 17 | ForInFilter | 0.10% |