Otimizando proxies ES2015 no V8
Os proxies são parte integrante do JavaScript desde o ES2015. Eles permitem interceptar operações fundamentais em objetos e personalizar seu comportamento. Proxies formam uma parte central de projetos como jsdom e a biblioteca RPC Comlink. Recentemente, fizemos um grande esforço para melhorar o desempenho dos proxies no V8. Este artigo lança luz sobre padrões gerais de melhoria de desempenho no V8 e, em particular, para proxies.
Proxies são "objetos usados para definir comportamento personalizado para operações fundamentais (ex.: busca de propriedades, atribuições, enumeração, invocação de função, etc.)" (definição pelo MDN). Mais informações podem ser encontradas na especificação completa. Por exemplo, o seguinte trecho de código adiciona um registro em cada acesso à propriedade no objeto:
const target = {};
const callTracer = new Proxy(target, {
get: (target, name, receiver) => {
console.log(`get foi chamado para: ${name}`);
return target[name];
}
});
callTracer.property = 'value';
console.log(callTracer.property);
// get foi chamado para: property
// value
Construindo proxies
A primeira funcionalidade que focaremos é a construção de proxies. Nossa implementação original em C++ seguiu a especificação ECMAScript passo a passo, resultando em pelo menos 4 saltos entre os runtimes de C++ e JS, conforme mostrado na figura a seguir. Queríamos portar essa implementação para o CodeStubAssembler (CSA) independente de plataforma, que é executado no runtime do JS em vez do runtime do C++. Essa portabilidade minimiza o número de saltos entre os runtimes das linguagens. CEntryStub e JSEntryStub representam os runtimes na figura abaixo. As linhas pontilhadas representam as fronteiras entre os runtimes de JS e C++. Felizmente, muitos predicados auxiliares já foram implementados no assembler, o que tornou a versão inicial concisa e legível.
A figura abaixo mostra o fluxo de execução para chamar um Proxy com qualquer armadilha de proxy (neste exemplo apply, que é chamada quando o proxy é usado como uma função) gerada pelo seguinte código de exemplo:
function foo(…) { … }
const g = new Proxy({ … }, {
apply: foo,
});
g(1, 2);
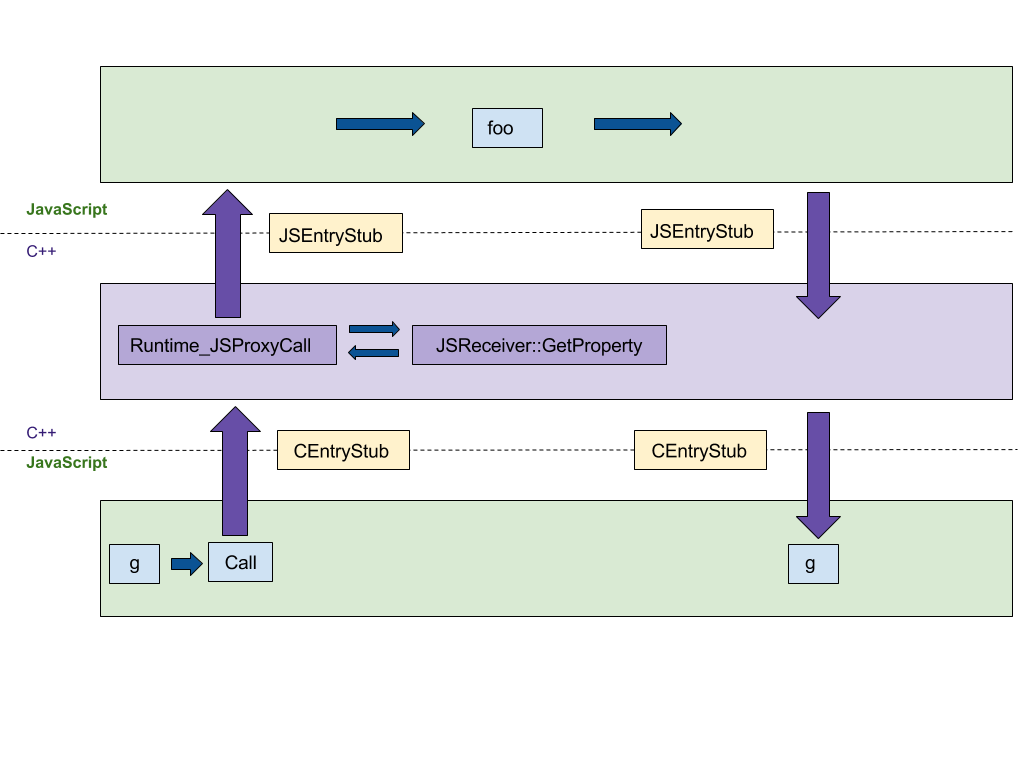
Após portar a execução de armadilhas para o CSA, toda a execução acontece no runtime JS, reduzindo o número de saltos entre linguagens de 4 para 0.
Essa mudança resultou nas seguintes melhorias de desempenho:
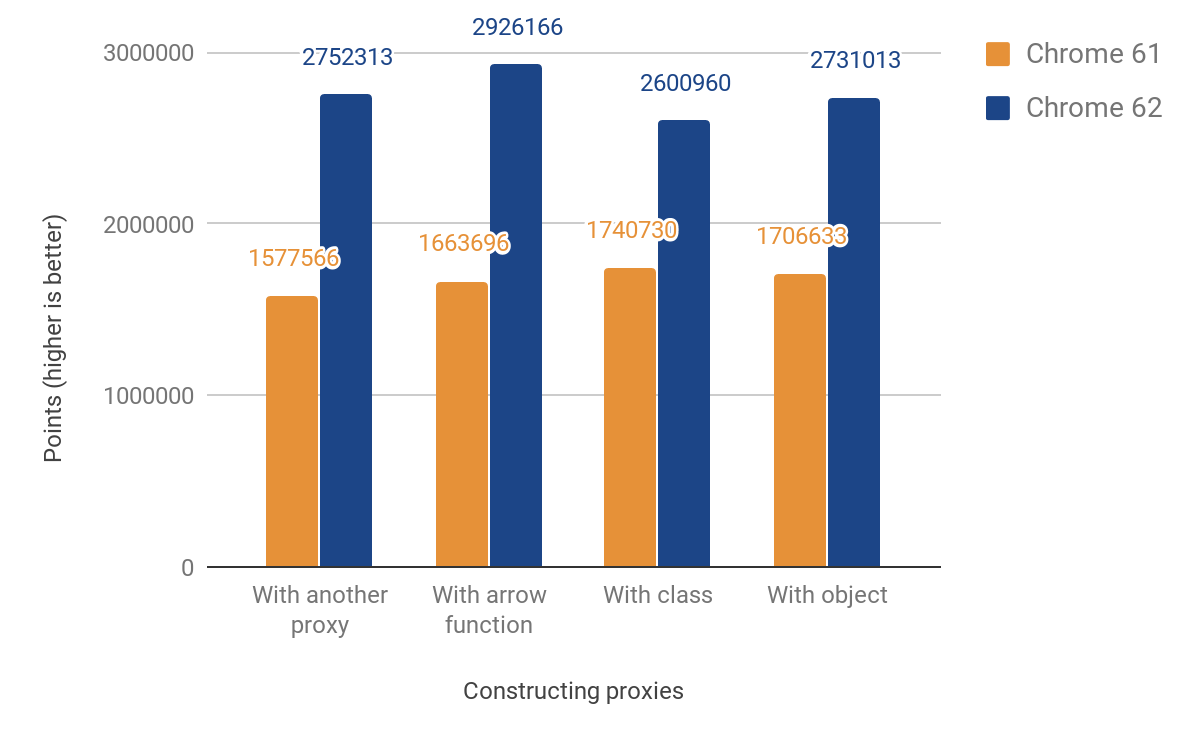
Nossa pontuação de desempenho de JS mostra uma melhoria entre 49% e 74%. Essa pontuação mede aproximadamente quantas vezes o microbenchmark fornecido pode ser executado em 1000ms. Para alguns testes, o código é executado várias vezes para obter uma medição precisa o suficiente dada a resolução do temporizador. O código para todos os benchmarks a seguir pode ser encontrado no diretório js-perf-test.
Armadilhas de chamada e construção
A próxima seção mostra os resultados da otimização de armadilhas de chamada e construção (também conhecidas como "apply" e "construct").
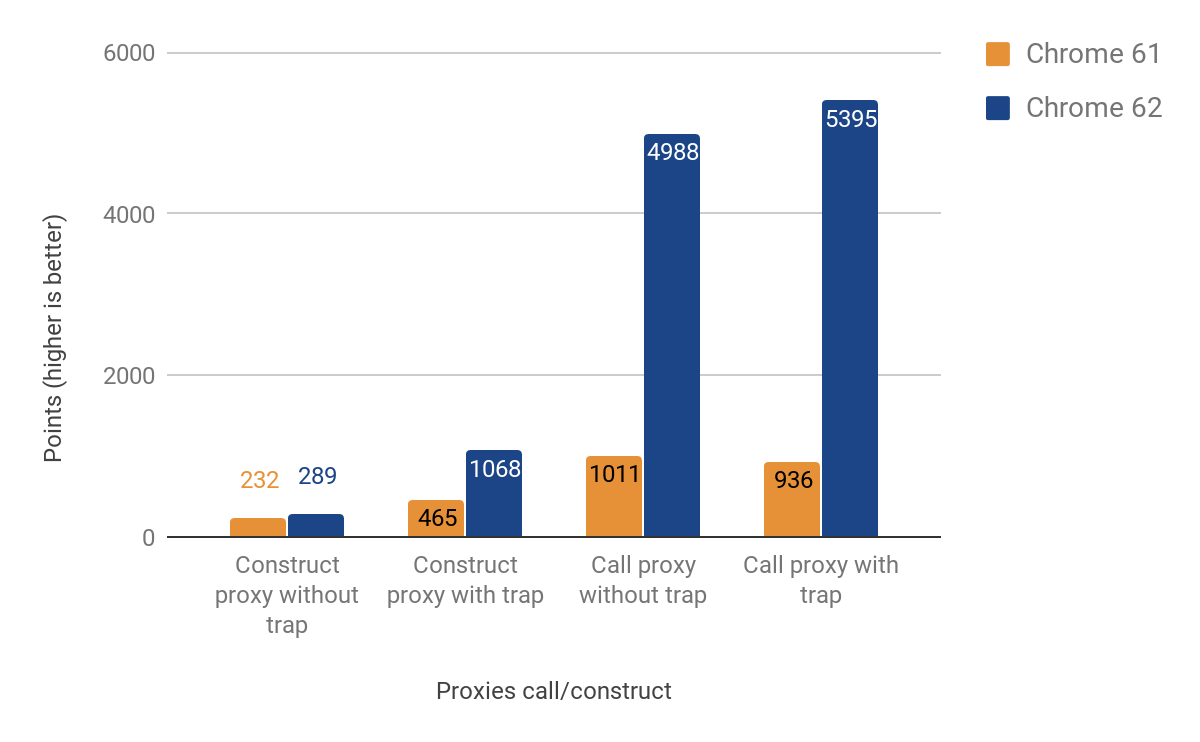
As melhorias de desempenho ao chamar proxies são significativas — até 500% mais rápidas! Ainda assim, a melhoria para construção de proxies é bastante modesta, especialmente em casos onde nenhuma armadilha real está definida — apenas cerca de 25% de ganho. Investigamos isso executando o seguinte comando com o d8 shell:
$ out/x64.release/d8 --runtime-call-stats test.js
> run: 120.104000
Runtime Function/C++ Builtin Time Count
========================================================================================
NewObject 59.16ms 48.47% 100000 24.94%
Execução_JS 23.83ms 19.53% 1 0.00%
RecompilarSincronamente 11.68ms 9.57% 20 0.00%
Callback_GetterNomeAcessório 10.86ms 8.90% 100000 24.94%
Callback_GetterNomeAcessório_FuncãoProtótipo 5.79ms 4.74% 100000 24.94%
Mapa_ProtótipoSet 4.46ms 3.65% 100203 25.00%
… FRAGMENTO …
Onde o código fonte de test.js é:
function MyClass() {}
MyClass.prototype = {};
const P = new Proxy(MyClass, {});
function run() {
return new P();
}
const N = 1e5;
console.time('correr');
for (let i = 0; i < N; ++i) {
run();
}
console.timeEnd('correr');
Concluiu-se que a maior parte do tempo é gasto em NovoObjeto e nas funções chamadas por ele, então começamos a planejar como acelerar isso em futuras versões.
Trap de Get
A próxima seção descreve como otimizamos as operações mais comuns — obter e definir propriedades através de proxies. Descobriu-se que o trap get é mais complexo que os casos anteriores, devido ao comportamento específico do cache inline do V8. Para uma explicação detalhada sobre caches inline, você pode assistir a esta palestra.
Finalmente conseguimos fazer um port funcional para CSA com os seguintes resultados:
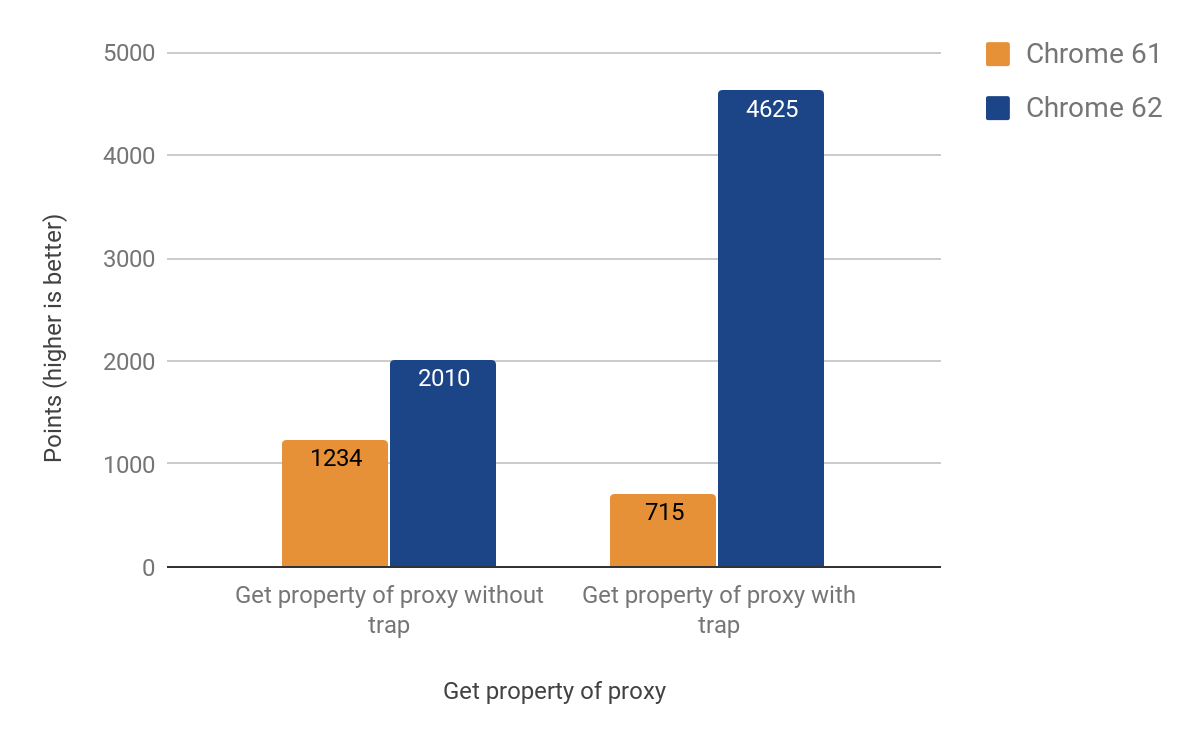
Após a implementação da alteração, notamos que o tamanho do .apk do Android para Chrome havia aumentado em ~160KB, muito mais do que o esperado para uma função auxiliar de cerca de 20 linhas, mas felizmente rastreamos estatísticas como esta. Descobriu-se que essa função é chamada duas vezes a partir de outra função, que é chamada 3 vezes, outra chamada 4 vezes. O problema foi causado pelo agressivo processo de inlining. Eventualmente resolvemos o problema transformando a função inline em um trecho de código separado, economizando úteis KBs — a versão final teve um aumento de apenas ~19KB no tamanho do .apk.
Trap de Has
A próxima seção mostra os resultados da otimização do trap has. Embora no início pensássemos que seria mais fácil (e reutilizaria a maior parte do código do trap get), descobriu-se que possui suas próprias peculiaridades. Um problema particularmente difícil de resolver foi a caminhada na cadeia de protótipos ao chamar o operador in. Os resultados de melhoria alcançados variam entre 71% e 428%. Novamente, o ganho é mais proeminente nos casos onde o trap está presente.
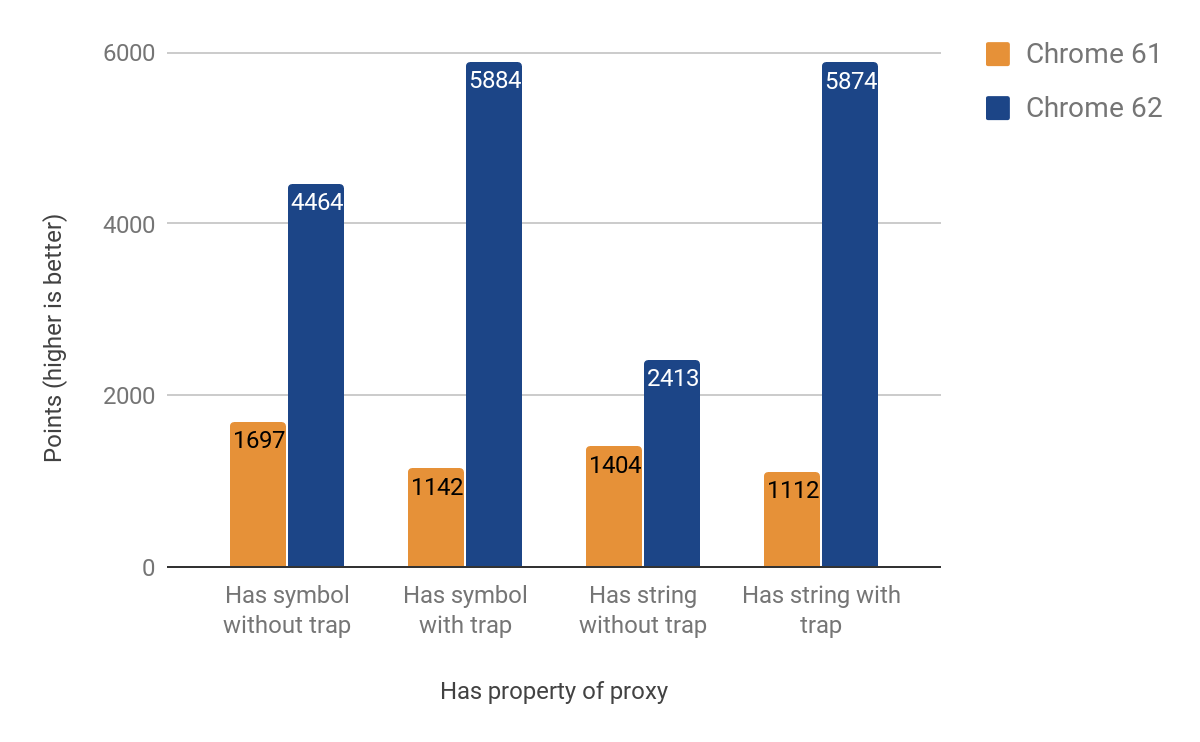
Trap de Set
A próxima seção fala sobre portar o trap set. Desta vez tivemos que diferenciar entre propriedades nomeadas e indexadas (elementos). Esses dois tipos principais não fazem parte da linguagem JS, mas são essenciais para o armazenamento eficiente de propriedades no V8. A implementação inicial ainda retornava ao tempo de execução para elementos, o que causa novamente a travessia das fronteiras da linguagem. No entanto, alcançamos melhorias entre 27% e 438% nos casos em que o trap está definido, ao custo de uma redução de até 23% quando não está. Essa regressão de desempenho é devido à sobrecarga de verificações adicionais para diferenciar entre propriedades indexadas e nomeadas. Para propriedades indexadas, ainda não há melhorias. Aqui estão os resultados completos:
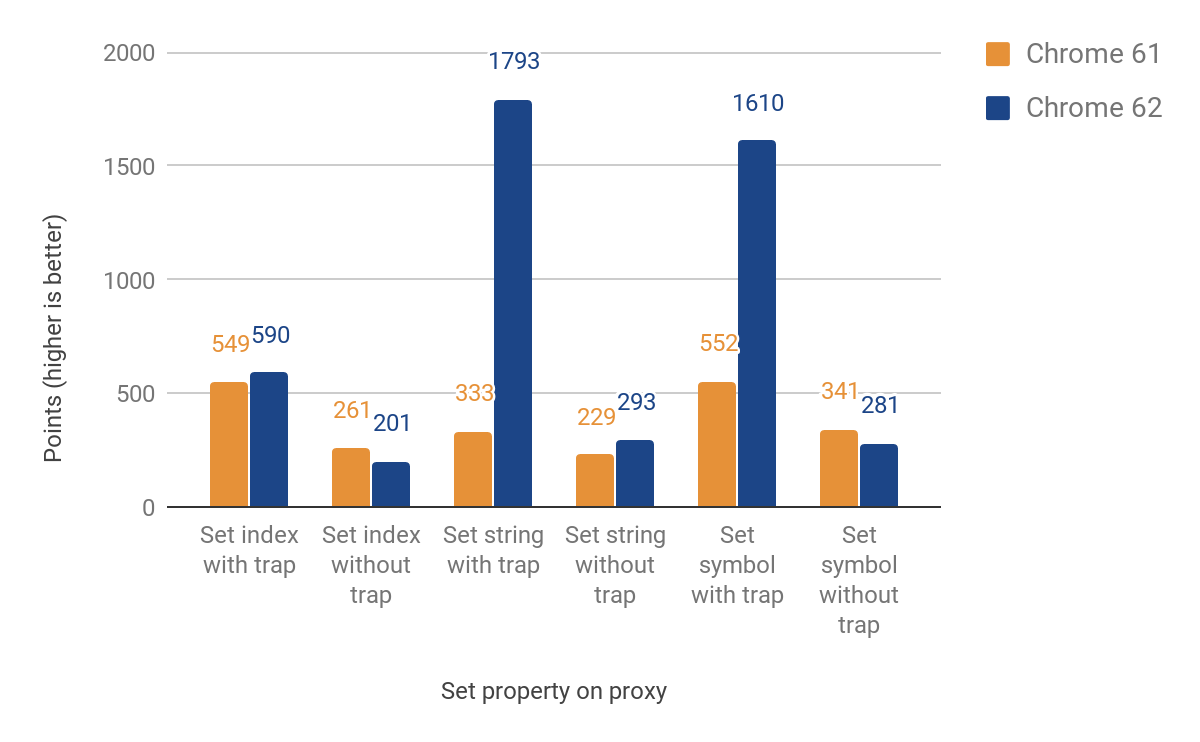
Uso no mundo real
Resultados de jsdom-proxy-benchmark
O projeto jsdom-proxy-benchmark compila a especificação ECMAScript usando a ferramenta Ecmarkup. A partir da v11.2.0, o projeto jsdom (que é a base para o Ecmarkup) usa proxies para implementar as estruturas de dados comuns NodeList e HTMLCollection. Usamos este benchmark para obter uma visão geral de um uso mais realista do que os micro-benchmarks sintéticos, e obtivemos os seguintes resultados, média de 100 execuções:
- Node v8.4.0 (sem otimizações de Proxy): 14277 ± 159 ms
- Node v9.0.0-v8-canary-20170924 (com apenas metade dos traps portados): 11789 ± 308 ms
- Ganho de velocidade em torno de 2.4 segundos, o que é ~17% melhor
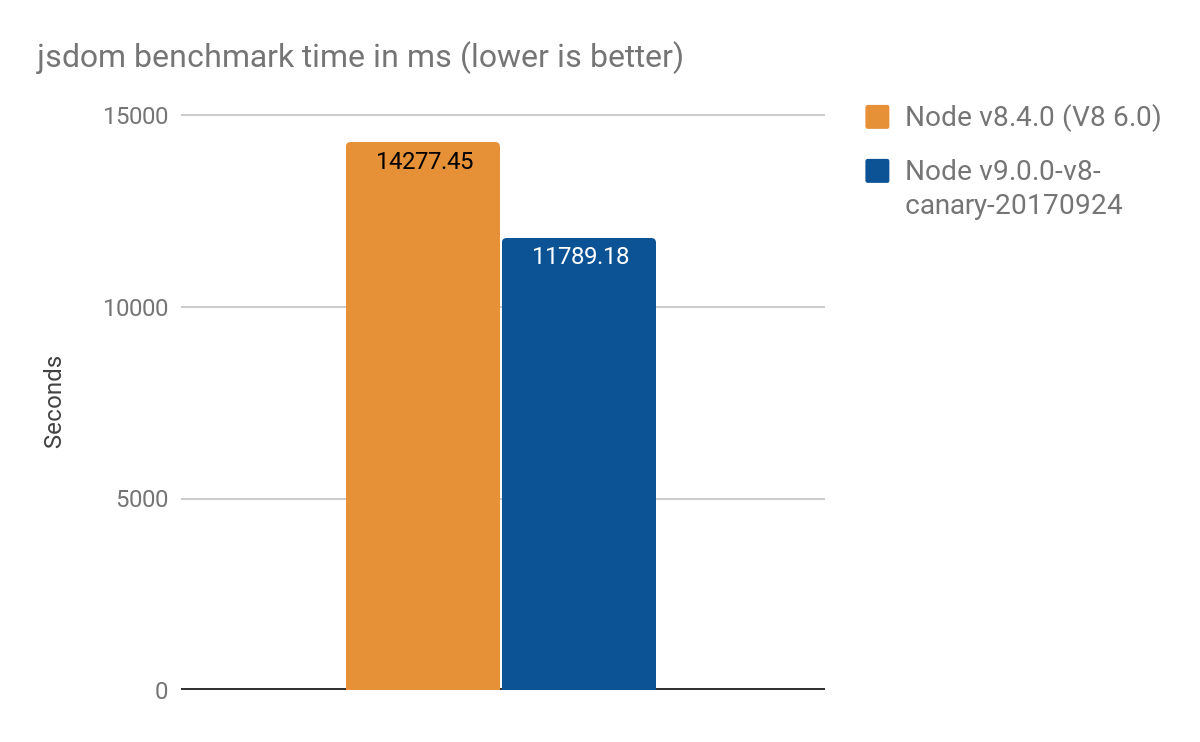
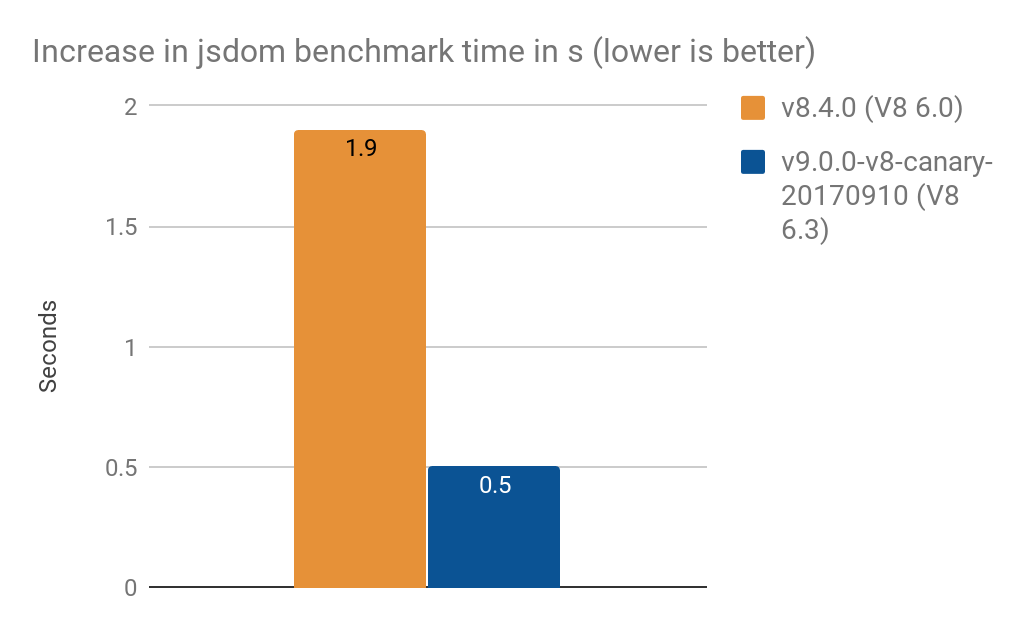
- Converter
NamedNodeMappara usarProxyaumentou o tempo de processamento em- 1.9 s no V8 6.0 (Node v8.4.0)
- 0.5 s no V8 6.3 (Node v9.0.0-v8-canary-20170910)
Nota: Esses resultados foram fornecidos por Timothy Gu. Obrigado!
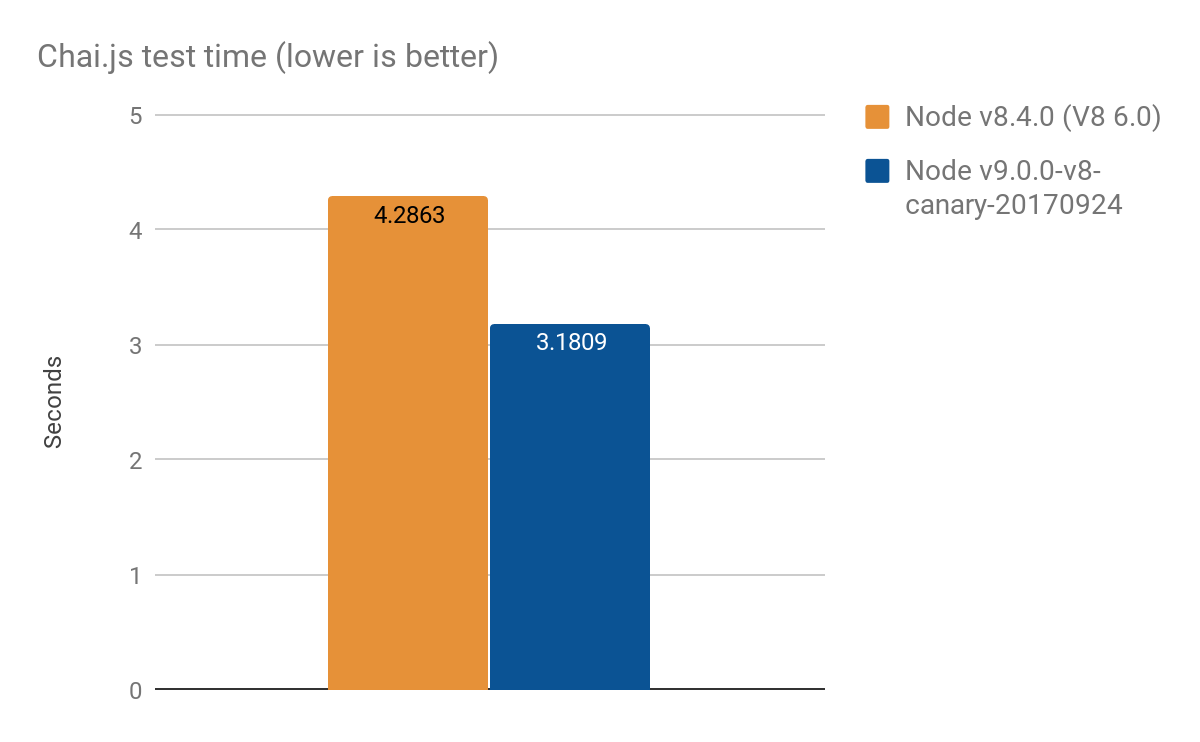
Resultados de Chai.js
Chai.js é uma biblioteca popular de asserção que utiliza intensivamente proxies. Criamos um tipo de benchmark do mundo real executando seus testes com diferentes versões do V8, uma melhoria de cerca de 1s em mais de 4s, média de 100 execuções:
- Node v8.4.0 (sem otimizações de Proxy): 4.2863 ± 0.14 s
- Node v9.0.0-v8-canary-20170924 (com apenas metade das armadilhas portadas): 3.1809 ± 0.17 s
Abordagem de otimização
Frequentemente enfrentamos problemas de desempenho usando um esquema genérico de otimização. A abordagem principal que seguimos para este trabalho específico incluiu os seguintes passos:
- Implementar testes de desempenho para o sub-recurso específico
- Adicionar mais testes de conformidade de especificação (ou criá-los do zero)
- Investigar a implementação original em C++
- Portar o sub-recurso para o CodeStubAssembler independente de plataforma
- Otimizar ainda mais o código criando manualmente uma implementação TurboFan
- Medir a melhoria de desempenho.
Essa abordagem pode ser aplicada a qualquer tarefa geral de otimização que você tenha.