Integrados incorporados
Las funciones integradas de V8 (builtins) consumen memoria en cada instancia de V8. La cantidad de integrados, el tamaño promedio y el número de instancias de V8 por pestaña del navegador Chrome han crecido significativamente. Esta publicación de blog describe cómo reducimos el tamaño mediano del montón de V8 por sitio web en un 19% durante el último año.
Antecedentes
V8 se entrega con una amplia biblioteca de funciones integradas (JS) de JavaScript. Muchos integrados están directamente expuestos a los desarrolladores de JS como funciones instaladas en objetos integrados de JS, como RegExp.prototype.exec y Array.prototype.sort; otros integrados implementan diversas funcionalidades internas. El código máquina para los integrados es generado por el propio compilador de V8 y se carga en el estado del montón gestionado para cada Isolate de V8 al inicializarse. Un Isolate representa una instancia aislada del motor V8, y cada pestaña del navegador Chrome contiene al menos un Isolate. Cada Isolate tiene su propio montón gestionado y, por tanto, su propia copia de todos los integrados.
En 2015, los integrados se implementaban principalmente en JS alojado localmente, ensamblador nativo o en C++. Eran bastante pequeños y crear una copia para cada Isolate era menos problemático.
Muchas cosas han cambiado en este ámbito en los últimos años.
En 2016, V8 comenzó a experimentar con integrados implementados en CodeStubAssembler (CSA). Esto resultó ser tanto conveniente (independiente de la plataforma, legible) como capaz de producir código eficiente, por lo que los integrados CSA se volvieron ubicuos. Por diversas razones, los integrados CSA tienden a producir código más grande, y el tamaño de los integrados de V8 se triplicó aproximadamente a medida que más y más se portaron a CSA. Para mediados de 2017, su sobrecarga por Isolate había crecido significativamente y comenzamos a pensar en una solución sistemática.
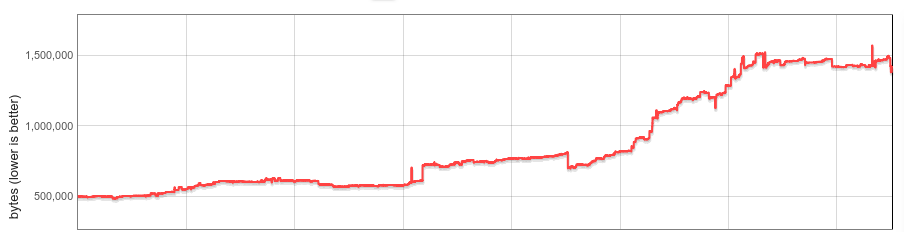
A finales de 2017, implementamos la deserialización diferida de integrados (y controladores de bytecode) como primer paso. Nuestro análisis inicial mostró que la mayoría de los sitios usaban menos de la mitad de todos los integrados. Con la deserialización diferida, los integrados se cargan según sea necesario, y los integrados no utilizados nunca se cargan en el Isolate. La deserialización diferida se lanzó en Chrome 64 con prometedores ahorros de memoria. Pero: la sobrecarga de memoria de los integrados seguía siendo lineal en función del número de Isolates.
Luego, se divulgó Spectre, y Chrome finalmente activó la aislación por sitio para mitigar sus efectos. La aislación por sitio limita un proceso de renderización de Chrome a documentos de un único origen. Por lo tanto, con la aislación por sitio, muchas pestañas de navegación crean más procesos de renderización y más Isolates de V8. Aunque siempre ha sido importante gestionar la sobrecarga por Isolate, la aislación por sitio lo ha hecho aún más crítico.
Integrados incorporados
Nuestro objetivo para este proyecto era eliminar por completo la sobrecarga de integrados por Isolate.
La idea detrás de esto era simple. Conceptualmente, los integrados son idénticos entre Isolates, y solo están vinculados a un Isolate debido a detalles de implementación. Si pudiéramos hacer que los integrados fueran verdaderamente independientes del Isolate, podríamos mantener una única copia en memoria y compartirlos entre todos los Isolates. Y si pudiéramos hacerlos independientes del proceso, incluso podrían compartirse entre procesos.
En la práctica, enfrentamos varios desafíos. El código generado de los integrados no era ni independiente del Isolate ni del proceso debido a punteros incrustados hacia datos específicos del Isolate y del proceso. V8 no tenía concepto de ejecutar código generado ubicado fuera del montón gestionado. Los integrados debían compartirse entre procesos, idealmente reutilizando mecanismos existentes del sistema operativo. Y finalmente (esto resultó ser lo más complicado a largo plazo), el rendimiento no debía degradarse notablemente.
Las siguientes secciones describen nuestra solución en detalle.
Código independiente del Isolate y del proceso
Los integrados son generados por la tubería interna del compilador de V8, que incrusta referencias a constantes del montón (ubicadas en el montón gestionado del Isolate), objetivos de llamada (objetos Code, también en el montón gestionado), y a direcciones específicas del Isolate y del proceso (por ejemplo: funciones en tiempo de ejecución de C o un puntero al propio Isolate, también conocidas como ’referencias externas’) directamente en el código. En el ensamblador x64, una carga de tal objeto podría verse de la siguiente manera:
// Carga una dirección incrustada en el registro rbx.
REX.W movq rbx,0x56526afd0f70
V8 tiene un recolector de basura en movimiento, y la ubicación del objeto objetivo podría cambiar con el tiempo. Si el objetivo se mueve durante la recolección, el GC actualiza el código generado para apuntar a la nueva ubicación.
En x64 (y en la mayoría de las demás arquitecturas), las llamadas a otros objetos Code utilizan una instrucción de llamada eficiente que especifica el objetivo de la llamada mediante un desplazamiento desde el contador de programa actual (un detalle interesante: V8 reserva todo su CODE_SPACE en el montón gestionado al inicio para garantizar que todos los posibles objetos de código permanezcan dentro de un desplazamiento direccionable entre sí). La parte relevante de la secuencia de llamada se ve así:
// Instrucción de llamada ubicada en [pc + <desplazamiento>].
call <desplazamiento>
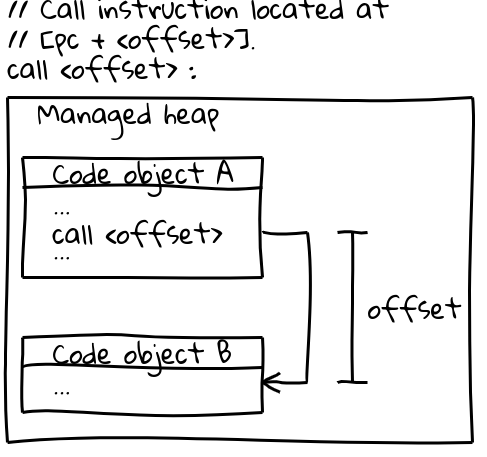
Los objetos de código viven en el montón gestionado y son movibles. Cuando se mueven, el GC actualiza el desplazamiento en todos los sitios de llamada relevantes.
Para compartir las funciones internas entre procesos, el código generado debe ser inmutable, así como independiente del aislamiento y del proceso. Las dos secuencias de instrucciones anteriores no cumplen ese requisito: incrustan directamente direcciones en el código y son actualizadas en tiempo de ejecución por el GC.
Para abordar ambos problemas, introdujimos una indirecta a través de un registro raíz dedicado, llamado así, que contiene un puntero hacia una ubicación conocida dentro del aislamiento actual.
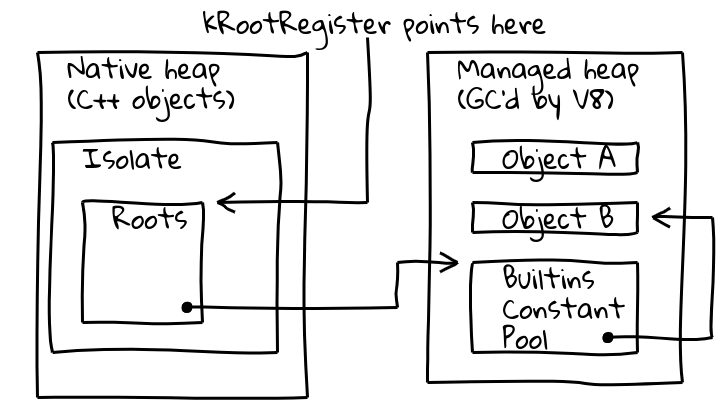
La clase Isolate de V8 contiene la tabla de raíces, que a su vez contiene punteros a objetos raíz en el montón gestionado. El registro raíz contiene permanentemente la dirección de la tabla de raíces.
La nueva forma independiente del aislamiento y del proceso para cargar un objeto raíz se convierte así en:
// Carga la dirección constante ubicada en el
// desplazamiento dado desde raíces.
REX.W movq rax,[kRootRegister + <desplazamiento>]
Las constantes del montón raíz se pueden cargar directamente desde la lista de raíces como se indicó anteriormente. Otras constantes del montón utilizan una indirecta adicional a través de un grupo de constantes internas globales, que se almacena a su vez en la lista de raíces:
// Carga el grupo de constantes internas, luego la
// constante deseada.
REX.W movq rax,[kRootRegister + <desplazamiento>]
REX.W movq rax,[rax + 0x1d7]
Para los objetivos Code, inicialmente cambiamos a una secuencia de llamada más elaborada que carga el objeto Code del grupo de constantes internas globales como se indicó anteriormente, carga la dirección del objetivo en un registro y finalmente realiza una llamada indirecta.
Con estos cambios, el código generado se volvió independiente del aislamiento y del proceso, y pudimos comenzar a trabajar en compartirlo entre procesos.
Compartiendo entre procesos
Inicialmente evaluamos dos alternativas. Las funciones internas podían compartirse mediante mmap para mapear un archivo de datos en memoria; o bien, podían incrustarse directamente en el binario. Tomamos este último enfoque ya que tenía la ventaja de que reutilizaríamos automáticamente los mecanismos estándar del sistema operativo para compartir memoria entre procesos, y el cambio no requeriría lógica adicional por parte de los integradores de V8, como Chrome. Estábamos seguros de este enfoque porque la compilación AOT de Dart ya había incrustado con éxito un código generado en binarios.
Un archivo binario ejecutable se divide en varias secciones. Por ejemplo, un binario ELF contiene datos en las secciones .data (datos inicializados), .ro_data (datos de solo lectura inicializados) y .bss (datos no inicializados), mientras que el código ejecutable nativo se coloca en .text. Nuestro objetivo era empaquetar el código de las funciones internas en la sección .text junto con el código nativo.
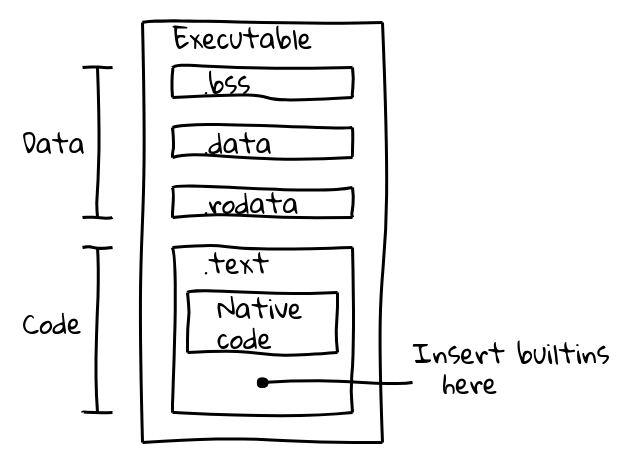
Esto se logró introduciendo un nuevo paso de construcción que utilizaba la tubería del compilador interno de V8 para generar código nativo para todas las funciones internas y exportar sus contenidos en embedded.cc. Este archivo se compila entonces en el binario final de V8.
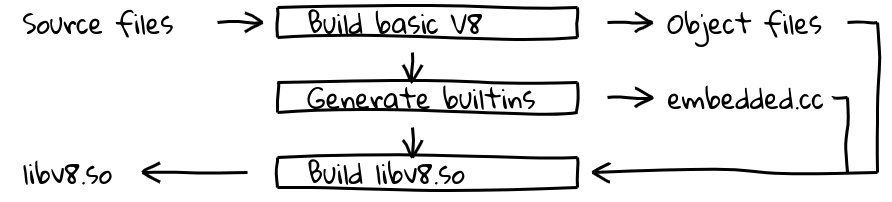
El archivo embedded.cc contiene tanto metadatos como código máquina generado de las funciones internas en forma de una serie de directivas .byte que instruyen al compilador de C++ (en nuestro caso, clang o gcc) para colocar directamente la secuencia de bytes especificada en el archivo objeto de salida (y luego en el ejecutable).
// La información sobre las funciones internas incrustadas se incluye en
// una tabla de metadatos.
V8_EMBEDDED_TEXT_HEADER(v8_Default_embedded_blob_)
__asm__(".byte 0x65,0x6d,0xcd,0x37,0xa8,0x1b,0x25,0x7e\n"
[metadatos recortados]
// Seguido del código máquina generado.
__asm__(V8_ASM_LABEL("Builtins_RecordWrite"));
__asm__(".byte 0x55,0x48,0x89,0xe5,0x6a,0x18,0x48,0x83\n"
[código de funciones internas recortado]
Los contenidos de la sección .text se mapean en memoria ejecutable de solo lectura en tiempo de ejecución, y el sistema operativo compartirá memoria entre procesos siempre que contenga únicamente código independiente de posición sin símbolos reubicables. Esto es exactamente lo que queríamos.
Pero los objetos Code de V8 consisten no solo en el flujo de instrucciones, sino que también contienen varias piezas de metadatos (a veces dependientes del aislamiento). Los objetos Code comunes y corrientes empaquetan tanto metadatos como el flujo de instrucciones en un objeto Code de tamaño variable que se encuentra en el heap gestionado.
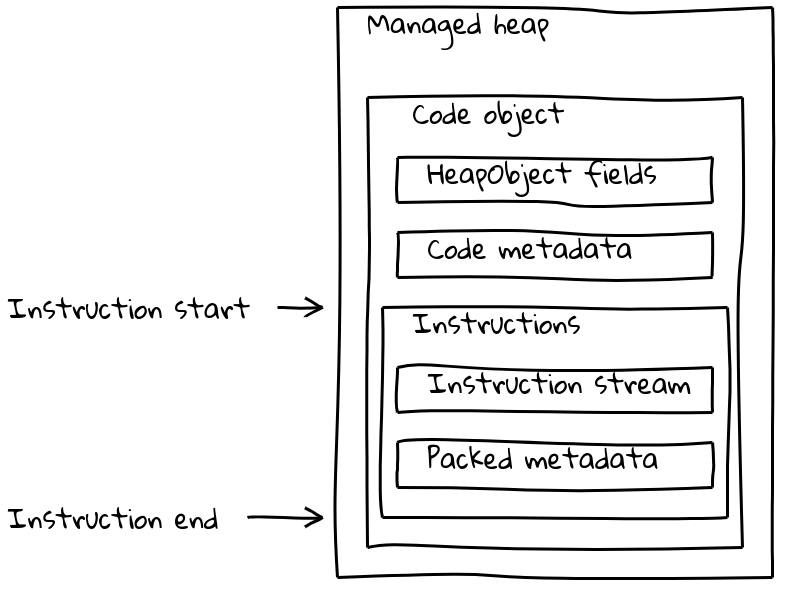
Como hemos visto, los builtins embebidos tienen su flujo de instrucciones nativo ubicado fuera del heap gestionado, embebido en la sección .text. Para preservar sus metadatos, cada builtin embebido también tiene un pequeño objeto Code asociado en el heap gestionado, llamado trampolín fuera del heap. Los metadatos se almacenan en el trampolín como en los objetos Code estándar, mientras que el flujo de instrucciones incorporado simplemente contiene una corta secuencia que carga la dirección de las instrucciones embebidas y salta allí.
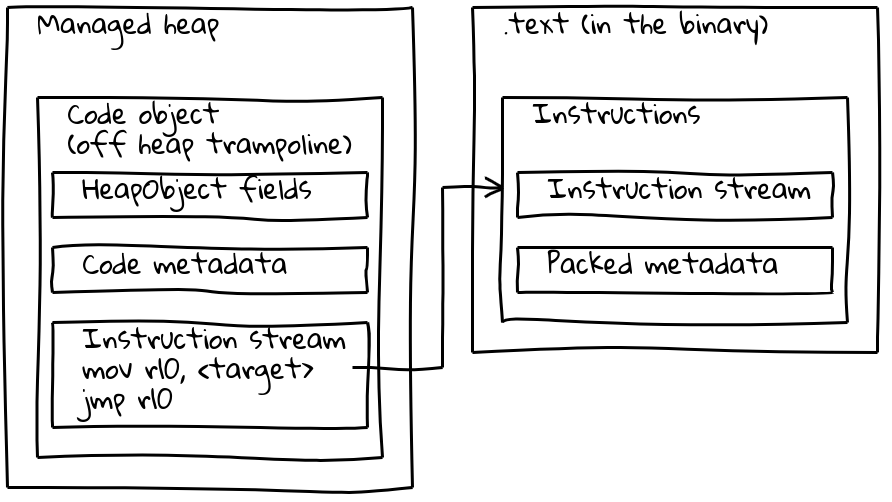
El trampolín permite a V8 manejar todos los objetos Code de manera uniforme. Para la mayoría de los propósitos, es irrelevante si el objeto Code dado se refiere a código estándar en el heap gestionado o a un builtin embebido.
Optimizando para el rendimiento
Con la solución descrita en las secciones anteriores, los builtins embebidos estaban esencialmente completos en cuanto a características, pero los benchmarks mostraban que venían con ralentizaciones significativas. Por ejemplo, nuestra solución inicial retrocedió Speedometer 2.0 en más del 5% en general.
Comenzamos a buscar oportunidades de optimización y identificamos principales fuentes de ralentización. El código generado era más lento debido a las frecuentes indirections realizadas para acceder a objetos dependientes del aislamiento y del proceso. Las constantes raíz se cargaban desde la lista raíz (1 indirection), otras constantes del heap desde el pool de constantes de builtins globales (2 indirections), y las referencias externas además tenían que ser desempacadas desde dentro de un objeto del heap (3 indirections). El peor culpable era nuestra nueva secuencia de llamadas, que tenía que cargar el objeto Code del trampolín, llamarlo, solo para luego saltar a la dirección objetivo. Finalmente, parece que las llamadas entre el heap gestionado y el código embebido en binarios eran inherentemente más lentas, posiblemente debido a la larga distancia de salto que interfería con la predicción de ramas de la CPU.
Nuestro trabajo se concentró en 1. reducir las indirections, y 2. mejorar la secuencia de llamadas de los builtins. Para abordar lo primero, alteramos el diseño del objeto Isolate para convertir la mayoría de las cargas de objetos en una única carga relativa a la raíz. El pool de constantes de builtins globales todavía existe, pero solo contiene objetos accedidos con poca frecuencia.
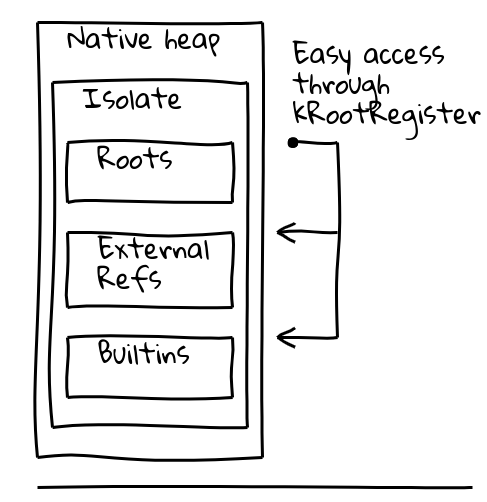
Las secuencias de llamadas se mejoraron significativamente en dos frentes. Las llamadas entre builtins se convirtieron en una sola instrucción de llamada relacionada con pc. Esto no fue posible para código JIT generado en tiempo de ejecución ya que el desplazamiento relativo al pc podría exceder el valor máximo de 32 bits. Allí, integramos el trampolín fuera del heap en todos los sitios de llamada, reduciendo la secuencia de llamadas de 6 a solo 2 instrucciones.
Con estas optimizaciones, logramos limitar los retrocesos en Speedometer 2.0 a aproximadamente 0.5%.
Resultados
Evaluamos el impacto de los builtins embebidos en x64 en los 10k sitios web más populares y los comparamos tanto con deserialización diferida como con anticipada (descritas anteriormente).
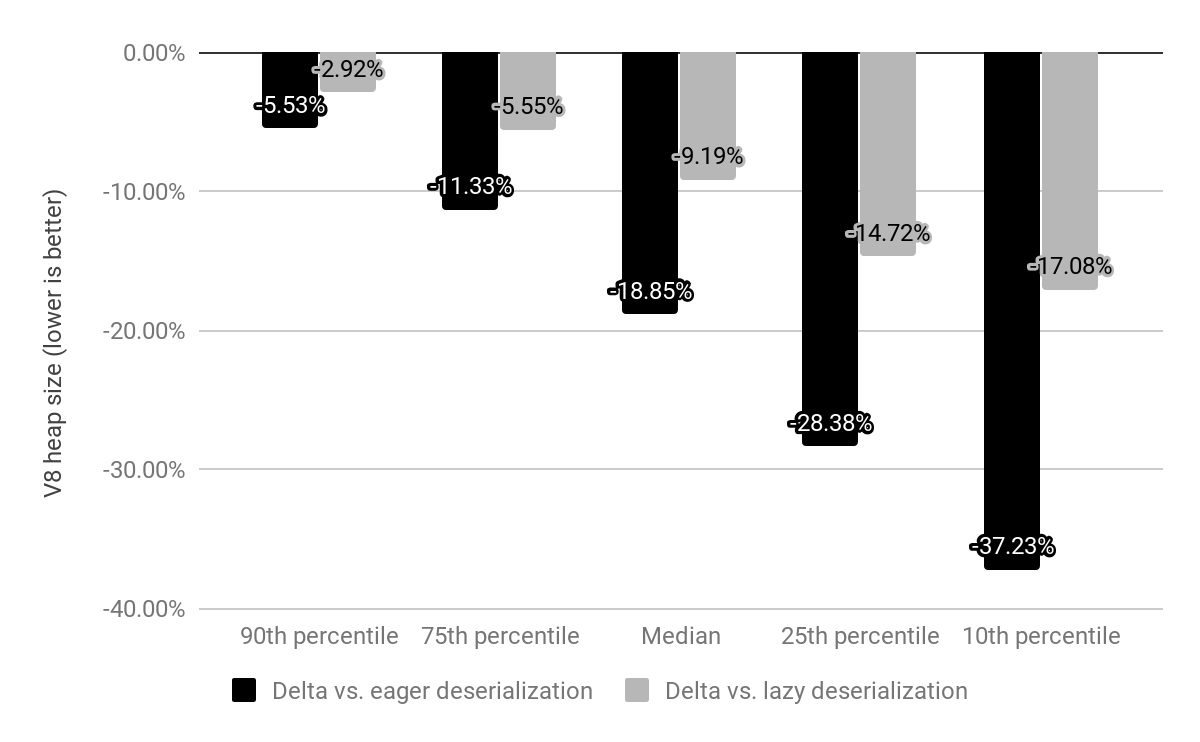
Mientras que previamente Chrome enviaba con un snapshot mapeado en memoria que deserializábamos en cada Isolate, ahora el snapshot se reemplaza por builtins embebidos que todavía están mapeados en memoria pero no necesitan ser deserializados. El costo para builtins solía ser c*(1 + n) donde n es el número de Isolates y c el costo de memoria de todos los builtins, mientras que ahora es solo c * 1 (en la práctica, también queda una pequeña cantidad de sobrecarga por Isolate para trampolines fuera del heap).
En comparación con la deserialización anticipada, redujimos el tamaño medio del heap de V8 en un 19%. El tamaño medio del proceso del renderer de Chrome por sitio ha disminuido un 4%. En números absolutos, el percentil 50 ahorra 1.9 MB, el percentil 30 ahorra 3.4 MB y el percentil 10 ahorra 6.5 MB por sitio.
Se esperan ahorros adicionales significativos de memoria una vez que los manejadores de bytecode también estén embebidos en binarios.
Los builtins embebidos se están implementando en x64 en Chrome 69, y las plataformas móviles seguirán en Chrome 70. Se espera que el soporte para ia32 sea lanzado a finales de 2018.
Nota: Todos los diagramas fueron generados usando la asombrosa herramienta Shaky Diagramming de Vyacheslav Egorov.