Fonctions intégrées embarquées
Les fonctions intégrées de V8 (builtins) consomment de la mémoire dans chaque instance de V8. Le nombre de fonctions intégrées, leur taille moyenne et le nombre d'instances de V8 par onglet de navigateur Chrome ont considérablement augmenté. Ce billet de blog décrit comment nous avons réduit la taille médiane du tas V8 par site web de 19% au cours de l'année dernière.
Contexte
V8 est livré avec une vaste bibliothèque de fonctions JavaScript intégrées. De nombreuses fonctions intégrées sont directement accessibles aux développeurs JS sous forme de fonctions installées sur des objets intégrés JS, comme RegExp.prototype.exec et Array.prototype.sort; d'autres fonctions intégrées implémentent diverses fonctionnalités internes. Le code machine des fonctions intégrées est généré par le compilateur de V8 lui-même et est chargé dans l'état de tas géré pour chaque Isolate V8 lors de son initialisation. Un Isolate représente une instance isolée du moteur V8, et chaque onglet du navigateur Chrome contient au moins un Isolate. Chaque Isolate possède son propre tas géré, et donc sa propre copie de toutes les fonctions intégrées.
En 2015, les fonctions intégrées étaient principalement implémentées en JS auto-hébergé, en assemblage natif ou en C++. Elles étaient assez petites, et créer une copie pour chaque Isolate posait moins de problèmes.
Beaucoup de choses ont changé dans ce domaine ces dernières années.
En 2016, V8 a commencé à expérimenter des fonctions intégrées implémentées dans CodeStubAssembler (CSA). Cela s'est avéré à la fois pratique (indépendant de la plateforme, lisible) et produisant un code efficace, ce qui a rendu les fonctions CSA omniprésentes. Pour diverses raisons, les fonctions CSA tendent à produire un code plus volumineux, et la taille des fonctions intégrées de V8 a à peu près triplé à mesure qu'un nombre croissant d'entre elles étaient portées vers CSA. À la mi-2017, leur surcharge par Isolate avait considérablement augmenté et nous avons commencé à réfléchir à une solution systématique.
Fin 2017, nous avons mis en œuvre la désérialisation paresseuse des fonctions intégrées (et gestionnaires de bytecode) comme première étape. Notre analyse initiale a montré que la plupart des sites utilisaient moins de la moitié de toutes les fonctions intégrées. Avec la désérialisation paresseuse, les fonctions intégrées sont chargées à la demande, et les fonctions intégrées inutilisées ne sont jamais chargées dans l'Isolate. La désérialisation paresseuse a été introduite dans Chrome 64 avec des économies de mémoire prometteuses. Mais : la surcharge mémoire des fonctions intégrées restait linéaire par rapport au nombre d'Isolates.
Puis, Spectre a été divulgué, et Chrome a finalement activé l'isolation des sites pour en atténuer les effets. L'isolation des sites limite un processus de rendu Chrome aux documents provenant d'une seule origine. Ainsi, avec l'isolation des sites, de nombreux onglets de navigation créent plus de processus de rendu et davantage d'Isolates V8. Bien que la gestion de la surcharge par Isolate ait toujours été importante, l'isolation des sites l'a rendue encore plus cruciale.
Fonctions intégrées embarquées
Notre objectif pour ce projet était d'éliminer complètement la surcharge par Isolate des fonctions intégrées.
L'idée derrière était simple. Conceptuellement, les fonctions intégrées sont identiques entre les Isolates et sont uniquement liées à un Isolate en raison de détails de mise en œuvre. Si nous pouvions rendre les fonctions intégrées réellement indépendantes des Isolates, nous pourrions conserver une seule copie en mémoire et les partager entre tous les Isolates. Et si nous pouvions les rendre indépendantes des processus, elles pourraient même être partagées entre processus.
En pratique, nous avons rencontré plusieurs défis. Le code généré des fonctions intégrées n'était ni indépendant de l'Isolate ni indépendant du processus en raison de pointeurs intégrés vers des données spécifiques à l'Isolate et au processus. V8 n'avait aucun concept d'exécution de code généré situé en dehors du tas géré. Les fonctions intégrées devaient être partagées entre processus, idéalement en réutilisant les mécanismes existants du système d'exploitation. Et enfin (cela s'est avéré être le point le plus complexe), les performances ne devaient pas considérablement régresser.
Les sections suivantes décrivent notre solution en détail.
Code indépendant de l'Isolate et du processus
Les fonctions intégrées sont générées par le pipeline interne du compilateur de V8, qui intègre des références à des constantes de tas (situées dans le tas géré de l'Isolate), des cibles d'appel (objets Code, également situés dans le tas géré), ainsi qu'à des adresses spécifiques à l'Isolate et au processus (par exemple : fonctions du runtime C ou un pointeur vers l'Isolate lui-même, également appelées 'références externes') directement dans le code. En assemblage x64, un chargement de tel objet pourrait ressembler à ceci :
// Charger une adresse intégrée dans le registre rbx.
REX.W movq rbx,0x56526afd0f70
V8 possède un collecteur de déchets mobile, et l'emplacement de l'objet cible peut changer au fil du temps. Si l'objet cible est déplacé pendant la collecte, le GC met à jour le code généré pour pointer vers le nouvel emplacement.
Sur x64 (et la plupart des autres architectures), les appels à d'autres objets Code utilisent une instruction d'appel efficace qui spécifie la cible d'appel par un décalage par rapport au compteur de programme actuel (un détail intéressant : V8 réserve tout son CODE_SPACE sur le tas géré au démarrage pour s'assurer que tous les objets Code possibles restent à portée d'un décalage adressable les uns des autres). La partie pertinente de la séquence d'appel ressemble à ceci :
// Instruction d'appel située à [pc + <offset>].
call <offset>
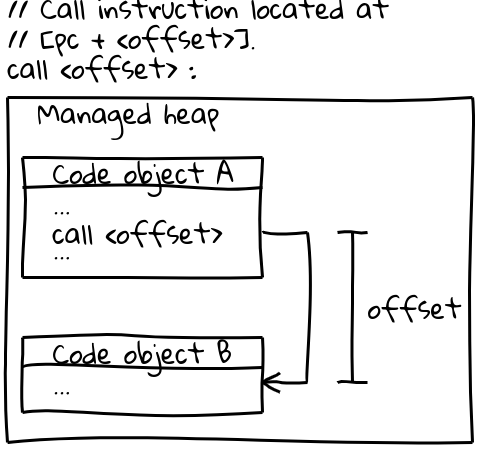
Les objets Code eux-mêmes résident sur le tas géré et sont mobiles. Lorsqu'ils sont déplacés, le GC met à jour le décalage à tous les sites d'appel pertinents.
Afin de partager des fonctions intégrées entre processus, le code généré doit être immuable ainsi qu'indépendant de l'isolate et du processus. Les deux séquences d'instructions ci-dessus ne répondent pas à cette exigence : elles intègrent directement les adresses dans le code et sont modifiées à l'exécution par le GC.
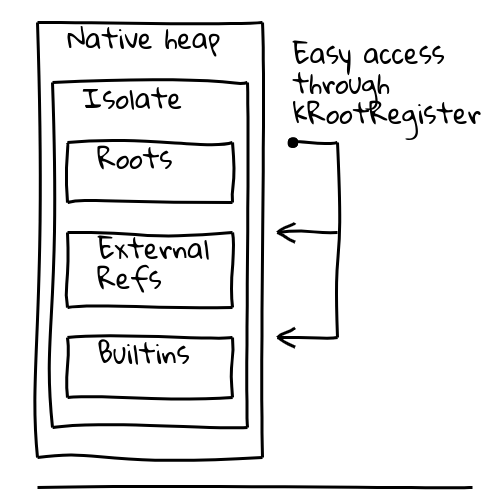
Pour résoudre ces deux problèmes, nous avons introduit une indirection via un registre racine dédié, qui contient un pointeur vers un emplacement connu au sein de l'isolate actuel.
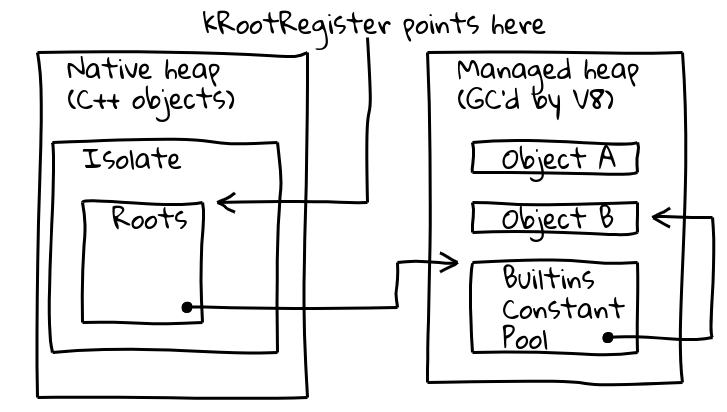
La classe Isolate de V8 contient la table des racines, qui elle-même contient des pointeurs vers des objets racines sur le tas géré. Le registre racine contient en permanence l'adresse de la table des racines.
La nouvelle manière, indépendante de l'isolate et du processus, de charger un objet racine devient donc :
// Charger l'adresse constante située au décalage donné
// à partir des racines.
REX.W movq rax,[kRootRegister + <offset>]
Les constantes du tas racine peuvent être chargées directement depuis la liste des racines comme ci-dessus. D'autres constantes du tas utilisent une indirection supplémentaire via une piscine constante globale intégrée, elle-même stockée sur la liste des racines :
// Charger la piscine constante intégrée, puis la
// constante désirée.
REX.W movq rax,[kRootRegister + <offset>]
REX.W movq rax,[rax + 0x1d7]
Pour les cibles Code, nous avons initialement changé pour une séquence d'appel plus complexe qui charge l'objet Code cible depuis la piscine constante globale intégrée comme ci-dessus, charge l'adresse cible dans un registre, puis effectue finalement un appel indirect.
Avec ces changements, le code généré est devenu indépendant de l'isolate et du processus et nous avons pu commencer à travailler sur le partage entre processus.
Partage entre processus
Nous avons initialement évalué deux alternatives. Les fonctions intégrées pouvaient être partagées soit en utilisant mmap sur un fichier blob de données en mémoire, soit elles pouvaient être directement intégrées dans le binaire. Nous avons adopté la dernière approche car elle avait l'avantage d'utiliser automatiquement les mécanismes standard du système d'exploitation pour partager la mémoire entre processus, et le changement ne nécessitait pas de logique supplémentaire de la part des intégrateurs de V8 tels que Chrome. Nous étions confiants dans cette approche car la compilation AOT de Dart avait déjà intégré avec succès du code généré dans le binaire.
Un fichier binaire exécutable est divisé en plusieurs sections. Par exemple, un binaire ELF contient des données dans les sections .data (données initialisées), .ro_data (données initialisées en lecture seule), et .bss (données non initialisées), tandis que le code exécutable natif est placé dans .text. Notre objectif était d'emballer le code des fonctions intégrées dans la section .text aux côtés du code natif.
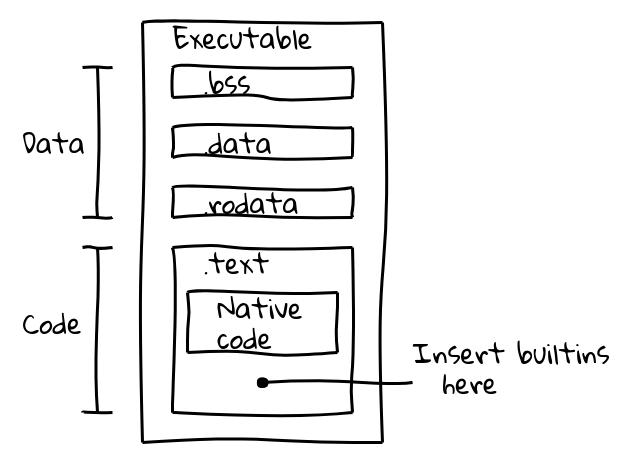
Cela a été réalisé en introduisant une nouvelle étape de compilation qui utilisait le pipeline du compilateur interne de V8 pour générer du code natif pour toutes les fonctions intégrées et produire leur contenu dans embedded.cc. Ce fichier est ensuite compilé dans le binaire final de V8.
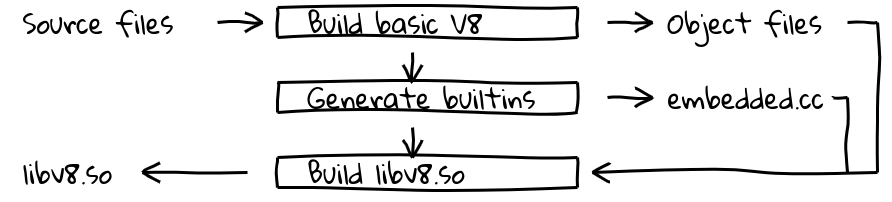
Le fichier embedded.cc lui-même contient à la fois des métadonnées et du code machine généré pour les fonctions intégrées sous forme d'une série de directives .byte qui indiquent au compilateur C++ (dans notre cas, clang ou gcc) de placer la séquence de byte spécifiée directement dans le fichier objet de sortie (et ensuite l'exécutable).
// Les informations sur les fonctions intégrées sont incluses dans
// une table de métadonnées.
V8_EMBEDDED_TEXT_HEADER(v8_Default_embedded_blob_)
__asm__(".byte 0x65,0x6d,0xcd,0x37,0xa8,0x1b,0x25,0x7e\n"
[extrait des métadonnées]
// Suivi par le code machine généré.
__asm__(V8_ASM_LABEL("Builtins_RecordWrite"));
__asm__(".byte 0x55,0x48,0x89,0xe5,0x6a,0x18,0x48,0x83\n"
[extrait du code intégré]
Le contenu de la section .text est mappé en mémoire exécutable en lecture seule à l'exécution, et le système d'exploitation partagera la mémoire entre processus tant qu'elle ne contient que du code indépendant de la position sans symboles repositionnables. C'est exactement ce que nous voulions.
Mais les objets Code de V8 ne se composent pas seulement du flux d'instructions, mais comportent également diverses métadonnées (parfois dépendantes de l'isolation). Les objets Code classiques regroupent à la fois les métadonnées et le flux d'instructions dans un objet Code de taille variable situé dans le tas géré.
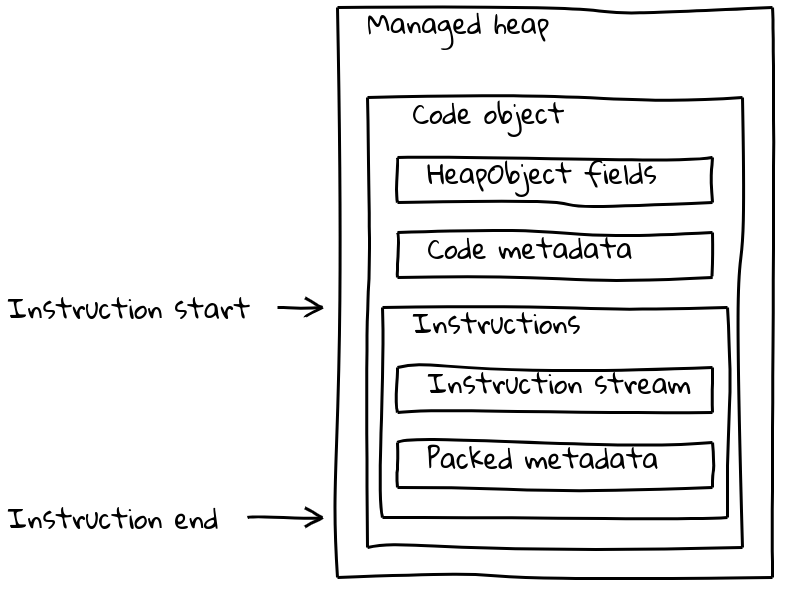
Comme nous l'avons vu, les éléments intégrés embarqués ont leur flux d'instructions natif situé en dehors du tas géré, intégré dans la section .text. Pour préserver leurs métadonnées, chaque élément intégré embarqué dispose également d'un petit objet Code associé sur le tas géré, appelé le trampoline hors tas. Les métadonnées sont stockées sur le trampoline comme pour les objets Code standard, tandis que le flux d'instructions en ligne contient simplement une courte séquence qui charge l'adresse des instructions intégrées et y saute.
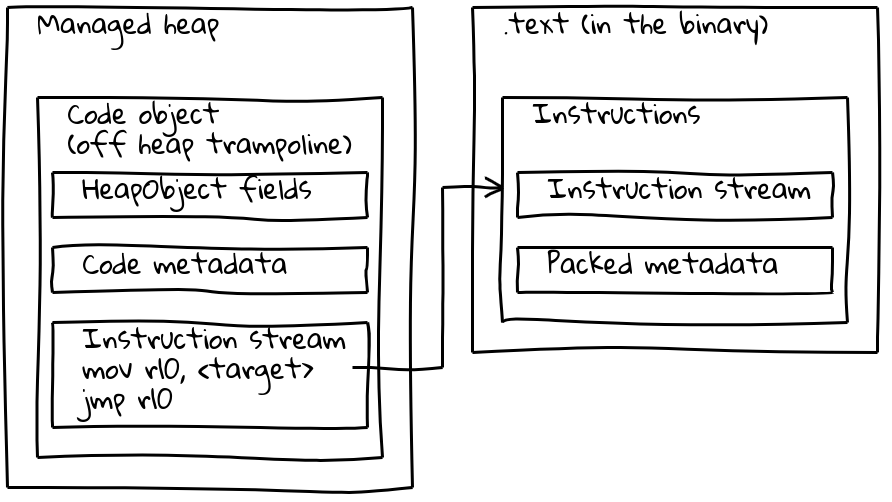
Le trampoline permet à V8 de gérer tous les objets Code de manière uniforme. Pour la plupart des usages, il est indifférent que l'objet Code donné fasse référence à un code standard sur le tas géré ou à un builtin intégré.
Optimisation des performances
Avec la solution décrite dans les sections précédentes, les éléments intégrés embarqués étaient essentiellement complets, mais les benchmarks ont montré qu'ils entraînaient d'importants ralentissements. Par exemple, notre solution initiale a diminué les performances de Speedometer 2.0 de plus de 5 % au total.
Nous avons commencé à rechercher des opportunités d'optimisation et identifié les principales sources de ralentissements. Le code généré était plus lent en raison des fréquentes indirections nécessaires pour accéder aux objets dépendants de l'isolation et du processus. Les constantes de racine étaient chargées depuis la liste de racines (1 indirection), les autres constantes du tas depuis la piscine de constantes globales des builtins (2 indirections), et les références externes devaient également être extraites d'un objet du tas (3 indirections). Le principal coupable était notre nouvelle séquence d'appel, qui devait charger l'objet Code du trampoline, l'appeler, pour ensuite sauter à l'adresse cible. Enfin, il semble que les appels entre le tas géré et le code binaire intégré étaient intrinsèquement plus lents, peut-être en raison de la longue distance de saut affectant la prédiction de branchement du processeur.
Notre travail s'est donc concentré sur 1. la réduction des indirections, et 2. l'amélioration de la séquence d'appel des éléments intégrés. Pour répondre au premier point, nous avons modifié la disposition de l'objet Isolate afin de transformer la plupart des chargements d'objets en un seul chargement relatif à la racine. La piscine de constantes globales des builtins existe encore, mais ne contient que des objets rarement accédés.
Les séquences d'appel ont été significativement améliorées sur deux fronts. Les appels builtin-à-builtin ont été convertis en une seule instruction d'appel relative au compteur de programme. Cela n'était pas possible pour le code JIT généré au moment de l'exécution, car le décalage relatif au PC pouvait dépasser la valeur maximale de 32 bits. Là, nous avons intégré en ligne le trampoline hors tas dans tous les sites d'appel, réduisant la séquence d'appel de 6 à seulement 2 instructions.
Avec ces optimisations, nous avons pu limiter les régressions sur Speedometer 2.0 à environ 0,5 %.
Résultats
Nous avons évalué l'impact des éléments intégrés embarqués sur x64 sur les 10 000 sites web les plus populaires, et comparé contre les désérialisations paresseuse et anticipée (décrites ci-dessus).

Alors qu'auparavant Chrome était livré avec un instantané mappé en mémoire que nous désérialisions pour chaque Isolate, l'instantané est maintenant remplacé par des builtins intégrés qui sont toujours mappés en mémoire mais ne nécessitent pas d'être désérialisés. Le coût des builtins était auparavant c*(1 + n) où n est le nombre d'isolats et c le coût en mémoire de tous les builtins, alors que maintenant il n'est que de c * 1 (en pratique, un léger surcoût pour les trampolines hors tas par isolat reste également).
Comparé à la désérialisation anticipée, nous avons réduit la taille médiane du tas V8 de 19 %. La taille médiane du processus de rendu Chrome par site a diminué de 4 %. En chiffres absolus, le 50e centile économise 1,9 Mo, le 30e centile économise 3,4 Mo, et le 10e centile économise 6,5 Mo par site.
Des économies de mémoire supplémentaires significatives sont attendues une fois que les gestionnaires de bytecode seront également intégrés au binaire.
Les builtins intégrés sont déployés sur x64 dans Chrome 69, et les plateformes mobiles suivront dans Chrome 70. La prise en charge de ia32 devrait être publiée fin 2018.
Remarque : Tous les diagrammes ont été générés à l'aide de l'excellent outil Shaky Diagramming de Vyacheslav Egorov.