Rápido `for`-`in` en V8
for-in es una característica del lenguaje ampliamente utilizada en muchos marcos de trabajo. A pesar de su ubicuidad, desde la perspectiva de la implementación, es una de las construcciones del lenguaje más oscuras. V8 hizo grandes esfuerzos para que esta característica fuera lo más rápida posible. En el transcurso del último año, for-in se volvió totalmente compatible con las especificaciones y hasta tres veces más rápido, dependiendo del contexto.
Muchos sitios web populares dependen en gran medida de for-in y se benefician de su optimización. Por ejemplo, a principios de 2016, Facebook usó aproximadamente el 7% de su tiempo total de JavaScript durante el inicio en la implementación de for-in por sí solo. En Wikipedia este número fue aún mayor, alrededor del 8%. Al mejorar el rendimiento de ciertos casos lentos, Chrome 51 mejoró significativamente el rendimiento en estos dos sitios web:


Wikipedia y Facebook mejoraron su tiempo total de ejecución de scripts en un 4% debido a diversas mejoras en for-in. Cabe mencionar que durante el mismo período, el resto de V8 también se volvió más rápido, lo que dio como resultado una mejora total en la ejecución de scripts de más del 4%.
En el resto de esta entrada de blog explicaremos cómo logramos acelerar esta característica principal del lenguaje y solucionar una violación de especificaciones de larga data al mismo tiempo.
La especificación
TL;DR; Los semánticos de iteración de for-in son imprecisos por razones de rendimiento.
Cuando miramos el texto de especificaciones de for-in, está escrito de una manera sorprendentemente imprecisa, lo cual es observable en diferentes implementaciones. Veamos un ejemplo al iterar sobre un objeto Proxy con las trampas apropiadas configuradas.
const proxy = new Proxy({ a: 1, b: 1},
{
getPrototypeOf(target) {
console.log('getPrototypeOf');
return null;
},
ownKeys(target) {
console.log('ownKeys');
return Reflect.ownKeys(target);
},
getOwnPropertyDescriptor(target, prop) {
console.log('getOwnPropertyDescriptor name=' + prop);
return Reflect.getOwnPropertyDescriptor(target, prop);
}
});
En V8/Chrome 56 obtienes el siguiente resultado:
ownKeys
getPrototypeOf
getOwnPropertyDescriptor name=a
a
getOwnPropertyDescriptor name=b
b
En contraste, obtienes un orden diferente de declaraciones para el mismo fragmento en Firefox 51:
ownKeys
getOwnPropertyDescriptor name=a
getOwnPropertyDescriptor name=b
getPrototypeOf
a
b
Ambos navegadores respetan la especificación, pero por una vez la especificación no exige un orden explícito de instrucciones. Para entender estos vacíos correctamente, echemos un vistazo al texto de la especificación:
EnumerateObjectProperties ( O ) Cuando se llama a la operación abstracta EnumerateObjectProperties con el argumento O, se realizan los siguientes pasos:
- Afirmar: Type(O) es Object.
- Devolver un objeto Iterator (25.1.1.2) cuyo método next itere sobre todas las claves con valor String de las propiedades enumerables de O. El objeto del iterador nunca es accesible directamente desde el código ECMAScript. La mecánica y el orden de enumerar las propiedades no están especificados pero deben cumplir las reglas especificadas a continuación.
Ahora, generalmente las instrucciones de especificación son precisas en los pasos exactos que se requieren. Pero en este caso se refieren a una lista simple de prosa, e incluso el orden de ejecución queda a los implementadores. Por lo general, la razón de esto es que tales partes de la especificación fueron escritas después del hecho cuando los motores de JavaScript ya tenían diferentes implementaciones. La especificación intenta atar los cabos sueltos proporcionando las siguientes instrucciones:
- Los métodos throw y return del iterador son null y nunca se invocan.
- El método next del iterador procesa las propiedades del objeto para determinar si la clave de la propiedad debe devolverse como un valor del iterador.
- Las claves de propiedad devueltas no incluyen claves que sean símbolos.
- Las propiedades del objeto objetivo pueden eliminarse durante la enumeración.
- Se ignora una propiedad que se elimina antes de que el método next del iterador la procese. Si se agregan nuevas propiedades al objeto objetivo durante la enumeración, no se garantiza que las propiedades recién agregadas se procesen en la enumeración activa.
- Un nombre de propiedad será devuelto por el método next del iterador como máximo una vez en cualquier enumeración.
- La enumeración de las propiedades del objeto objetivo incluye la enumeración de las propiedades de su prototipo, y el prototipo del prototipo, y así sucesivamente, recursivamente; pero una propiedad de un prototipo no se procesa si tiene el mismo nombre que una propiedad que ya ha sido procesada por el método next del iterador.
- Los valores de los atributos
[[Enumerable]]no se consideran al determinar si una propiedad de un objeto prototipo ya ha sido procesada. - Los nombres de las propiedades enumerables de los objetos prototipo deben obtenerse invocando EnumerateObjectProperties pasando el objeto prototipo como argumento.
- EnumerateObjectProperties debe obtener las claves de propiedad propias del objeto objetivo llamando a su método interno
[[OwnPropertyKeys]].
Estos pasos parecen tediosos, sin embargo, la especificación también contiene una implementación de ejemplo que es explícita y mucho más legible:
function* EnumerateObjectProperties(obj) {
const visited = new Set();
for (const key of Reflect.ownKeys(obj)) {
if (typeof key === 'symbol') continue;
const desc = Reflect.getOwnPropertyDescriptor(obj, key);
if (desc && !visited.has(key)) {
visited.add(key);
if (desc.enumerable) yield key;
}
}
const proto = Reflect.getPrototypeOf(obj);
if (proto === null) return;
for (const protoKey of EnumerateObjectProperties(proto)) {
if (!visited.has(protoKey)) yield protoKey;
}
}
Ahora que has llegado hasta aquí, tal vez hayas notado en el ejemplo anterior que V8 no sigue exactamente la implementación de ejemplo de la especificación. Para empezar, el generador for-in del ejemplo funciona de manera incremental, mientras que V8 recopila todas las claves de antemano, principalmente por razones de rendimiento. Esto es perfectamente aceptable, y de hecho, el texto de la especificación establece explícitamente que el orden de las operaciones A - J no está definido. No obstante, como descubrirás más adelante en esta publicación, hay algunos casos excepcionales en los que V8 no respetó completamente la especificación hasta el año 2016.
La caché de enum
La implementación ejemplar del generador for-in sigue un patrón incremental de recolección y generación de claves. En V8, las claves de propiedad se recopilan en un primer paso y solo luego se utilizan en la fase de iteración. Para V8 esto facilita algunas cosas. Para entender por qué, necesitamos analizar el modelo de objetos.
Un objeto simple como {a:'value a', b:'value b', c:'value c'} puede tener varias representaciones internas en V8 como mostraremos en una publicación detallada de seguimiento sobre propiedades. Esto significa que, dependiendo del tipo de propiedades que tengamos —en el objeto, rápidas o lentas—, los nombres de las propiedades reales se almacenan en diferentes lugares. Esto hace que recopilar claves enumerables sea una tarea no trivial.
V8 realiza un seguimiento de la estructura de los objetos mediante una clase oculta o un llamado Map. Los objetos con el mismo Map tienen la misma estructura. Además, cada Map tiene una estructura de datos compartida, el descriptor array, que contiene detalles sobre cada propiedad, como dónde se almacenan las propiedades en el objeto, el nombre de la propiedad y detalles como la enumerabilidad.
Supongamos por un momento que nuestro objeto de JavaScript ha alcanzado su forma final y no se agregarán ni eliminarán más propiedades. En este caso podríamos usar el descriptor array como fuente para las claves. Esto funciona si solo hay propiedades enumerables. Para evitar la sobrecarga de filtrar propiedades no enumerables cada vez, V8 utiliza una caché de enumeración separada accesible a través del descriptor array del Map.

Dado que V8 espera que los objetos tipo diccionario lentos cambien con frecuencia (es decir, mediante la adición y eliminación de propiedades), no hay descriptor array para objetos lentos con propiedades tipo diccionario. Por lo tanto, V8 no proporciona una caché de enumeración para propiedades lentas. Suposiciones similares se aplican a propiedades indexadas, y como tal, también se excluyen de la caché de enumeración.
Resumamos los hechos importantes:
- Los mapas se usan para realizar un seguimiento de las formas de los objetos.
- Los arrays de descriptores almacenan información sobre las propiedades (nombre, configurabilidad, visibilidad).
- Los arrays de descriptores pueden ser compartidos entre mapas.
- Cada array de descriptores puede tener una caché de enumeración que lista solo las claves nombradas enumerables, no los nombres de propiedad indexados.
La mecánica de for-in
Ahora sabes parcialmente cómo funcionan los mapas y cómo la caché de enumeración se relaciona con el array de descriptores. V8 ejecuta JavaScript mediante Ignition, un intérprete de bytecode, y TurboFan, el compilador optimizador, ambos manejan for-in de manera similar. Para mayor claridad utilizaremos un estilo pseudo-C++ para explicar cómo se implementa internamente el for-in:
// Preparación para For-In:
FixedArray* keys = nullptr;
Map* original_map = object->map();
if (original_map->HasEnumCache()) {
if (object->HasNoElements()) {
keys = original_map->GetCachedEnumKeys();
} else {
keys = object->GetCachedEnumKeysWithElements();
}
} else {
keys = object->GetEnumKeys();
}
// Cuerpo del For-In:
for (size_t i = 0; i < keys->length(); i++) {
// Siguiente en For-In:
String* key = keys[i];
if (!object->HasProperty(key) continue;
EVALUATE_FOR_IN_BODY();
}
El for-in se puede separar en tres pasos principales:
- Preparar las claves para iterar sobre ellas,
- Obtener la siguiente clave,
- Evaluar el cuerpo del
for-in.
El paso "prepare" es el más complejo de estos tres y aquí es donde entra en juego el EnumCache. En el ejemplo anterior puedes ver que V8 utiliza directamente el EnumCache si existe y si no hay elementos (propiedades con índice entero) en el objeto (y su prototipo). En el caso de que haya nombres de propiedades indexadas, V8 salta a una función de tiempo de ejecución implementada en C++ que los antepone al EnumCache existente, como se ilustra en el siguiente ejemplo:
FixedArray* JSObject::GetCachedEnumKeysWithElements() {
FixedArray* keys = object->map()->GetCachedEnumKeys();
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* Map::GetCachedEnumKeys() {
// Obtén las claves de las propiedades enumerables de un EnumCache posiblemente compartido
FixedArray* keys_cache = descriptors()->enum_cache()->keys_cache();
if (enum_length() == keys_cache->length()) return keys_cache;
return keys_cache->CopyUpTo(enum_length());
}
FixedArray* FastElementsAccessor::PrependElementIndices(
JSObject* object, FixedArray* property_keys) {
Assert(object->HasFastElements());
FixedArray* elements = object->elements();
int nof_indices = CountElements(elements)
FixedArray* result = FixedArray::Allocate(property_keys->length() + nof_indices);
int insertion_index = 0;
for (int i = 0; i < elements->length(); i++) {
if (!HasElement(elements, i)) continue;
result[insertion_index++] = String::FromInt(i);
}
// Insertar claves de propiedades al final.
property_keys->CopyTo(result, nof_indices - 1);
return result;
}
En el caso de que no se encontrara un EnumCache existente, nuevamente saltamos a C++ y seguimos los pasos de especificación presentados inicialmente:
FixedArray* JSObject::GetEnumKeys() {
// Obtén las claves enum del receptor.
FixedArray* keys = this->GetOwnEnumKeys();
// Recorre la cadena del prototipo.
for (JSObject* object : GetPrototypeIterator()) {
// Añadir claves no duplicadas a la lista.
keys = keys->UnionOfKeys(object->GetOwnEnumKeys());
}
return keys;
}
FixedArray* JSObject::GetOwnEnumKeys() {
FixedArray* keys;
if (this->HasEnumCache()) {
keys = this->map()->GetCachedEnumKeys();
} else {
keys = this->GetEnumPropertyKeys();
}
if (this->HasFastProperties()) this->map()->FillEnumCache(keys);
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* FixedArray::UnionOfKeys(FixedArray* other) {
int length = this->length();
FixedArray* result = FixedArray::Allocate(length + other->length());
this->CopyTo(result, 0);
int insertion_index = length;
for (int i = 0; i < other->length(); i++) {
String* key = other->get(i);
if (other->IndexOf(key) == -1) {
result->set(insertion_index, key);
insertion_index++;
}
}
result->Shrink(insertion_index);
return result;
}
Este código C++ simplificado corresponde a la implementación en V8 hasta principios de 2016 cuando comenzamos a analizar el método UnionOfKeys. Si observas detenidamente, notarás que utilizamos un algoritmo ingenuo para excluir duplicados de la lista, lo cual podría generar un mal rendimiento si tenemos muchas claves en la cadena de prototipos. Así fue como decidimos seguir las optimizaciones en la sección siguiente.
Problemas con for-in
Como ya insinuamos en la sección anterior, el método UnionOfKeys tiene un peor rendimiento en el peor caso. Se basaba en la suposición válida de que la mayoría de los objetos tienen propiedades rápidas y por lo tanto se beneficiarán de un EnumCache. La segunda suposición es que solo hay pocas propiedades enumerables en la cadena de prototipos, limitando el tiempo dedicado a encontrar duplicados. Sin embargo, si el objeto tiene propiedades de diccionario lentas y muchas claves en la cadena de prototipos, UnionOfKeys se convierte en un cuello de botella ya que tenemos que recolectar los nombres de las propiedades enumerables cada vez que ingresamos a for-in.
Además de los problemas de rendimiento, había otro problema con el algoritmo existente en que no cumplía con la especificación. V8 mostró el siguiente ejemplo de manera incorrecta durante muchos años:
var o = {
__proto__ : {b: 3},
a: 1
};
Object.defineProperty(o, 'b', {});
for (var k in o) console.log(k);
Salida:
a
b
Quizás de manera contraproducente, esto debería imprimir solo a en lugar de a y b. Si recuerdas el texto de especificación al principio de este artículo, los pasos G y J implican que las propiedades no enumerables en el receptor ocultan las propiedades en la cadena de prototipos.
Para hacerlo aún más complicado, ES6 introdujo el objeto proxy. Esto rompió muchas suposiciones del código de V8. Para implementar for-in de manera conforme con la especificación, tenemos que activar las siguientes 5 de un total de 13 diferentes trampas de proxy.
| Método interno | Método del manejador |
|---|---|
[[GetPrototypeOf]] | getPrototypeOf |
[[GetOwnProperty]] | getOwnPropertyDescriptor |
[[HasProperty]] | has |
[[Get]] | get |
[[OwnPropertyKeys]] | ownKeys |
Esto requirió una versión duplicada del código original GetEnumKeys, que intentó seguir más de cerca el ejemplo de implementación del estándar. Los proxies de ES6 y la falta de manejo de propiedades que ocultan fueron la motivación principal para que refactorizáramos la forma en que extraemos todas las claves para for-in a principios de 2016.
El KeyAccumulator
Introdujimos una clase auxiliar separada, el KeyAccumulator, que se encargaba de las complejidades de recolectar las claves para for-in. Con el crecimiento del estándar ES6, nuevas funciones como Object.keys o Reflect.ownKeys requerían su propia versión ligeramente modificada para recolectar claves. Al tener un único lugar configurable, pudimos mejorar el rendimiento de for-in y evitar código duplicado.
El KeyAccumulator consta de una parte rápida que solo admite un conjunto limitado de acciones pero puede completarlas muy eficientemente. El acumulador lento admite todos los casos complejos, como los proxies de ES6.

Para filtrar adecuadamente las propiedades que ocultan, tenemos que mantener una lista separada de propiedades no enumerables que hemos visto hasta ahora. Por razones de rendimiento, solo hacemos esto después de determinar que hay propiedades enumerables en la cadena de prototipos de un objeto.
Mejoras de rendimiento
Con el KeyAccumulator en su lugar, algunos patrones adicionales se volvieron factibles para optimizar. El primero fue evitar el bucle anidado del método original UnionOfKeys que causaba casos extremos lentos. En un segundo paso, realizamos verificaciones previas más detalladas para aprovechar las EnumCaches existentes y evitar pasos de copia innecesarios.
Para ilustrar que la implementación que cumple con las especificaciones es más rápida, echemos un vistazo a los siguientes cuatro objetos diferentes:
var fastProperties = {
__proto__ : null,
'property 1': 1,
…
'property 10': n
};
var fastPropertiesWithPrototype = {
'property 1': 1,
…
'property 10': n
};
var slowProperties = {
__proto__ : null,
'dummy': null,
'property 1': 1,
…
'property 10': n
};
delete slowProperties['dummy']
var elements = {
__proto__: null,
'1': 1,
…
'10': n
}
- El objeto
fastPropertiestiene propiedades estándar rápidas. - El objeto
fastPropertiesWithPrototypetiene propiedades adicionales no enumerables en la cadena de prototipos utilizando elObject.prototype. - El objeto
slowPropertiestiene propiedades lentas de tipo diccionario. - El objeto
elementssolo tiene propiedades indexadas.
El siguiente gráfico compara el rendimiento original de ejecutar un bucle for-in un millón de veces en un bucle ajustado sin la ayuda de nuestro compilador optimizador.
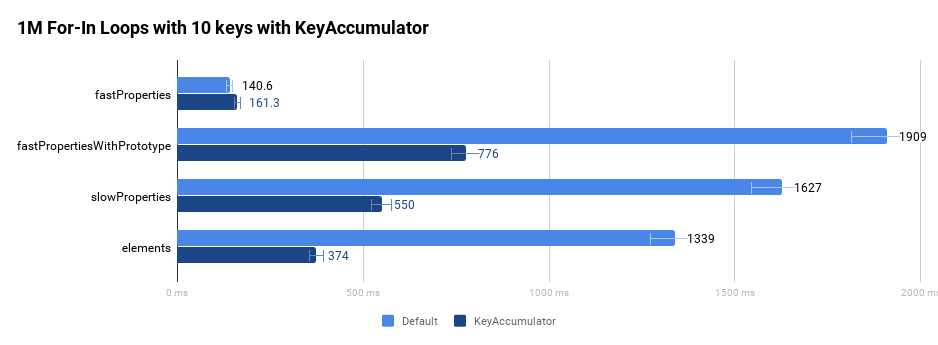
Como hemos destacado en la introducción, estas mejoras se hicieron muy visibles en Wikipedia y Facebook en particular.
Además de las mejoras iniciales disponibles en Chrome 51, un segundo ajuste de rendimiento produjo otra mejora significativa. El siguiente gráfico muestra nuestros datos de seguimiento del tiempo total dedicado a la ejecución de scripts durante el inicio en una página de Facebook. ¡El rango seleccionado alrededor de la revisión V8 37937 corresponde a una mejora adicional del 4% en el rendimiento!

Para resaltar la importancia de mejorar for-in, podemos confiar en los datos de una herramienta que construimos en 2016 que nos permite extraer mediciones de V8 en un conjunto de sitios web. La siguiente tabla muestra el tiempo relativo que se dedica a puntos de entrada de V8 en C++ (funciones en tiempo de ejecución y soluciones integradas) para Chrome 49 en un conjunto de aproximadamente 25 sitios web representativos del mundo real.
| Posición | Nombre | Tiempo total |
|---|---|---|
| 1 | CreateObjectLiteral | 1.10% |
| 2 | NewObject | 0.90% |
| 3 | KeyedGetProperty | 0.70% |
| 4 | GetProperty | 0.60% |
| 5 | ForInEnumerate | 0.60% |
| 6 | SetProperty | 0.50% |
| 7 | StringReplaceGlobalRegExpWithString | 0.30% |
| 8 | HandleApiCallConstruct | 0.30% |
| 9 | RegExpExec | 0.30% |
| 10 | ObjectProtoToString | 0.30% |
| 11 | ArrayPush | 0.20% |
| 12 | NewClosure | 0.20% |
| 13 | NewClosure_Tenured | 0.20% |
| 14 | ObjectDefineProperty | 0.20% |
| 15 | HasProperty | 0.20% |
| 16 | StringSplit | 0.20% |
| 17 | ForInFilter | 0.10% |