Boucle `for`-`in` rapide dans V8
for-in est une fonctionnalité de langage largement utilisée présente dans de nombreux frameworks. Malgré son omniprésence, elle est l'une des constructions de langage les plus obscures du point de vue de l'implémentation. V8 a déployé de grands efforts pour rendre cette fonction aussi rapide que possible. Au cours de l'année passée, for-in est devenu entièrement conforme à la spécification et jusqu'à 3 fois plus rapide, selon le contexte.
De nombreux sites populaires dépendent fortement de for-in et bénéficient de son optimisation. Par exemple, au début de l'année 2016, Facebook consacrait environ 7 % de son temps total de JavaScript lors du démarrage à l'implémentation de for-in lui-même. Sur Wikipedia, ce chiffre était encore plus élevé, autour de 8 %. En améliorant les performances de certains cas lents, Chrome 51 a considérablement amélioré les performances sur ces deux sites Web :


Wikipedia et Facebook ont tous deux amélioré leur temps total de script de 4 % grâce à diverses améliorations de for-in. Notez que pendant la même période, le reste de V8 est également devenu plus rapide, ce qui a donné une amélioration globale de plus de 4 % pour les scripts.
Dans le reste de cet article de blog, nous expliquerons comment nous avons réussi à accélérer cette fonctionnalité de base du langage et à corriger une violation de spécification de longue date en même temps.
La spécification
TL;DR; Les sémantiques de l'itération for-in sont imprécises pour des raisons de performance.
Lorsque nous examinons le texte de la spécification de for-in, il est rédigé de manière étonnamment floue, ce qui est observable dans différentes implémentations. Regardons un exemple en itérant sur un objet Proxy avec les bons pièges configurés.
const proxy = new Proxy({ a: 1, b: 1},
{
getPrototypeOf(target) {
console.log('getPrototypeOf');
return null;
},
ownKeys(target) {
console.log('ownKeys');
return Reflect.ownKeys(target);
},
getOwnPropertyDescriptor(target, prop) {
console.log('getOwnPropertyDescriptor name=' + prop);
return Reflect.getOwnPropertyDescriptor(target, prop);
}
});
Dans V8/Chrome 56, vous obtenez la sortie suivante :
ownKeys
getPrototypeOf
getOwnPropertyDescriptor name=a
a
getOwnPropertyDescriptor name=b
b
En revanche, vous obtenez un ordre différent de déclarations pour le même extrait de code dans Firefox 51 :
ownKeys
getOwnPropertyDescriptor name=a
getOwnPropertyDescriptor name=b
getPrototypeOf
a
b
Les deux navigateurs respectent la spécification, mais pour une fois elle n'impose pas un ordre explicite des instructions. Pour bien comprendre ces lacunes, examinons le texte de la spécification :
EnumerateObjectProperties ( O ) Lorsque l'opération abstraite EnumerateObjectProperties est appelée avec l'argument O, les étapes suivantes sont suivies :
- Assertion : Type(O) est Object.
- Retourne un objet Iterator (25.1.1.2) dont la méthode next itère sur toutes les clés de propriétés énumérables de O de type String. L'objet itérateur n'est jamais directement accessible au code ECMAScript. Les mécanismes et l'ordre d'énumération des propriétés ne sont pas spécifiés mais doivent se conformer aux règles précisées ci-dessous.
Maintenant, généralement les instructions de la spécification sont précises sur les étapes exactes requises. Mais dans ce cas, elles se réfèrent à une simple liste de texte en prose, et même l'ordre d'exécution est laissé aux implémenteurs. Habituellement, la raison en est que ces parties de la spécification ont été écrites après coup lorsque les moteurs JavaScript avaient déjà des implémentations différentes. La spécification tente de lier les points flous en fournissant les instructions suivantes :
- Les méthodes throw et return de l'itérateur sont nulles et ne sont jamais invoquées.
- La méthode next de l'itérateur traite les propriétés de l'objet pour déterminer si la clé de propriété doit être retournée comme une valeur de l'itérateur.
- Les clés de propriété retournées ne comprennent pas les clés qui sont des Symboles.
- Les propriétés de l'objet cible peuvent être supprimées pendant l'énumération.
- Une propriété supprimée avant d'être traitée par la méthode next de l'itérateur est ignorée. Si de nouvelles propriétés sont ajoutées à l'objet cible pendant l'énumération, les nouvelles propriétés ajoutées ne sont pas garanties d'être traitées dans l'énumération active.
- Un nom de propriété sera retourné par la méthode next de l'itérateur au maximum une fois lors d'une énumération.
- L'énumération des propriétés de l'objet cible comprend l'énumération des propriétés de son prototype, et du prototype de ce prototype, et ainsi de suite, de manière récursive ; mais une propriété d'un prototype n'est pas traitée si elle porte le même nom qu'une propriété qui a déjà été traitée par la méthode next de l'itérateur.
- Les valeurs des attributs
[[Enumerable]]ne sont pas prises en compte lors de la détermination si une propriété d'un objet prototype a déjà été traitée. - Les noms des propriétés énumérables des objets prototypes doivent être obtenus en invoquant EnumerateObjectProperties en passant l'objet prototype comme argument.
- EnumerateObjectProperties doit obtenir les clés des propriétés propres de l'objet cible en appelant sa méthode interne
[[OwnPropertyKeys]].
Ces étapes semblent fastidieuses, mais la spécification contient également une mise en œuvre exemple qui est explicite et beaucoup plus lisible :
function* EnumerateObjectProperties(obj) {
const visited = new Set();
for (const key of Reflect.ownKeys(obj)) {
if (typeof key === 'symbol') continue;
const desc = Reflect.getOwnPropertyDescriptor(obj, key);
if (desc && !visited.has(key)) {
visited.add(key);
if (desc.enumerable) yield key;
}
}
const proto = Reflect.getPrototypeOf(obj);
if (proto === null) return;
for (const protoKey of EnumerateObjectProperties(proto)) {
if (!visited.has(protoKey)) yield protoKey;
}
}
Maintenant que vous êtes arrivé jusqu'ici, vous avez peut-être remarqué dans l'exemple précédent que V8 ne suit pas exactement la mise en œuvre exemple de la spécification. Pour commencer, l'exemple de générateur for-in fonctionne de manière incrémentale, tandis que V8 collecte toutes les clés à l'avance - principalement pour des raisons de performance. Cela est parfaitement acceptable, et en fait le texte de la spécification indique explicitement que l'ordre des opérations A - J n'est pas défini. Néanmoins, comme vous le découvrirez plus tard dans cet article, il existe certains cas limites où V8 n'a pas respecté pleinement la spécification avant 2016.
Le cache d'énumération
La mise en œuvre exemple du générateur for-in suit un modèle incrémental de collecte et de génération de clés. Dans V8, les clés des propriétés sont collectées dans une première étape avant d'être utilisées dans la phase d'itération. Cela simplifie quelques aspects pour V8. Pour comprendre pourquoi, nous devons examiner le modèle objet.
Un objet simple tel que {a:'value a', b:'value b', c:'value c'} peut avoir diverses représentations internes dans V8, comme nous le démontrerons dans un article détaillé de suivi sur les propriétés. Cela signifie que selon le type de propriétés que nous avons — dans l'objet, rapides ou lentes — les noms de propriétés réels sont stockés dans différents emplacements. Cela rend la collecte des clés énumérables une tâche complexe.
V8 suit la structure de l'objet au moyen d'une classe cachée ou d'une Map dite. Les objets ayant la même Map ont la même structure. De plus, chaque Map possède une structure de données partagée, le tableau des descripteurs, qui contient des détails sur chaque propriété, tels que l'endroit où les propriétés sont stockées sur l'objet, le nom de la propriété et des détails comme l'énumérabilité.
Supposons un instant que notre objet JavaScript ait atteint sa forme finale et qu'aucune autre propriété ne sera ajoutée ou supprimée. Dans ce cas, nous pourrions utiliser le tableau des descripteurs comme source pour les clés. Cela fonctionne s'il n'y a que des propriétés énumérables. Pour éviter la surcharge de filtration des propriétés non énumérables chaque fois, V8 utilise un EnumCache séparé accessible via le tableau des descripteurs de la Map.

Étant donné que V8 suppose que les objets dictionnaires lents changent fréquemment (c'est-à-dire par l'ajout et la suppression de propriétés), il n'y a pas de tableau des descripteurs pour les objets lents avec des propriétés de dictionnaire. Ainsi, V8 ne fournit pas d'EnumCache pour les propriétés lentes. Des hypothèses similaires s'appliquent aux propriétés indexées, et elles sont donc également exclues de l'EnumCache.
Résumons les faits importants :
- Les Maps sont utilisées pour suivre les formes des objets.
- Les tableaux des descripteurs stockent des informations sur les propriétés (nom, configurabilité, visibilité).
- Les tableaux des descripteurs peuvent être partagés entre Maps.
- Chaque tableau des descripteurs peut avoir un EnumCache répertoriant uniquement les clés nommées énumérables, pas les noms de propriétés indexées.
La mécanique de for-in
Maintenant, vous connaissez partiellement le fonctionnement des Maps et la relation de l'EnumCache avec le tableau des descripteurs. V8 exécute JavaScript via Ignition, un interpréteur de bytecode, et TurboFan, le compilateur optimisant, qui gèrent tous les deux for-in de manière similaire. Pour simplifier, nous utiliserons un pseudo-style C++ pour expliquer comment for-in est implémenté en interne :
// Préparation pour For-In :
FixedArray* keys = nullptr;
Map* original_map = object->map();
if (original_map->HasEnumCache()) {
if (object->HasNoElements()) {
keys = original_map->GetCachedEnumKeys();
} else {
keys = object->GetCachedEnumKeysWithElements();
}
} else {
keys = object->GetEnumKeys();
}
// Corps de For-In :
for (size_t i = 0; i < keys->length(); i++) {
// Prochaine étape de For-In :
String* key = keys[i];
if (!object->HasProperty(key) continue;
EVALUATE_FOR_IN_BODY();
}
For-in peut être divisé en trois étapes principales :
- Préparer les clés à parcourir,
- Obtenir la clé suivante,
- Évaluer le corps de
for-in.
L'étape "préparer" est la plus complexe des trois et c'est ici que le EnumCache entre en jeu. Dans l'exemple ci-dessus, vous pouvez voir que V8 utilise directement le EnumCache s'il existe et s'il n'y a pas d'éléments (propriétés indexées par entier) sur l'objet (et son prototype). Dans le cas où il existe des noms de propriétés indexées, V8 saute vers une fonction runtime implémentée en C++ qui les ajoute au cache d'énumération existant, comme illustré par l'exemple suivant :
FixedArray* JSObject::GetCachedEnumKeysWithElements() {
FixedArray* keys = object->map()->GetCachedEnumKeys();
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* Map::GetCachedEnumKeys() {
// Obtenir les clés de propriété énumérables à partir d'un cache d'énumération potentiellement partagé
FixedArray* keys_cache = descriptors()->enum_cache()->keys_cache();
if (enum_length() == keys_cache->length()) return keys_cache;
return keys_cache->CopyUpTo(enum_length());
}
FixedArray* FastElementsAccessor::PrependElementIndices(
JSObject* object, FixedArray* property_keys) {
Assert(object->HasFastElements());
FixedArray* elements = object->elements();
int nof_indices = CountElements(elements)
FixedArray* result = FixedArray::Allocate(property_keys->length() + nof_indices);
int insertion_index = 0;
for (int i = 0; i < elements->length(); i++) {
if (!HasElement(elements, i)) continue;
result[insertion_index++] = String::FromInt(i);
}
// Insérer les clés de propriété à la fin.
property_keys->CopyTo(result, nof_indices - 1);
return result;
}
Dans le cas où aucun EnumCache existant n'est trouvé, nous sautons à nouveau vers C++ et suivons les étapes du spéc initialement présenté :
FixedArray* JSObject::GetEnumKeys() {
// Obtenir les clés d'énumération du récepteur.
FixedArray* keys = this->GetOwnEnumKeys();
// Parcourir la chaîne de prototypes.
for (JSObject* object : GetPrototypeIterator()) {
// Ajouter les clés non dupliquées à la liste.
keys = keys->UnionOfKeys(object->GetOwnEnumKeys());
}
return keys;
}
FixedArray* JSObject::GetOwnEnumKeys() {
FixedArray* keys;
if (this->HasEnumCache()) {
keys = this->map()->GetCachedEnumKeys();
} else {
keys = this->GetEnumPropertyKeys();
}
if (this->HasFastProperties()) this->map()->FillEnumCache(keys);
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* FixedArray::UnionOfKeys(FixedArray* other) {
int length = this->length();
FixedArray* result = FixedArray::Allocate(length + other->length());
this->CopyTo(result, 0);
int insertion_index = length;
for (int i = 0; i < other->length(); i++) {
String* key = other->get(i);
if (other->IndexOf(key) == -1) {
result->set(insertion_index, key);
insertion_index++;
}
}
result->Shrink(insertion_index);
return result;
}
Ce code C++ simplifié correspond à l'implémentation dans V8 jusqu'au début de 2016, lorsque nous avons commencé à examiner la méthode UnionOfKeys. Si vous regardez de près, vous remarquez que nous avons utilisé un algorithme naïf pour exclure les doublons de la liste, ce qui peut entraîner de mauvaises performances si nous avons de nombreuses clés dans la chaîne de prototypes. C'est ainsi que nous avons décidé de poursuivre les optimisations dans la section suivante.
Problèmes avec for-in
Comme nous l'avons déjà mentionné dans la section précédente, la méthode UnionOfKeys a de mauvaises performances au pire des cas. Elle était basée sur l'hypothèse valide que la plupart des objets ont des propriétés rapides et bénéficieront donc d'un EnumCache. La deuxième hypothèse est qu'il n'y a que peu de propriétés énumérables sur la chaîne de prototypes, limitant le temps consacré à la recherche de doublons. Cependant, si l'objet a des propriétés de dictionnaire lentes et de nombreuses clés sur la chaîne de prototypes, UnionOfKeys devient un goulet d'étranglement car nous devons collecter les noms des propriétés énumérables chaque fois que nous entrons dans for-in.
Outre les problèmes de performance, il y avait un autre problème avec l'algorithme existant en ce sens qu'il ne respectait pas les spécifications. V8 a mal interprété l'exemple suivant pendant de nombreuses années :
var o = {
__proto__ : {b: 3},
a: 1
};
Object.defineProperty(o, 'b', {});
for (var k in o) console.log(k);
Résultat affiché :
a
b
Peut-être contre-intuitivement, cela ne devrait imprimer que a au lieu de a et b. Si vous vous souvenez du texte des spécifications au début de cet article, les étapes G et J impliquent que les propriétés non énumérables sur le récepteur suppriment les propriétés sur la chaîne de prototypes.
Pour compliquer les choses, ES6 a introduit l'objet proxy. Cela a brisé beaucoup d'hypothèses du code V8. Pour implémenter for-in d'une manière conforme aux spécifications, nous devons déclencher les 5 pièges proxy suivants sur un total de 13.
| Méthode interne | Méthode du gestionnaire |
|---|---|
[[GetPrototypeOf]] | getPrototypeOf |
[[GetOwnProperty]] | getOwnPropertyDescriptor |
[[HasProperty]] | has |
[[Get]] | get |
[[OwnPropertyKeys]] | ownKeys |
Cela nécessitait une version dupliquée du code original GetEnumKeys qui essayait de suivre l'exemple d'implémentation de la spécification de manière plus stricte. Les proxies ES6 et l'absence de gestion des propriétés masquantes ont été les principales motivations pour refactoriser la manière dont nous extrayons toutes les clés pour for-in au début de 2016.
Le KeyAccumulator
Nous avons introduit une classe utilitaire distincte, le KeyAccumulator, qui gère les complexités de la collecte des clés pour for-in. Avec l'évolution de la spécification ES6, de nouvelles fonctionnalités comme Object.keys ou Reflect.ownKeys nécessitaient leur propre version légèrement modifiée de collecte des clés. En ayant un point unique configurable, nous avons pu améliorer la performance de for-in et éviter la duplication de code.
Le KeyAccumulator se compose d'une partie rapide qui ne prend en charge qu'un ensemble limité d'actions mais peut les exécuter très efficacement. L'accumulateur lent prend en charge tous les cas complexes, comme les proxies ES6.

Afin de filtrer correctement les propriétés masquantes, nous devons maintenir une liste distincte des propriétés non énumérables que nous avons rencontrées jusqu'à présent. Pour des raisons de performances, nous ne faisons cela qu'après avoir constaté qu'il existe des propriétés énumérables dans la chaîne prototype d'un objet.
Améliorations de performance
Avec le KeyAccumulator en place, il a été possible d'optimiser quelques schémas supplémentaires. Le premier a été d'éviter la boucle imbriquée de la méthode originale UnionOfKeys qui causait des cas limites lents. Dans un second temps, nous avons effectué des pré-vérifications plus détaillées pour utiliser les EnumCaches existants et éviter les étapes de copie inutiles.
Pour illustrer que l'implémentation conforme à la spécification est plus rapide, examinons les quatre objets suivants :
var fastProperties = {
__proto__ : null,
'property 1': 1,
…
'property 10': n
};
var fastPropertiesWithPrototype = {
'property 1': 1,
…
'property 10': n
};
var slowProperties = {
__proto__ : null,
'dummy': null,
'property 1': 1,
…
'property 10': n
};
delete slowProperties['dummy']
var elements = {
__proto__: null,
'1': 1,
…
'10': n
}
- L'objet
fastPropertiesa des propriétés rapides standard. - L'objet
fastPropertiesWithPrototypea des propriétés non énumérables supplémentaires dans la chaîne prototype en utilisantObject.prototype. - L'objet
slowPropertiesa des propriétés lentes de type dictionnaire. - L'objet
elementsa uniquement des propriétés indexées.
Le graphique suivant compare la performance originale de l'exécution d'une boucle for-in un million de fois dans une boucle serrée sans l'aide de notre compilateur d'optimisation.
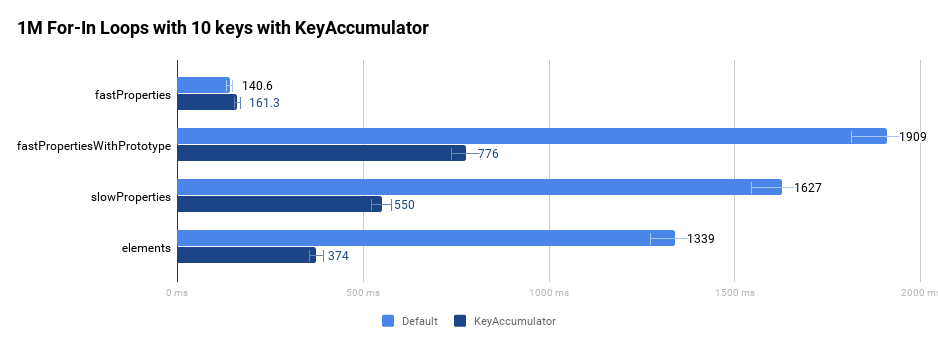
Comme nous l'avons souligné dans l'introduction, ces améliorations sont devenues très visibles notamment sur Wikipédia et Facebook.
Outre les améliorations initiales disponibles dans Chrome 51, un second ajustement de performance a permis une autre amélioration significative. Le graphique suivant montre nos données de suivi sur le temps total passé dans le script lors du démarrage d'une page Facebook. La plage sélectionnée autour de la révision 37937 de V8 correspond à une amélioration supplémentaire de 4 % des performances !

Pour souligner l'importance d'améliorer for-in, nous pouvons nous appuyer sur les données d'un outil que nous avons construit en 2016 qui nous permet d'extraire des mesures V8 sur un ensemble de sites Web. Le tableau suivant montre le temps relatif passé dans les points d'entrée V8 C++ (fonctions runtime et intégrées) pour Chrome 49 sur un ensemble d'environ 25 sites Web réels représentatifs.
| Position | Nom | Temps total |
|---|---|---|
| 1 | CreateObjectLiteral | 1.10% |
| 2 | NewObject | 0.90% |
| 3 | KeyedGetProperty | 0.70% |
| 4 | GetProperty | 0.60% |
| 5 | ForInEnumerate | 0.60% |
| 6 | SetProperty | 0.50% |
| 7 | StringReplaceGlobalRegExpWithString | 0.30% |
| 8 | HandleApiCallConstruct | 0.30% |
| 9 | RegExpExec | 0.30% |
| 10 | ObjectProtoToString | 0.30% |
| 11 | ArrayPush | 0.20% |
| 12 | NewClosure | 0.20% |
| 13 | NewClosure_Tenured | 0.20% |
| 14 | ObjectDefineProperty | 0.20% |
| 15 | HasProperty | 0.20% |
| 16 | StringSplit | 0.20% |
| 17 | ForInFilter | 0.10% |