Liftoff : un nouveau compilateur de base pour WebAssembly dans V8
V8 v6.9 inclut Liftoff, un nouveau compilateur de base pour WebAssembly. Liftoff est désormais activé par défaut sur les systèmes de bureau. Cet article détaille la motivation d'ajouter un autre niveau de compilation et décrit l’implémentation et les performances de Liftoff.

Depuis que WebAssembly a été lancé il y a plus d'un an, son adoption sur le web a connu une augmentation constante. De grandes applications ciblant WebAssembly ont commencé à apparaître. Par exemple, le benchmark ZenGarden d’Epic comprend un fichier binaire WebAssembly de 39,5 Mo, et AutoDesk est livré sous la forme d’un binaire de 36,8 Mo. Puisque le temps de compilation est essentiellement linéaire par rapport à la taille du binaire, ces applications mettent un temps considérable à se lancer. Sur de nombreuses machines, cela dépasse 30 secondes, ce qui ne procure pas une bonne expérience utilisateur.
Mais pourquoi faut-il autant de temps pour lancer une application WebAssembly, alors que des applications JS similaires démarrent beaucoup plus rapidement ? La raison est que WebAssembly promet de fournir des performances prédictibles, donc une fois l'application en cours d'exécution, vous pouvez être sûr de toujours atteindre vos objectifs de performance (par exemple, rendre 60 images par seconde, sans décalage ni artefacts audio…). Pour cela, le code WebAssembly est compilé à l'avance dans V8, afin d’éviter toute pause de compilation introduite par un compilateur à la volée qui pourrait entraîner un ralentissement visible dans l'application.
Le pipeline de compilation existant (TurboFan)
L'approche de V8 pour compiler WebAssembly repose sur TurboFan, le compilateur d’optimisation que nous avons conçu pour JavaScript et asm.js. TurboFan est un compilateur puissant avec une représentation intermédiaire (IR) basée sur un graphe, adaptée aux optimisations avancées telles que la réduction de puissance, l’inlining, le mouvement de code, la combinaison d’instructions, et une allocation sophistiquée des registres. La conception de TurboFan permet d’entrer dans le pipeline très tard, plus près du code machine, ce qui contourne de nombreuses étapes nécessaires pour prendre en charge la compilation JavaScript. Par conception, transformer le code WebAssembly en IR de TurboFan (y compris la construction SSA) en une seule passe directe est très efficace, en partie grâce au flux de contrôle structuré de WebAssembly. Cependant, l'aboutissement du processus de compilation consomme toujours beaucoup de temps et de mémoire.
Le nouveau pipeline de compilation (Liftoff)
L’objectif de Liftoff est de réduire le temps de démarrage des applications basées sur WebAssembly en générant du code aussi rapidement que possible. La qualité du code est secondaire, puisque le code fréquemment utilisé est de toute façon recompilé avec TurboFan. Liftoff évite le temps et la mémoire nécessaires pour construire une IR et génère du code machine en une seule passe sur le bytecode d’une fonction WebAssembly.

Dans le diagramme ci-dessus, il est évident que Liftoff devrait être capable de générer du code beaucoup plus rapidement que TurboFan, car le pipeline ne comporte que deux étapes. En fait, le décodage du corps de la fonction effectue une seule passe sur les bytes bruts WebAssembly et interagit avec l’étape suivante via des callbacks. Ainsi, la génération de code est effectuée pendant le décodage et la validation du corps de la fonction. Avec les API de streaming de WebAssembly, cela permet à V8 de compiler le code WebAssembly en code machine tout en téléchargeant via le réseau.
Génération de code dans Liftoff
Liftoff est un générateur de code simple et rapide. Il effectue un seul passage sur les codes opérationnels d'une fonction, générant du code pour chaque code opération, un à la fois. Pour des codes opération simples comme les opérations arithmétiques, cela correspond souvent à une seule instruction machine, mais cela peut être plus complexe pour d'autres opérations comme les appels de fonctions. Liftoff maintient des métadonnées sur la pile des opérandes afin de savoir où les entrées de chaque opération sont actuellement stockées. Cette pile virtuelle n'existe que pendant la compilation. Le contrôle de flux structuré et les règles de validation de WebAssembly garantissent que l’emplacement de ces entrées peut être déterminé statiquement. Ainsi, une pile d'exécution réelle sur laquelle les opérandes sont empilés ou dépilés n'est pas nécessaire. Pendant l’exécution, chaque valeur sur la pile virtuelle sera soit conservée dans un registre, soit transférée dans la trame de pile physique de la fonction. Pour les petites constantes entières (générées par i32.const), Liftoff enregistre uniquement la valeur de la constante dans la pile virtuelle et ne génère aucun code. Ce n'est que lorsque la constante est utilisée par une opération ultérieure qu'elle est émise ou combinée avec l'opération, par exemple en émettant directement une instruction addl <reg>, <const> sur x64. Cela évite de charger cette constante dans un registre, ce qui produit un meilleur code.
Parcourons une fonction très simple pour voir comment Liftoff génère du code pour celle-ci.

Cette fonction exemple prend deux paramètres et renvoie leur somme. Lorsque Liftoff décode les octets de cette fonction, il commence par initialiser son état interne pour les variables locales selon la convention d'appel des fonctions WebAssembly. Pour x64, la convention d'appel de V8 passe les deux paramètres dans les registres rax et rdx.
Pour les instructions get_local, Liftoff ne génère aucun code, mais met à jour son état interne pour refléter que ces valeurs de registre sont maintenant empilées sur la pile virtuelle. L'instruction i32.add dépile ensuite les deux registres et choisit un registre pour la valeur de résultat. Nous ne pouvons pas utiliser l'un des registres d'entrée pour le résultat, car les deux registres apparaissent encore sur la pile pour contenir les variables locales. Les écraser changerait la valeur retournée par une instruction get_local ultérieure. Ainsi, Liftoff choisit un registre libre, dans ce cas rcx, et produit la somme de rax et rdx dans ce registre. rcx est ensuite empilé sur la pile virtuelle.
Après l'instruction i32.add, le corps de la fonction est terminé, donc Liftoff doit assembler le retour de la fonction. Comme notre fonction exemple a une valeur de retour, la validation exige qu'il y ait exactement une valeur sur la pile virtuelle à la fin du corps de la fonction. Ainsi, Liftoff génère du code qui déplace la valeur de retour contenue dans rcx dans le registre de retour adéquat rax et revient ensuite de la fonction.
Pour simplifier, l'exemple ci-dessus ne contient aucun bloc (if, loop…) ou branchement. Les blocs dans WebAssembly introduisent des fusions de contrôle, car le code peut se ramifier vers n'importe quel bloc parent, et les blocs if peuvent être ignorés. Ces points de fusion peuvent être atteints à partir de différents états de pile. Cependant, le code suivant doit supposer un état de pile spécifique pour générer du code. Ainsi, Liftoff capture un instantané de l'état actuel de la pile virtuelle comme état qui sera supposé pour le code suivant le nouveau bloc (c'est-à-dire lorsque nous revenons au niveau de contrôle où nous nous trouvons actuellement). Le nouveau bloc continuera ensuite avec l'état actuellement actif, pouvant potentiellement changer où les valeurs de pile ou les variables locales sont stockées : certaines peuvent être transférées dans la pile ou contenues dans d'autres registres. Lors d'une branche vers un autre bloc ou de la fin d'un bloc (ce qui revient à une branche vers le bloc parent), Liftoff doit générer du code qui adapte l'état actuel à l'état attendu à ce point, de sorte que le code émis pour la cible vers laquelle nous nous ramifions trouve les bonnes valeurs là où il les attend. La validation garantit que la hauteur de la pile virtuelle actuelle correspond à la hauteur de l'état attendu, donc Liftoff a seulement besoin de générer du code pour réorganiser les valeurs entre les registres et/ou la trame de pile physique comme montré ci-dessous.
Prenons un exemple de cela.

L'exemple ci-dessus suppose une pile virtuelle avec deux valeurs sur la pile des opérandes. Avant de démarrer le nouveau bloc, la valeur en haut de la pile virtuelle est dépilée comme argument pour l'instruction if. La valeur restante de la pile doit être placée dans un autre registre, car elle ombrage actuellement le premier paramètre, mais en revenant à cet état, nous pourrions avoir besoin de conserver deux valeurs différentes pour la valeur de pile et le paramètre. Dans ce cas, Liftoff choisit de la dédupliquer dans le registre rcx. Cet état est ensuite capturé en instantané, et l'état actif est modifié à l'intérieur du bloc. À la fin du bloc, nous faisons implicitement une branche vers le bloc parent, donc nous fusionnons l'état actuel dans l'instantané en déplaçant le registre rbx dans rcx et en rechargeant le registre rdx à partir de la trame de pile.
Passer de Liftoff à TurboFan
Avec Liftoff et TurboFan, V8 dispose désormais de deux niveaux de compilation pour WebAssembly : Liftoff en tant que compilateur de base pour un démarrage rapide et TurboFan en tant que compilateur d'optimisation pour des performances maximales. Cela pose la question de savoir comment combiner les deux compilateurs pour offrir la meilleure expérience utilisateur globale.
Pour JavaScript, V8 utilise l'interpréteur Ignition et le compilateur TurboFan et applique une stratégie de montée dynamique des niveaux. Chaque fonction est d'abord exécutée dans Ignition, et si la fonction devient sollicitée, TurboFan la compile en code machine hautement optimisé. Une approche similaire pourrait également être utilisée pour Liftoff, mais les compromis sont légèrement différents ici :
- WebAssembly ne nécessite pas de retour d'informations sur les types pour générer du code rapide. Là où JavaScript bénéficie grandement de la collecte d'informations sur les types, WebAssembly est typé statiquement, donc le moteur peut générer du code optimisé immédiatement.
- Le code WebAssembly doit s'exécuter rapidement et de manière prévisible, sans une longue phase de préchauffage. Une des raisons pour lesquelles les applications ciblent WebAssembly est d'exécuter sur le web avec des performances prévisibles et élevées. Ainsi, nous ne pouvons ni tolérer l'exécution de code sous-optimal trop longtemps, ni accepter des pauses de compilation pendant l'exécution.
- Un objectif de conception important de l'interpréteur Ignition pour JavaScript est de réduire l'utilisation de la mémoire en ne compilant pas du tout les fonctions. Cependant, nous avons constaté qu'un interpréteur pour WebAssembly est beaucoup trop lent pour répondre à l'objectif de performances prévisibles rapides. En effet, nous avons construit un tel interpréteur, mais étant 20× ou plus lent que le code compilé, il n'est utile que pour le débogage, quel que soit le volume de mémoire qu'il économise. Compte tenu de cela, le moteur doit de toute façon stocker du code compilé; en fin de compte, il devrait stocker uniquement le code le plus compact et le plus efficace, qui est le code optimisé TurboFan.
À partir de ces contraintes, nous avons conclu que le tier-up dynamique n'est pas le bon compromis pour l'implémentation de WebAssembly de V8 en ce moment, car il augmenterait la taille du code et réduirait les performances pendant une période indéterminée. À la place, nous avons choisi une stratégie de tier-up rapide. Immédiatement après la fin de la compilation Liftoff d'un module, le moteur WebAssembly démarre des threads en arrière-plan pour générer du code optimisé pour le module. Cela permet à V8 de commencer à exécuter du code rapidement (après la fin de Liftoff), tout en ayant le code TurboFan le plus performant disponible le plus tôt possible.
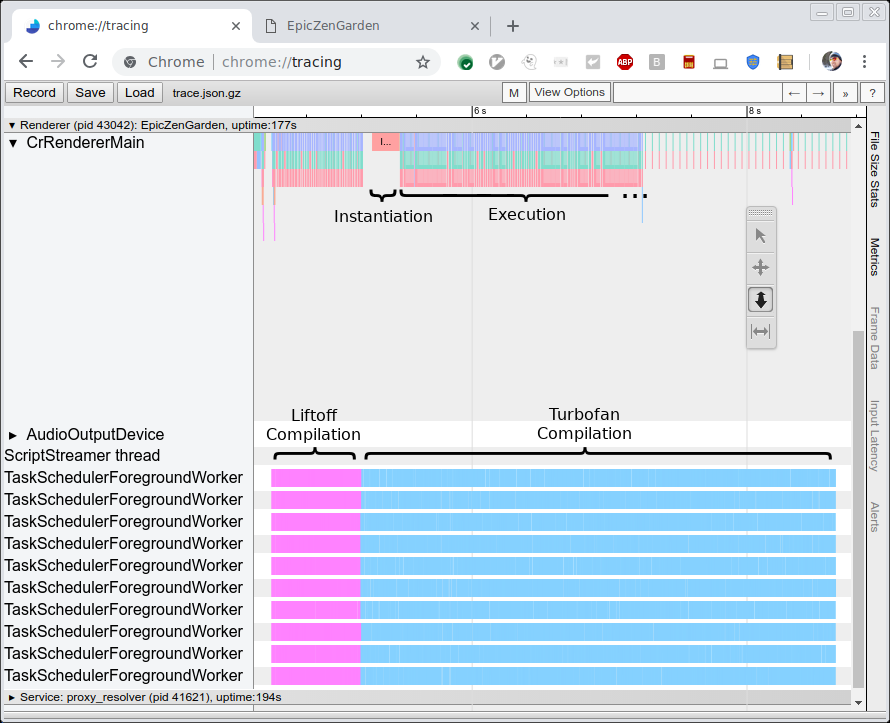
L'image ci-dessous montre la trace de la compilation et de l'exécution du benchmark EpicZenGarden. Elle montre qu'immédiatement après la compilation de Liftoff, nous pouvons instancier le module WebAssembly et commencer à l'exécuter. La compilation TurboFan prend encore plusieurs secondes, donc pendant cette période de tier-up, les performances d'exécution observées augmentent progressivement car les fonctions individuelles TurboFan sont utilisées dès qu'elles sont terminées.
Performances
Deux métriques sont intéressantes pour évaluer les performances du nouveau compilateur Liftoff. Tout d'abord, nous souhaitons comparer la vitesse de compilation (c'est-à-dire le temps nécessaire pour générer du code) avec TurboFan. Ensuite, nous voulons mesurer les performances du code généré (c'est-à-dire la vitesse d'exécution). La première mesure est la plus intéressante ici, puisque l'objectif de Liftoff est de réduire le temps de démarrage en générant du code aussi rapidement que possible. D'autre part, les performances du code généré devraient néanmoins être assez bonnes, car ce code pourrait encore s'exécuter pendant plusieurs secondes voire minutes sur du matériel bas de gamme.
Performances de génération de code
Pour mesurer les performances du compilateur lui-même, nous avons exécuté un certain nombre de benchmarks et mesuré le temps brut de compilation à l'aide de la traçabilité (voir l'image ci-dessus). Nous exécutons les deux benchmarks sur un ordinateur HP Z840 (2 x Intel Xeon E5-2690 @2.6GHz, 24 cœurs, 48 threads) et sur un Macbook Pro (Intel Core i7-4980HQ @2.8GHz, 4 cœurs, 8 threads). Notez que Chrome n'utilise actuellement pas plus de 10 threads en arrière-plan, donc la plupart des cœurs de la machine Z840 ne sont pas utilisés.
Nous exécutons trois benchmarks :
- EpicZenGarden : La démonstration ZenGarden exécutée sur le framework Epic
- Tanks! : Une démonstration du moteur Unity
- AutoDesk
- PSPDFKit
Pour chaque benchmark, nous mesurons le temps brut de compilation en utilisant la sortie de traçabilité comme indiqué ci-dessus. Ce chiffre est plus stable que tout temps rapporté par le benchmark lui-même, car il ne dépend pas d'une tâche étant planifiée sur le thread principal et n'inclut pas de travail sans rapport comme la création de l'instance WebAssembly réelle.
Les graphiques ci-dessous montrent les résultats de ces benchmarks. Chaque benchmark a été exécuté trois fois et nous rapportons le temps moyen de compilation.


Comme prévu, le compilateur Liftoff génère du code beaucoup plus rapidement à la fois sur la station de travail de bureau haut de gamme et sur le MacBook. L'accélération de Liftoff par rapport à TurboFan est encore plus grande sur le matériel MacBook moins performant.
Performances du code généré
Bien que les performances du code généré soient un objectif secondaire, nous souhaitons préserver l'expérience utilisateur avec des performances élevées dans la phase de démarrage, car le code Liftoff pourrait s'exécuter pendant plusieurs secondes avant que le code TurboFan ne soit terminé.
Pour mesurer les performances du code Liftoff, nous avons désactivé le tier-up afin de mesurer l'exécution pure de Liftoff. Dans cette configuration, nous exécutons deux benchmarks :
-
Benchmarks sans interface Unity
Il s'agit d'un certain nombre de benchmarks exécutés dans le framework Unity. Ils sont sans interface, donc peuvent être exécutés directement dans le shell d8. Chaque benchmark rapporte un score, qui n'est pas nécessairement proportionnel aux performances d'exécution, mais suffisamment bon pour comparer les performances.
-
Cette référence rapporte le temps nécessaire pour effectuer différentes actions sur un document PDF et le temps nécessaire pour instancier le module WebAssembly (y compris la compilation).
Comme précédemment, nous exécutons chaque test trois fois et utilisons la moyenne des trois exécutions. Étant donné que l'échelle des chiffres enregistrés diffère significativement entre les tests, nous rapportons les performances relatives de Liftoff par rapport à TurboFan. Une valeur de +30% signifie que le code Liftoff s'exécute 30% plus lentement que le code TurboFan. Les nombres négatifs indiquent que Liftoff s'exécute plus rapidement. Voici les résultats :

Sur Unity, le code Liftoff s'exécute en moyenne environ 50% plus lentement que le code TurboFan sur la machine de bureau et 70% plus lentement sur le MacBook. Fait intéressant, il y a un cas (Mandelbrot Script) où le code Liftoff surpasse le code TurboFan. Il s'agit probablement d'une valeur aberrante où, par exemple, l'allocation des registres de TurboFan fonctionne mal dans une boucle chaude. Nous enquêtons pour voir si TurboFan peut être amélioré pour mieux gérer ce cas.

Dans le benchmark PSPDFKit, le code Liftoff s'exécute de 18 à 54% plus lentement que le code optimisé, tandis que l'initialisation s'améliore significativement, comme prévu. Ces chiffres montrent que pour du code réel qui interagit également avec le navigateur via des appels JavaScript, la perte de performance du code non optimisé est généralement inférieure à celle sur des tests plus intensifs en calcul.
Et encore une fois, notez que pour ces chiffres, nous avons complètement désactivé le tier-up, de sorte que nous avons uniquement exécuté du code Liftoff. Dans les configurations de production, le code Liftoff sera progressivement remplacé par le code TurboFan, de sorte que la performance inférieure du code Liftoff ne dure que pendant une courte période.
Travaux futurs
Après le lancement initial de Liftoff, nous travaillons à améliorer encore davantage le temps de démarrage, à réduire l'utilisation de la mémoire et à apporter les avantages de Liftoff à plus d'utilisateurs. En particulier, nous nous concentrons sur les points suivants :
- Porter Liftoff sur arm et arm64 pour l'utiliser également sur des appareils mobiles. Actuellement, Liftoff est uniquement implémenté pour les plateformes Intel (32 et 64 bits), ce qui capture principalement des cas d'utilisation sur ordinateurs de bureau. Afin d'atteindre également les utilisateurs mobiles, nous porterons Liftoff sur davantage d'architectures.
- Implémenter le tier-up dynamique pour les appareils mobiles. Les appareils mobiles ayant généralement beaucoup moins de mémoire disponible que les systèmes de bureau, nous devons adapter notre stratégie de tiering pour ces appareils. Recompiler simplement toutes les fonctions avec TurboFan double facilement la mémoire nécessaire pour contenir tout le code, au moins temporairement (jusqu'à ce que le code Liftoff soit supprimé). À la place, nous expérimentons une combinaison de compilation à la demande avec Liftoff et de tier-up dynamique des fonctions chaudes dans TurboFan.
- Améliorer les performances de génération de code de Liftoff. La première itération d'une implémentation est rarement la meilleure. Il y a plusieurs aspects qui peuvent être ajustés pour accélérer encore davantage la vitesse de compilation de Liftoff. Cela se fera progressivement au cours des prochaines versions.
- Améliorer les performances du code Liftoff. Outre le compilateur lui-même, la taille et la vitesse du code généré peuvent également être améliorées. Cela se produira également progressivement au cours des prochaines versions.
Conclusion
V8 contient désormais Liftoff, un nouveau compilateur de base pour WebAssembly. Liftoff réduit considérablement le temps de démarrage des applications WebAssembly avec un générateur de code simple et rapide. Sur les systèmes de bureau, V8 atteint toujours des performances maximales en recompilant tout le code en arrière-plan à l'aide de TurboFan. Liftoff est activé par défaut dans V8 v6.9 (Chrome 69) et peut être contrôlé explicitement avec les drapeaux --liftoff/--no-liftoff et chrome://flags/#enable-webassembly-baseline respectivement.