Liftoff: un nuevo compilador base para WebAssembly en V8
V8 v6.9 incluye Liftoff, un nuevo compilador base para WebAssembly. Liftoff ahora está habilitado de forma predeterminada en sistemas de escritorio. Este artículo detalla la motivación para agregar otro nivel de compilación y describe la implementación y el rendimiento de Liftoff.

Desde que WebAssembly se lanzó hace más de un año, su adopción en la web ha ido aumentando constantemente. Grandes aplicaciones dirigidas a WebAssembly han comenzado a aparecer. Por ejemplo, el benchmark ZenGarden de Epic comprende un binario WebAssembly de 39.5 MB, y AutoDesk se distribuye como un binario de 36.8 MB. Dado que el tiempo de compilación es esencialmente lineal con el tamaño del binario, estas aplicaciones tardan un tiempo considerable en iniciarse. En muchas máquinas supera los 30 segundos, lo que no proporciona una gran experiencia para el usuario.
Pero, ¿por qué se tarda tanto en iniciar una aplicación WebAssembly si aplicaciones similares en JS se inician mucho más rápido? La razón es que WebAssembly promete ofrecer rendimiento predecible, de modo que, una vez que la aplicación se está ejecutando, puedes estar seguro de cumplir constantemente tus objetivos de rendimiento (por ejemplo, renderizar 60 fotogramas por segundo, sin retraso de audio ni artefactos…). Para lograr esto, el código de WebAssembly se compila por adelantado en V8, para evitar cualquier pausa de compilación introducida por un compilador just-in-time que podría resultar en un efecto no deseado visible en la aplicación.
El proceso de compilación existente (TurboFan)
El enfoque de V8 para compilar WebAssembly se ha basado en TurboFan, el compilador optimizador que diseñamos para JavaScript y asm.js. TurboFan es un compilador potente con una representación intermedia (IR) basada en gráficos adecuada para optimizaciones avanzadas como reducción de fuerza, inlining, movimiento de código, combinación de instrucciones y asignación sofisticada de registros. El diseño de TurboFan soporta entrar en el proceso muy tarde, cerca del código máquina, lo que omite muchas de las etapas necesarias para compilar JavaScript. Por diseño, transformar el código WebAssembly en la IR de TurboFan (incluido SSA-construction) en un único pase directo es muy eficiente, en parte debido al flujo de control estructurado de WebAssembly. Sin embargo, el backend del proceso de compilación aún consume un tiempo y memoria considerables.
El nuevo proceso de compilación (Liftoff)
El objetivo de Liftoff es reducir el tiempo de inicio para las aplicaciones basadas en WebAssembly generando código tan rápido como sea posible. La calidad del código es secundaria, ya que eventualmente el código caliente se recompila con TurboFan de todos modos. Liftoff evita el tiempo y el gasto de memoria de construir una IR y genera código máquina en un único pase sobre el bytecode de una función WebAssembly.

En el diagrama anterior es obvio que Liftoff debería poder generar código mucho más rápido que TurboFan, ya que el proceso solo consta de dos etapas. De hecho, el decodificador del cuerpo de función realiza un único pase sobre los bytes crudos de WebAssembly e interactúa con la etapa siguiente a través de callbacks, por lo que la generación de código se realiza mientras se decodifica y valida el cuerpo de la función. Junto con las APIs de streaming de WebAssembly, esto permite que V8 compile el código WebAssembly a código máquina mientras se descarga por la red.
Generación de código en Liftoff
Liftoff es un generador de código simple y rápido. Realiza solo una pasada sobre los códigos de operación de una función, generando código para cada uno, uno a la vez. Para códigos de operación simples como las aritméticas, esto a menudo equivale a una sola instrucción de máquina, pero puede ser más en otros casos como llamadas. Liftoff mantiene los metadatos sobre la pila de operandos para saber dónde se almacenan actualmente las entradas de cada operación. Esta pila virtual solo existe durante la compilación. El flujo de control estructurado de WebAssembly y las reglas de validación garantizan que la ubicación de estas entradas puede determinarse estáticamente. Por lo tanto, no es necesario una pila de ejecución real donde se empujen y saquen los operandos. Durante la ejecución, cada valor en la pila virtual estará almacenado en un registro o será desplazado al marco físico de pila de esa función. Para constantes enteras pequeñas (generadas por i32.const), Liftoff solo registra el valor de la constante en la pila virtual y no genera ningún código. Solo cuando la constante es utilizada por una operación subsecuente, se emite o se combina con la operación, por ejemplo, mediante la emisión directa de una instrucción addl <reg>, <const> en x64. Esto evita cargar esa constante en un registro, resultando en un mejor código.
Repasemos una función muy simple para ver cómo Liftoff genera código para ella.

Esta función de ejemplo toma dos parámetros y devuelve su suma. Cuando Liftoff decodifica los bytes de esta función, comienza primero inicializando su estado interno para las variables locales según el convenio de llamadas para funciones de WebAssembly. Para x64, el convenio de llamadas de V8 pasa los dos parámetros en los registros rax y rdx.
Para las instrucciones get_local, Liftoff no genera ningún código, sino que simplemente actualiza su estado interno para reflejar que estos valores de registro ahora se han empujado en la pila virtual. Luego, la instrucción i32.add saca los dos registros y elige un registro para el valor resultante. No podemos usar ninguno de los registros de entrada para el resultado, ya que ambos registros todavía aparecen en la pila para contener las variables locales. Sobrescribirlos cambiaría el valor devuelto por una instrucción get_local posterior. Entonces, Liftoff elige un registro libre, en este caso rcx, y produce la suma de rax y rdx en ese registro. Luego, rcx se empuja en la pila virtual.
Después de la instrucción i32.add, se termina el cuerpo de la función, por lo que Liftoff debe ensamblar el retorno de la función. Como nuestra función de ejemplo tiene un valor de retorno, la validación requiere que haya exactamente un valor en la pila virtual al final del cuerpo de la función. Por lo tanto, Liftoff genera código que mueve el valor de retorno almacenado en rcx al registro de retorno apropiado rax y luego regresa de la función.
Por motivos de simplicidad, el ejemplo anterior no contiene ningún bloque (if, loop…) ni ramas. Los bloques en WebAssembly introducen fusiones de control, ya que el código puede ramificarse hasta cualquier bloque padre, y los bloques if pueden omitirse. Estos puntos de fusión pueden alcanzarse desde diferentes estados de pila. Sin embargo, el código que sigue debe asumir un estado de pila específico para generar código. Por lo tanto, Liftoff toma una instantánea del estado actual de la pila virtual como el estado que se asumirá para el código que sigue al nuevo bloque (es decir, al volver al nivel de control donde estamos actualmente). El nuevo bloque continuará con el estado actualmente activo, potencialmente cambiando dónde se almacenan los valores de la pila o las variables locales: algunos podrían desplazarse a la pila o mantenerse en otros registros. Al ramificarse a otro bloque o finalizar un bloque (que equivale a ramificarse al bloque padre), Liftoff debe generar código que adapte el estado actual al estado esperado en ese punto, de modo que el código emitido para el destino que ramificamos encuentre los valores correctos donde los espera. La validación garantiza que la altura de la pila virtual actual coincida con la altura del estado esperado, por lo que Liftoff solo necesita generar código para reorganizar valores entre los registros y/o el marco físico de la pila, como se muestra a continuación.
Veamos un ejemplo de eso.

El ejemplo anterior asume una pila virtual con dos valores en la pila de operandos. Antes de comenzar el nuevo bloque, el valor superior de la pila virtual se saca como argumento para la instrucción if. El valor restante de la pila necesita colocarse en otro registro, ya que actualmente está ensombreciendo el primer parámetro, pero al ramificarse de regreso a este estado podríamos necesitar mantener dos valores diferentes para el valor de la pila y el parámetro. En este caso, Liftoff elige deduplicarlo en el registro rcx. Este estado se toma como una instantánea, y el estado activo se modifica dentro del bloque. Al final del bloque, implícitamente nos ramificamos de regreso al bloque padre, por lo que fusionamos el estado actual con la instantánea moviendo el registro rbx a rcx y recargando el registro rdx desde el marco de la pila.
Subiendo de nivel desde Liftoff a TurboFan
Con Liftoff y TurboFan, V8 ahora tiene dos niveles de compilación para WebAssembly: Liftoff como el compilador base para un inicio rápido y TurboFan como el compilador optimizador para obtener el máximo rendimiento. Esto plantea la cuestión de cómo combinar los dos compiladores para ofrecer la mejor experiencia general al usuario.
Para JavaScript, V8 utiliza el intérprete Ignition y el compilador TurboFan, y emplea una estrategia de subida de nivel dinámica. Cada función se ejecuta primero en Ignition, y si la función se vuelve caliente, TurboFan la compila en código de máquina altamente optimizado. Un enfoque similar también podría usarse para Liftoff, pero los intercambios son un poco diferentes aquí:
- WebAssembly no requiere retroalimentación de tipos para generar código rápido. Donde JavaScript se beneficia enormemente de recopilar retroalimentación de tipos, WebAssembly está tipado estáticamente, por lo que el motor puede generar código optimizado de inmediato.
- El código WebAssembly debe ejecutarse prediblemente rápido, sin una fase de calentamiento prolongada. Una de las razones por las cuales las aplicaciones usan WebAssembly es para ejecutar en la web con un alto rendimiento predecible. Por lo tanto, no podemos tolerar ejecutar código subóptimo durante demasiado tiempo, ni aceptar pausas de compilación durante la ejecución.
- Un objetivo importante del diseño del intérprete Ignition para JavaScript es reducir el uso de memoria al no compilar funciones en absoluto. Sin embargo, descubrimos que un intérprete para WebAssembly es demasiado lento para cumplir con el objetivo de un rendimiento predecible rápido. De hecho, construimos tal intérprete, pero siendo 20× veces o más lento que el código compilado, solo es útil para depuración, independientemente de cuánta memoria ahorre. Dado esto, el motor debe almacenar el código compilado de todos modos; al final, debería almacenar solo el código más compacto y eficiente, que es el código optimizado de TurboFan.
A partir de estas limitaciones, concluimos que la escalada dinámica no es el intercambio correcto para la implementación de WebAssembly de V8 en este momento, ya que aumentaría el tamaño del código y reduciría el rendimiento durante un período de tiempo indeterminado. En cambio, elegimos una estrategia de escalada inmediata. Justo después de que la compilación Liftoff de un módulo finaliza, el motor WebAssembly inicia hilos en segundo plano para generar código optimizado para el módulo. Esto permite que V8 comience a ejecutar código rápidamente (después de que Liftoff finalice), pero aún tener el código TurboFan más eficiente disponible lo antes posible.
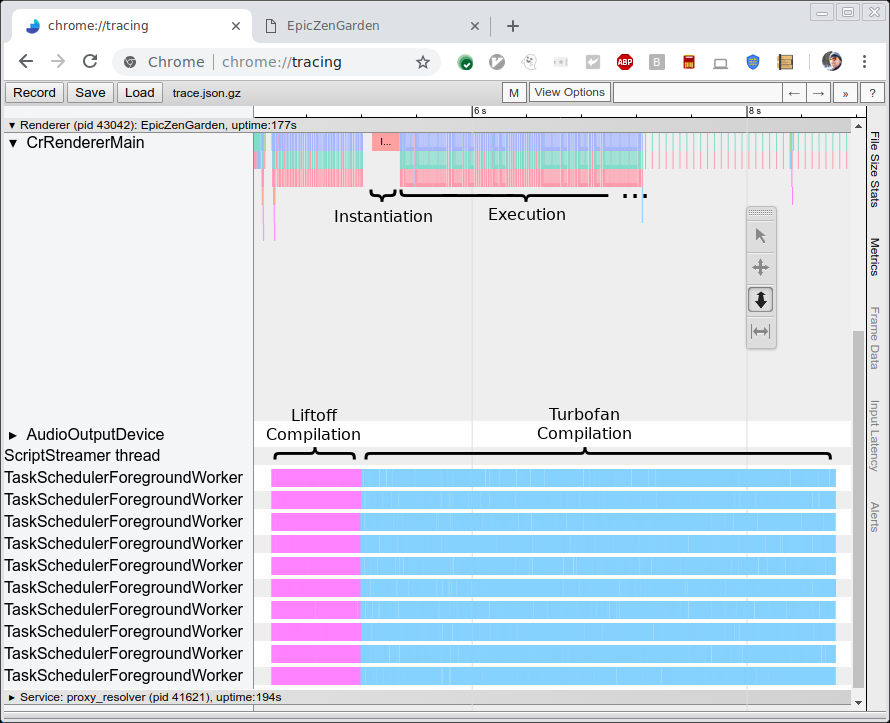
La imagen debajo muestra el registro de compilación y ejecución del EpicZenGarden benchmark. Muestra que justo después de la compilación Liftoff podemos instanciar el módulo WebAssembly y comenzar a ejecutarlo. La compilación de TurboFan aún toma varios segundos más, por lo que durante ese período de escalada, el rendimiento de la ejecución observado aumenta gradualmente, ya que las funciones individuales de TurboFan se utilizan tan pronto como están terminadas.
Rendimiento
Dos métricas son interesantes para evaluar el rendimiento del nuevo compilador Liftoff. Primero queremos comparar la velocidad de compilación (es decir, el tiempo para generar código) con TurboFan. Segundo, queremos medir el rendimiento del código generado (es decir, la velocidad de ejecución). La primera medida es la más interesante aquí, ya que el objetivo de Liftoff es reducir el tiempo de inicio al generar código lo más rápido posible. Por otro lado, el rendimiento del código generado aún debería ser bastante bueno, ya que ese código podría seguir ejecutándose durante varios segundos o incluso minutos en hardware de gama baja.
Rendimiento al generar código
Para medir el rendimiento del compilador en sí, ejecutamos una serie de pruebas y medimos el tiempo bruto de compilación usando el registro (ver imagen arriba). Ejecutamos ambos benchmarks en una máquina HP Z840 (2 x Intel Xeon E5-2690 @2.6GHz, 24 núcleos, 48 hilos) y en una MacBook Pro (Intel Core i7-4980HQ @2.8GHz, 4 núcleos, 8 hilos). Cabe destacar que Chrome actualmente no usa más de 10 hilos en segundo plano, por lo que la mayoría de los núcleos de la máquina Z840 no se utilizan.
Ejecutamos tres benchmarks:
- EpicZenGarden: La demostración de ZenGarden que se ejecuta en el framework Epic
- Tanks!: Una demostración del motor Unity
- AutoDesk
- PSPDFKit
Para cada benchmark, medimos el tiempo bruto de compilación utilizando la salida de registro como se muestra arriba. Este número es más estable que cualquier tiempo reportado por el benchmark en sí, ya que no depende de una tarea que se programe en el hilo principal y no incluye trabajo no relacionado, como crear realmente la instancia de WebAssembly.
Los gráficos a continuación muestran los resultados de estos benchmarks. Cada uno fue ejecutado tres veces y reportamos el tiempo promedio de compilación.


Como era de esperar, el compilador Liftoff genera código mucho más rápido tanto en la estación de trabajo de escritorio avanzada como en la MacBook. La aceleración de Liftoff sobre TurboFan es incluso mayor en el hardware menos capaz de MacBook.
Rendimiento del código generado
Aunque el rendimiento del código generado es un objetivo secundario, queremos preservar la experiencia del usuario con alto rendimiento en la fase de inicio, ya que el código Liftoff podría ejecutarse durante varios segundos antes de que el código TurboFan esté terminado.
Para medir el rendimiento del código Liftoff, desactivamos la escalada para medir solo la ejecución pura de Liftoff. En esta configuración, ejecutamos dos benchmarks:
-
Benchmarks de Unity sin interfaz gráfica
Estos son una serie de benchmarks que se ejecutan en el framework Unity. Son sin interfaz gráfica, por lo que se pueden ejecutar directamente en el shell d8. Cada benchmark reporta una puntuación, que no es necesariamente proporcional al rendimiento de ejecución, pero es suficientemente buena para comparar el rendimiento.
-
Este benchmark informa el tiempo que lleva realizar diferentes acciones en un documento pdf y el tiempo que lleva instanciar el módulo WebAssembly (incluida la compilación).
Al igual que antes, ejecutamos cada benchmark tres veces y usamos el promedio de las tres ejecuciones. Dado que la escala de los números registrados difiere significativamente entre los benchmarks, informamos el rendimiento relativo de Liftoff vs. TurboFan. Un valor de +30% significa que el código de Liftoff se ejecuta un 30% más lento que el de TurboFan. Los números negativos indican que Liftoff se ejecuta más rápido. Aquí están los resultados:

En Unity, el código de Liftoff se ejecuta en promedio un 50% más lento que el código de TurboFan en la máquina de escritorio y un 70% más lento en la MacBook. Curiosamente, hay un caso (Script de Mandelbrot) donde el código de Liftoff supera al código de TurboFan. Es probable que sea un caso atípico donde, por ejemplo, el asignador de registros de TurboFan tiene un desempeño deficiente en un bucle crítico. Estamos investigando para ver si se puede mejorar TurboFan para manejar mejor este caso.

En el benchmark de PSPDFKit, el código de Liftoff se ejecuta entre un 18-54% más lento que el código optimizado, mientras que la inicialización mejora significativamente, como era de esperar. Estos números muestran que para el código del mundo real que también interactúa con el navegador a través de llamadas de JavaScript, la pérdida de rendimiento del código no optimizado es generalmente menor que en benchmarks más intensivos de cálculo.
Y nuevamente, tenga en cuenta que para estos números desactivamos completamente el escalado de niveles, por lo que solo ejecutamos el código de Liftoff. En configuraciones de producción, el código de Liftoff será reemplazado gradualmente por el código de TurboFan, de modo que el menor rendimiento del código de Liftoff dure solo un corto período de tiempo.
Trabajo futuro
Después del lanzamiento inicial de Liftoff, estamos trabajando para mejorar aún más el tiempo de inicio, reducir el uso de memoria y llevar los beneficios de Liftoff a más usuarios. En particular, estamos trabajando en mejorar las siguientes cosas:
- Portar Liftoff a ARM y ARM64 para usarlo también en dispositivos móviles. Actualmente, Liftoff solo está implementado para plataformas Intel (32 y 64 bits), que en su mayoría capturan casos de uso de escritorio. Para llegar también a los usuarios móviles, portaremos Liftoff a más arquitecturas.
- Implementar escalado de niveles dinámico para dispositivos móviles. Dado que los dispositivos móviles tienden a tener mucha menos memoria disponible que los sistemas de escritorio, necesitamos adaptar nuestra estrategia de niveles para estos dispositivos. Simplemente recompilar todas las funciones con TurboFan duplica fácilmente la memoria necesaria para contener todo el código, al menos temporalmente (hasta que se descarte el código de Liftoff). En su lugar, estamos experimentando con una combinación de compilación diferida con Liftoff y escalado de niveles dinámico de funciones críticas en TurboFan.
- Mejorar el rendimiento de la generación de código de Liftoff. La primera iteración de una implementación rara vez es la mejor. Hay varias cosas que se pueden ajustar para acelerar aún más la velocidad de compilación de Liftoff. Esto ocurrirá gradualmente en las próximas versiones.
- Mejorar el rendimiento del código de Liftoff. Aparte del compilador en sí, también se pueden mejorar el tamaño y la velocidad del código generado. Esto también sucederá gradualmente en las próximas versiones.
Conclusión
V8 ahora incluye Liftoff, un nuevo compilador base para WebAssembly. Liftoff reduce enormemente el tiempo de inicio de las aplicaciones WebAssembly con un generador de código simple y rápido. En los sistemas de escritorio, V8 aún alcanza el máximo rendimiento pico recompilando todo el código en segundo plano utilizando TurboFan. Liftoff está habilitado de forma predeterminada en V8 v6.9 (Chrome 69) y puede controlarse explícitamente con las banderas --liftoff/--no-liftoff y chrome://flags/#enable-webassembly-baseline en cada caso, respectivamente.