Optimizando proxies de ES2015 en V8
Los proxies han sido una parte integral de JavaScript desde ES2015. Permiten interceptar operaciones fundamentales en objetos y personalizar su comportamiento. Los proxies forman una parte esencial de proyectos como jsdom y la biblioteca Comlink RPC. Recientemente, hemos puesto mucho esfuerzo en mejorar el rendimiento de los proxies en V8. Este artículo aporta algo de luz sobre los patrones generales de mejora de rendimiento en V8 y en proxies en particular.
Los proxies son “objetos utilizados para definir un comportamiento personalizado para operaciones fundamentales (por ejemplo, búsqueda de propiedades, asignación, enumeración, invocación de funciones, etc.)” (definición de MDN). Se puede encontrar más información en la especificación completa. Por ejemplo, el siguiente fragmento de código agrega registro a cada acceso de propiedad en el objeto:
const target = {};
const callTracer = new Proxy(target, {
get: (target, name, receiver) => {
console.log(`get fue llamado para: ${name}`);
return target[name];
}
});
callTracer.property = 'value';
console.log(callTracer.property);
// get fue llamado para: property
// value
Construcción de proxies
La primera característica en la que nos enfocaremos es la construcción de proxies. Nuestra implementación original en C++ seguía paso a paso la especificación de ECMAScript, resultando en al menos 4 saltos entre los entornos de ejecución de C++ y JS, como se muestra en la siguiente figura. Queríamos portar esta implementación a la plataforma agnóstica CodeStubAssembler (CSA), que se ejecuta en el entorno de JS en lugar de C++. Este port reduces el número de saltos entre los entornos de lenguaje. CEntryStub y JSEntryStub representan los entornos de ejecución en la figura a continuación. Las líneas punteadas representan las fronteras entre los entornos de ejecución de JS y C++. Afortunadamente, ya se habían implementado muchos predicados auxiliares en el ensamblador, lo que hizo que la versión inicial fuera concisa y legible.
La figura a continuación muestra el flujo de ejecución al llamar a un Proxy con cualquier trampa de proxy (en este ejemplo, apply, que se llama cuando se usa el proxy como una función) generado por el siguiente código de muestra:
function foo(…) { … }
const g = new Proxy({ … }, {
apply: foo,
});
g(1, 2);
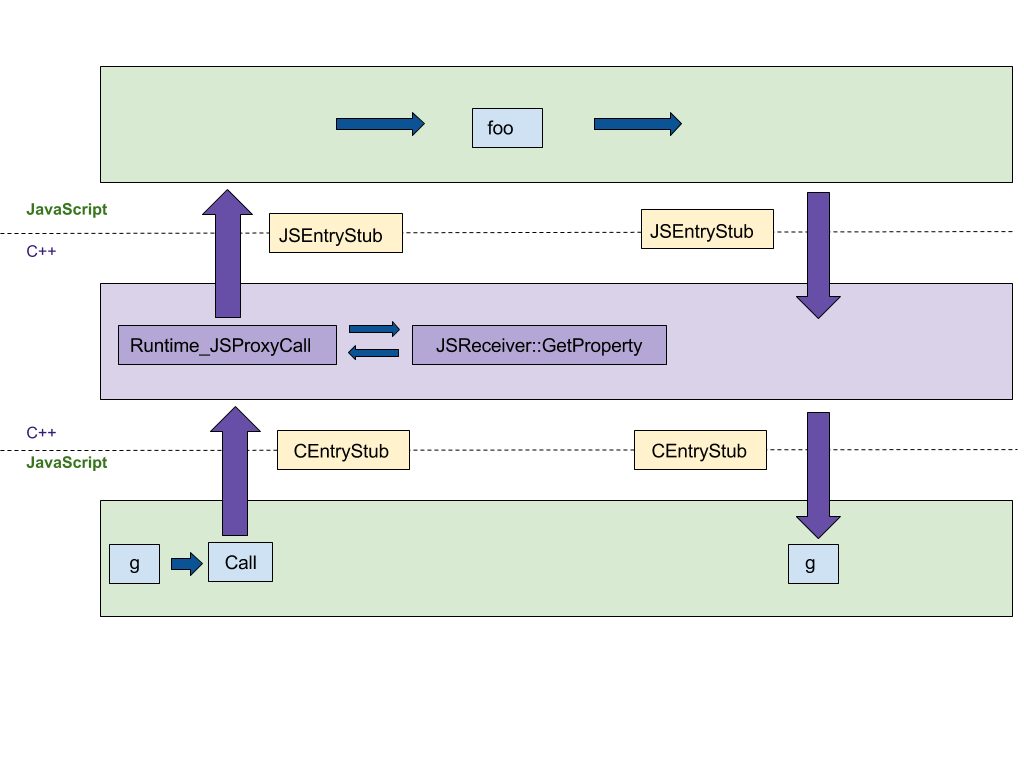
Después de portar la ejecución de trampas a CSA, toda la ejecución ocurre en el entorno de JS, reduciendo el número de saltos entre lenguajes de 4 a 0.
Este cambio resultó en las siguientes mejoras de rendimiento:
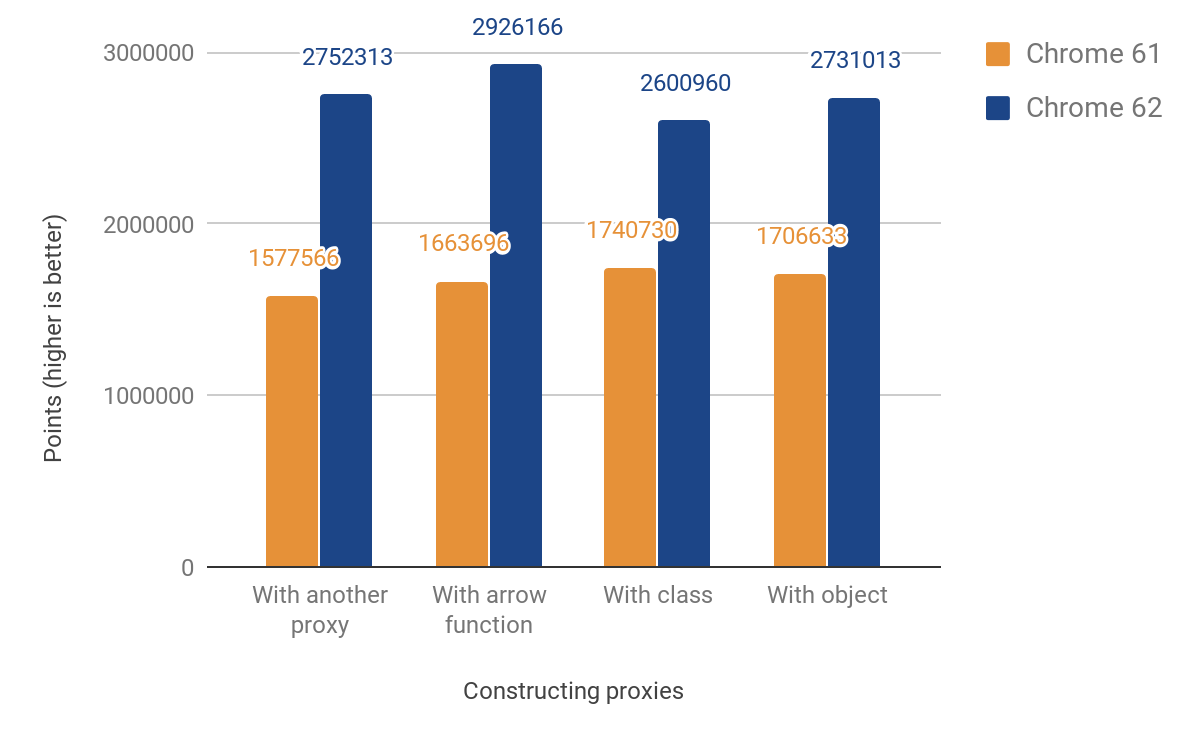
Nuestro puntaje de rendimiento de JS muestra una mejora entre 49% y 74%. Este puntaje mide aproximadamente cuántas veces se puede ejecutar el microbenchmark dado en 1000ms. Para algunas pruebas, el código se ejecuta varias veces para obtener una medición lo suficientemente precisa según la resolución del temporizador. El código de todos los benchmarks siguientes se puede encontrar en nuestro directorio js-perf-test.
Trampas de llamada y construcción
La siguiente sección muestra los resultados de optimizar las trampas de llamada y construcción (también conocidas como "apply" y "construct").
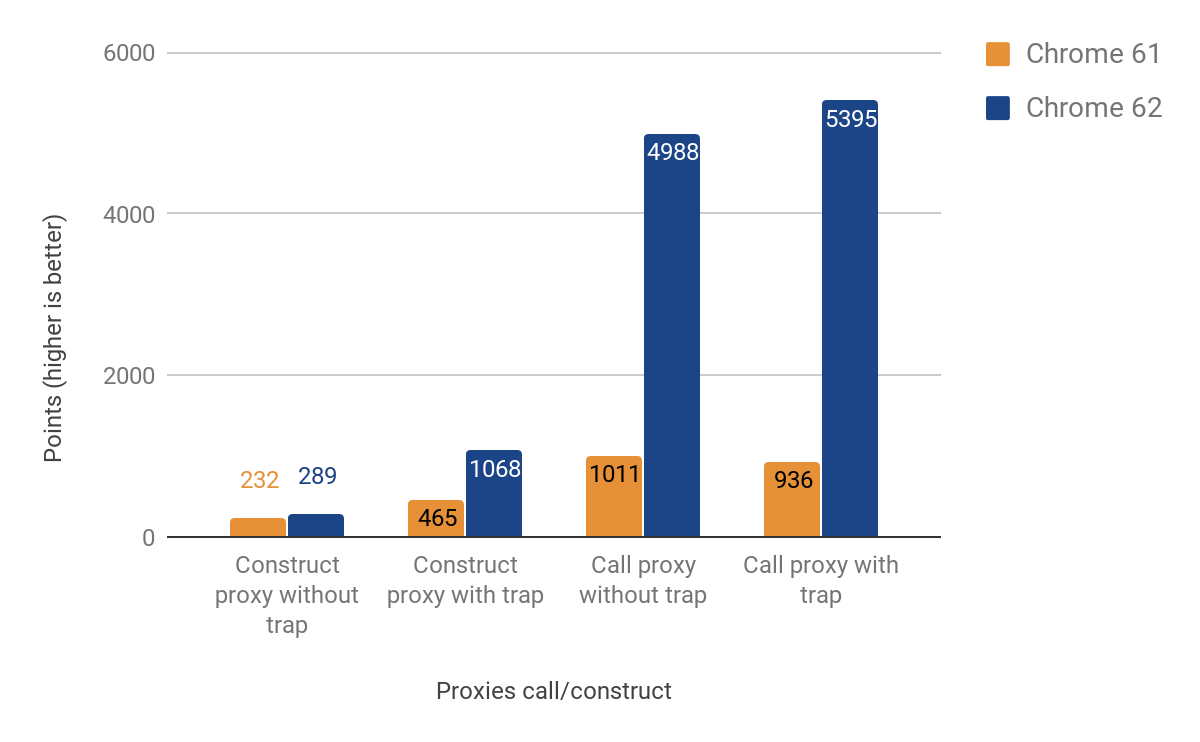
Las mejoras de rendimiento al llamar a proxies son significativas — ¡hasta un 500% más rápido! Sin embargo, la mejora para la construcción de proxies es bastante modesta, especialmente en casos donde no se define una trampa real — solo una ganancia de aproximadamente 25%. Investigamos esto ejecutando el siguiente comando con el shell d8:
$ out/x64.release/d8 --runtime-call-stats test.js
> run: 120.104000
Función de Runtime/Construcción en C++ Tiempo Cuenta
========================================================================================
NewObject 59.16ms 48.47% 100000 24.94%
JS_Ejecución 23.83ms 19.53% 1 0.00%
RecompilaciónSincrónica 11.68ms 9.57% 20 0.00%
CallbackAccesorNombreObtener 10.86ms 8.90% 100000 24.94%
CallbackAccesorNombreObtener_PrototipoFunción 5.79ms 4.74% 100000 24.94%
Map_SetPrototipo 4.46ms 3.65% 100203 25.00%
… FRAGMENTO …
Donde el origen de test.js es:
function MyClass() {}
MyClass.prototype = {};
const P = new Proxy(MyClass, {});
function run() {
return new P();
}
const N = 1e5;
console.time('run');
for (let i = 0; i < N; ++i) {
run();
}
console.timeEnd('run');
Resultó que la mayor parte del tiempo se gasta en NewObject y las funciones llamadas por este, así que comenzamos a planificar cómo acelerar esto en futuras versiones.
Filtro Get
La siguiente sección describe cómo optimizamos las otras operaciones más comunes: obtener y establecer propiedades a través de proxies. Resultó que el filtro get es más complejo que los casos anteriores, debido al comportamiento específico de la caché en línea de V8. Para una explicación detallada de las cachés en línea, puedes ver esta charla.
Finalmente logramos una portabilidad funcional para CSA con los siguientes resultados:
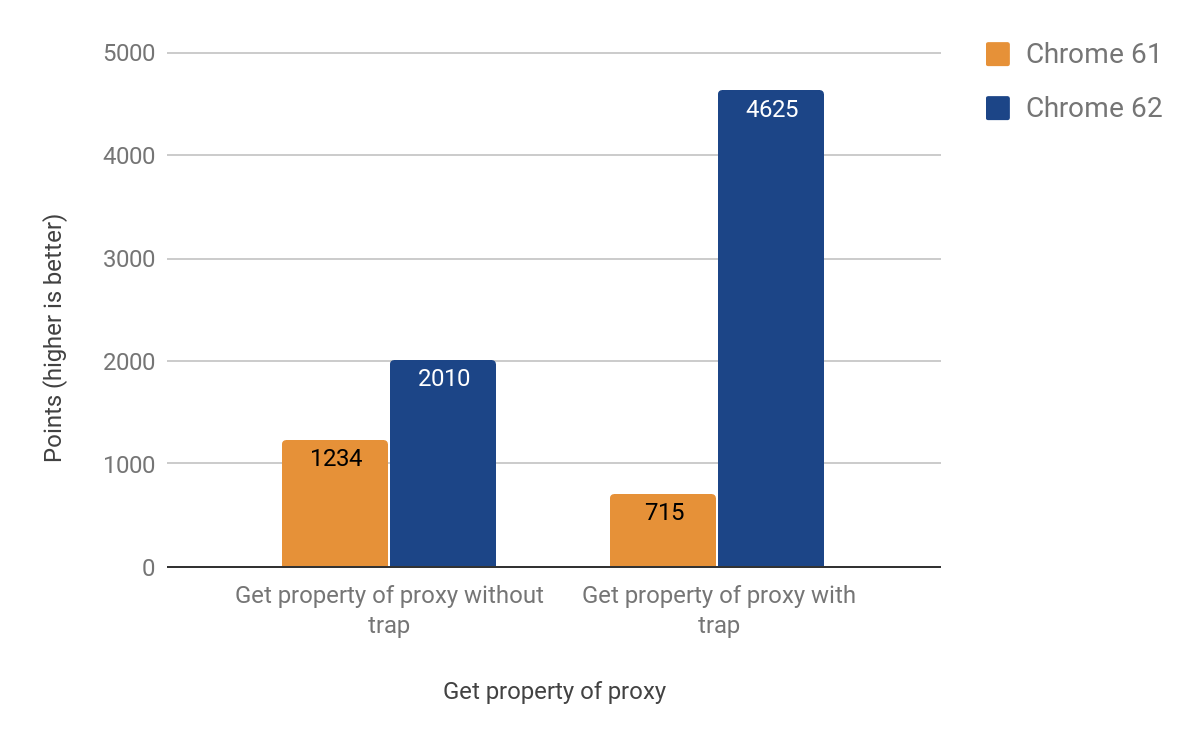
Después de implementar el cambio, notamos que el tamaño del .apk de Android para Chrome había aumentado en ~160KB, lo cual es más de lo esperado para una función auxiliar de aproximadamente 20 líneas, pero afortunadamente realizamos un seguimiento de dichas estadísticas. Resultó que esta función se llama dos veces desde otra función, que se llama 3 veces, desde otra llamada 4 veces. La causa del problema resultó ser la inclusión agresiva. Finalmente resolvimos el problema convirtiendo la función en línea en un código separado, así ahorramos KB preciosos: la versión final solo tuvo un aumento de ~19KB en el tamaño del .apk.
Filtro Has
La siguiente sección muestra los resultados de optimizar el filtro has. Aunque al principio pensamos que sería más fácil (y reutilizaría gran parte del código del filtro get), resultó tener sus propias particularidades. Un problema especialmente difícil de rastrear fue el recorrido de la cadena de prototipos al usar el operador in. Los resultados de mejora logrados varían entre 71% y 428%. Nuevamente, la ganancia es más prominente en casos donde el filtro está presente.

Filtro Set
La siguiente sección habla sobre la portabilidad del filtro set. Esta vez tuvimos que diferenciar entre propiedades nombradas e indexadas (elementos). Estos dos tipos principales no forman parte del lenguaje JS, pero son esenciales para el almacenamiento eficiente de propiedades de V8. La implementación inicial todavía recurría a la ejecución para elementos, lo cual provoca cruzar nuevamente los límites del lenguaje. Sin embargo, logramos mejoras entre 27% y 438% en casos en los que el filtro está configurado, a costa de una disminución de hasta 23% cuando no lo está. Esta regresión en el rendimiento se debe al costo adicional de las verificaciones para diferenciar entre propiedades indexadas y nombradas. Para las propiedades indexadas, aún no hay mejora. Aquí están los resultados completos:
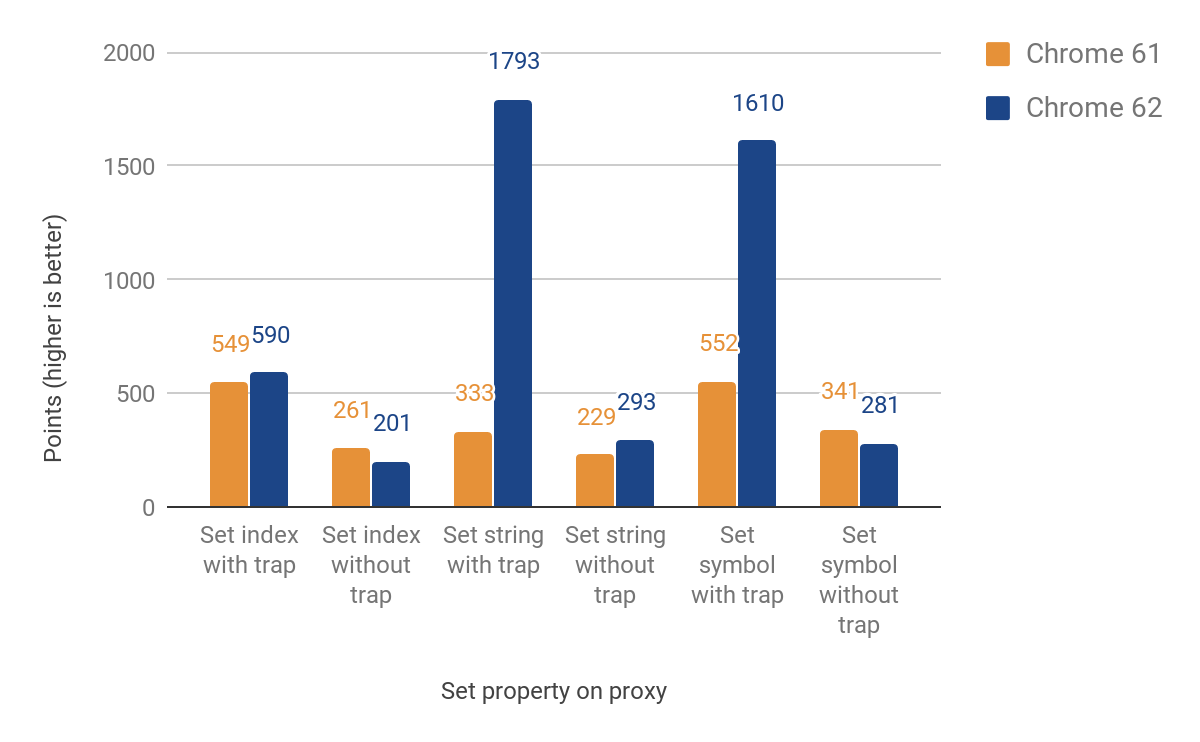
Uso en el mundo real
Resultados del jsdom-proxy-benchmark
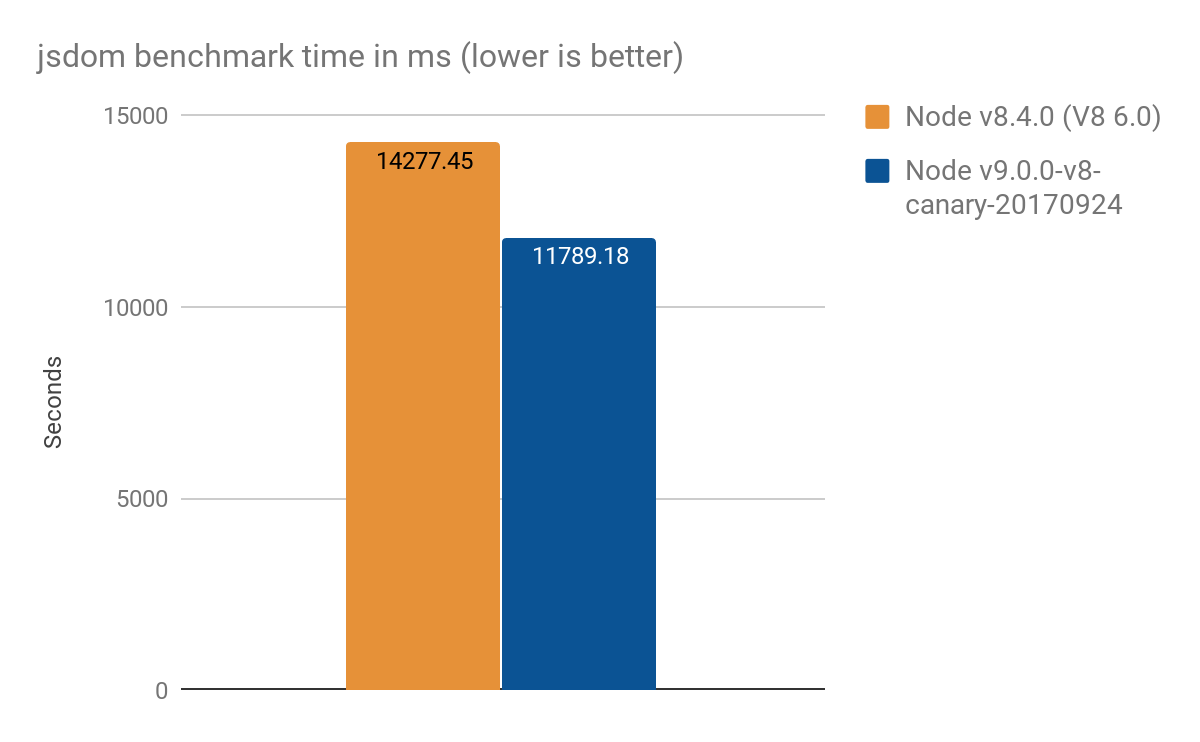
El proyecto jsdom-proxy-benchmark compila la especificación ECMAScript utilizando la herramienta Ecmarkup. A partir de la v11.2.0, el proyecto jsdom (que subyace Ecmarkup) utiliza proxies para implementar las estructuras de datos comunes NodeList y HTMLCollection. Usamos este benchmark para obtener una visión general de un uso más realista que los micro-benchmarks sintéticos, y logramos los siguientes resultados, promedio de 100 ejecuciones:
- Node v8.4.0 (sin optimizaciones Proxy): 14277 ± 159 ms
- Node v9.0.0-v8-canary-20170924 (con solo la mitad de los filtros portados): 11789 ± 308 ms
- Ganancia en velocidad de aproximadamente 2.4 segundos, lo cual es ~17% mejor
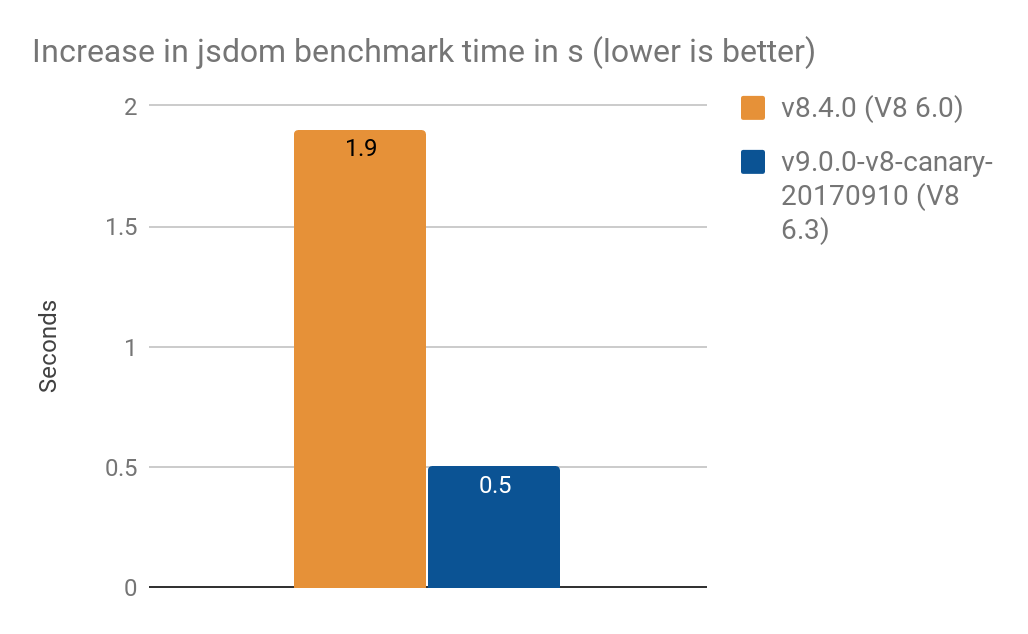
- Convertir
NamedNodeMappara usarProxyaumentó el tiempo de procesamiento en- 1.9 s en V8 6.0 (Node v8.4.0)
- 0.5 s en V8 6.3 (Node v9.0.0-v8-canary-20170910)
Nota: Estos resultados fueron proporcionados por Timothy Gu. ¡Gracias!
Resultados de Chai.js
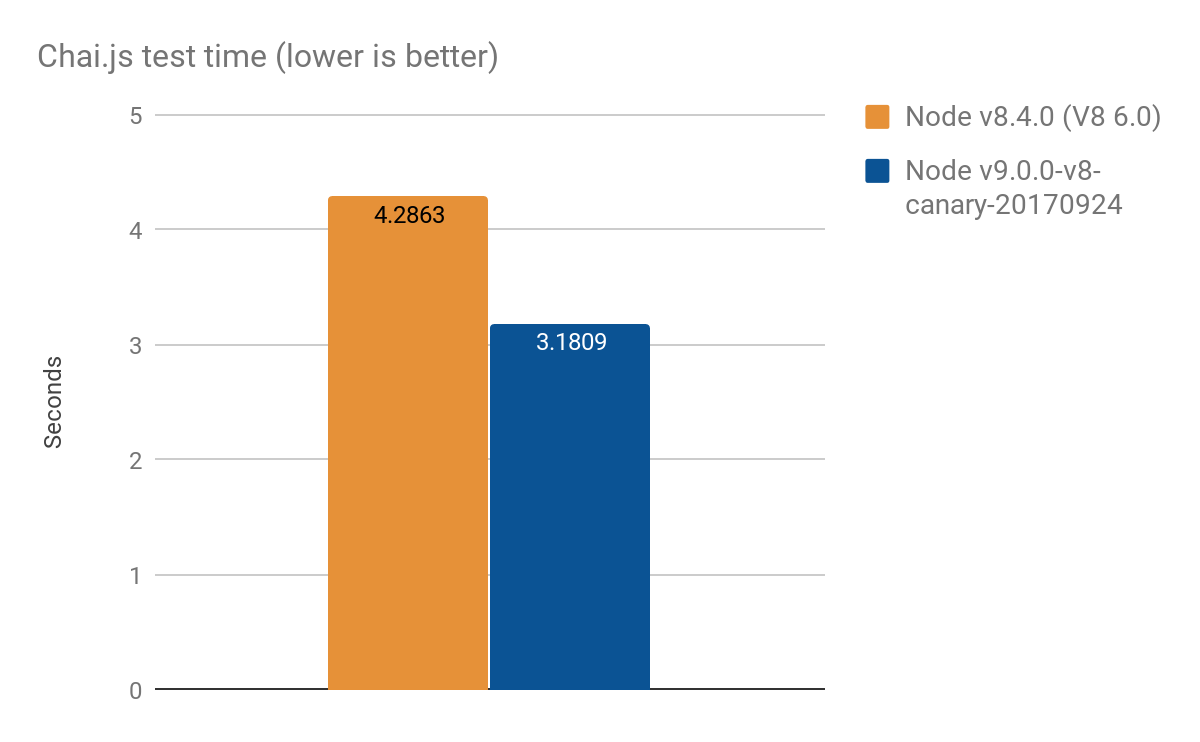
Chai.js es una biblioteca de aserciones popular que hace un uso intensivo de proxies. Hemos creado una especie de punto de referencia del mundo real ejecutando sus pruebas con diferentes versiones de V8, logrando una mejora de aproximadamente 1s de más de 4s, promedio de 100 ejecuciones:
- Node v8.4.0 (sin optimizaciones de Proxy): 4.2863 ± 0.14 s
- Node v9.0.0-v8-canary-20170924 (con solo la mitad de los traps portados): 3.1809 ± 0.17 s
Enfoque de optimización
A menudo abordamos problemas de rendimiento utilizando un esquema genérico de optimización. El enfoque principal que seguimos para este trabajo en particular incluyó los siguientes pasos:
- Implementar pruebas de rendimiento para la subcaracterística en cuestión
- Agregar más pruebas de conformidad con la especificación (o escribirlas desde cero)
- Investigar la implementación original en C++
- Portar la subcaracterística al CodeStubAssembler agnóstico a la plataforma
- Optimizar aún más el código elaborando manualmente una implementación de TurboFan
- Medir la mejora de rendimiento.
Este enfoque se puede aplicar a cualquier tarea general de optimización que tengas.