Acelerando los elementos extendidos
Durante sus tres meses de prácticas en el equipo de V8, Hai Dang trabajó en mejorar el rendimiento de [...array], [...string], [...set], [...map.keys()] y [...map.values()] (cuando los elementos extendidos están al inicio del literal de array). Incluso hizo que Array.from(iterable) fuese mucho más rápido. Este artículo explica algunos de los detalles de sus cambios, que están incluidos en V8 a partir de la versión 7.2.
Elementos extendidos
Los elementos extendidos son componentes de literales de array que tienen la forma ...iterable. Fueron introducidos en ES2015 como una forma de crear arrays a partir de objetos iterables. Por ejemplo, el literal de array [1, ...arr, 4, ...b] crea un array cuyo primer elemento es 1 seguido de los elementos del array arr, luego 4, y finalmente los elementos del array b:
const a = [2, 3];
const b = [5, 6, 7];
const result = [1, ...a, 4, ...b];
// → [1, 2, 3, 4, 5, 6, 7]
Como otro ejemplo, cualquier cadena de texto puede extenderse para crear un array de sus caracteres (puntos de código Unicode):
const str = 'こんにちは';
const result = [...str];
// → ['こ', 'ん', 'に', 'ち', 'は']
De manera similar, cualquier conjunto (set) puede extenderse para crear un array de sus elementos, ordenados según el orden de inserción:
const s = new Set();
s.add('V8');
s.add('TurboFan');
const result = [...s];
// → ['V8', 'TurboFan']
En general, la sintaxis de elementos extendidos ...x en un literal de array asume que x proporciona un iterador (accesible a través de x[Symbol.iterator]()). Este iterador se utiliza para obtener los elementos que se insertarán en el array resultante.
El caso de uso sencillo de extender un array arr en un nuevo array, sin agregar más elementos antes o después, [...arr], se considera una forma concisa e idiomática de clonar superficialmente arr en ES2015. Desafortunadamente, en V8, el rendimiento de este método estaba muy por detrás de su contraparte en ES5. ¡El objetivo de la pasantía de Hai fue cambiar esto!
¿Por qué los elementos extendidos son (o eran) lentos?
Existen muchas formas de clonar superficialmente un array arr. Por ejemplo, puedes usar arr.slice(), o arr.concat(), o [...arr]. O bien, puedes escribir tu propia función de clonación que emplee un bucle for estándar:
function clone(arr) {
// Preasignar el número correcto de elementos, para evitar
// tener que aumentar el tamaño del array.
const result = new Array(arr.length);
for (let i = 0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
Idealmente, todas estas opciones tendrían características de rendimiento similares. Desafortunadamente, si eliges [...arr] en V8, ¡será (o era) probablemente más lento que clone! La razón es que V8 esencialmente transpone [...arr] en una iteración como la siguiente:
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
Este código es generalmente más lento que clone por algunas razones:
- Necesita crear el
iteratoral principio cargando y evaluando la propiedadSymbol.iterator. - Necesita crear y consultar el objeto
iteratorResulten cada paso. - Crece el array
resulten cada paso de la iteración llamando apush, lo que realoja repetidamente el almacenamiento subyacente.
La razón para usar tal implementación es que, como se mencionó anteriormente, la extensión puede realizarse no solo en arrays sino, de hecho, en objetos iterables arbitrarios, y debe seguir el protocolo de iteración. Sin embargo, V8 debería ser lo suficientemente inteligente para reconocer si el objeto que se está extendiendo es un array, de modo que pueda realizar la extracción de elementos a un nivel inferior y, por lo tanto,:
- evitar la creación del objeto iterador,
- evitar la creación de los objetos resultado del iterador, y
- evitar el crecimiento continuo y, por ende, la reasignación del array resultante (conocemos el número de elementos de antemano).
Implementamos esta simple idea usando CSA para arrays rápidos, es decir, arrays con uno de los seis tipos de elementos más comunes. La optimización se aplica para el escenario común en el mundo real donde la extensión ocurre al inicio del literal de array, e.g. [...foo]. Como se muestra en el gráfico a continuación, este nuevo camino rápido ofrece una mejora de rendimiento aproximadamente de 3× al extender un array de longitud 100.000, haciéndolo un 25% más rápido que el bucle clone escrito a mano.
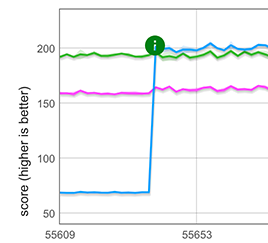
Nota: Aunque no se muestra aquí, el camino rápido también se aplica cuando los elementos esparcidos son seguidos por otros componentes (por ejemplo, [...arr, 1, 2, 3]), pero no cuando están precedidos por otros (por ejemplo, [1, 2, 3, ...arr]).
Camina con cuidado por ese camino rápido
Eso claramente es una mejora impresionante en velocidad, pero debemos ser muy cautelosos acerca de cuándo es correcto tomar este camino rápido: JavaScript permite al programador modificar el comportamiento de iteración de los objetos (incluso de los arreglos) de varias maneras. Debido a que los elementos esparcidos están especificados para usar el protocolo de iteración, necesitamos asegurarnos de que dichas modificaciones sean respetadas. Lo hacemos evitando por completo el camino rápido siempre que la maquinaria de iteración original haya sido alterada. Por ejemplo, esto incluye situaciones como las siguientes.
Propiedad propia Symbol.iterator
Normalmente, un arreglo arr no tiene su propia propiedad Symbol.iterator, por lo que al buscar ese símbolo, se encontrará en el prototipo del arreglo. En el siguiente ejemplo, el prototipo es ignorado al definir la propiedad Symbol.iterator directamente en arr. Después de esta modificación, al buscar Symbol.iterator en arr resulta en un iterador vacío, y por lo tanto el esparcimiento de arr no produce elementos y el literal del arreglo se evalúa como un arreglo vacío.
const arr = [1, 2, 3];
arr[Symbol.iterator] = function() {
return { next: function() { return { done: true }; } };
};
const result = [...arr];
// → []
Modificación de %ArrayIteratorPrototype%
El método next también puede ser modificado directamente en %ArrayIteratorPrototype%, el prototipo de los iteradores de arreglos (lo que afecta a todos los arreglos).
Object.getPrototypeOf([][Symbol.iterator]()).next = function() {
return { done: true };
}
const arr = [1, 2, 3];
const result = [...arr];
// → []
Tratando con arreglos holey
También se necesita atención adicional al copiar arreglos con huecos, es decir, arreglos como ['a', , 'c'] que carecen de algunos elementos. Esparcir un arreglo de este tipo, en virtud de adherirse al protocolo de iteración, no preserva los huecos sino que los llena con los valores encontrados en el prototipo del arreglo en los índices correspondientes. Por defecto no hay elementos en el prototipo de un arreglo, lo que significa que cualquier hueco se llena con undefined. Por ejemplo, [...['a', , 'c']] se evalúa como un nuevo arreglo ['a', undefined, 'c'].
Nuestro camino rápido es lo suficientemente inteligente como para manejar huecos en esta situación por defecto. En lugar de copiar ciegamente el almacén de respaldo del arreglo de entrada, busca huecos y se encarga de convertirlos en valores undefined. El gráfico a continuación contiene mediciones para un arreglo de entrada de longitud 100,000 que contiene solo (etiquetados) 600 enteros — el resto son huecos. Muestra que esparcir tal arreglo holey ahora es más de 4× más rápido que usar la función clone. (Solía estar aproximadamente a la par, pero esto no se muestra en el gráfico).
Tenga en cuenta que aunque slice se incluye en este gráfico, la comparación con él es injusta porque slice tiene una semántica diferente para arreglos holey: preserva todos los huecos, por lo que tiene mucho menos trabajo que hacer.

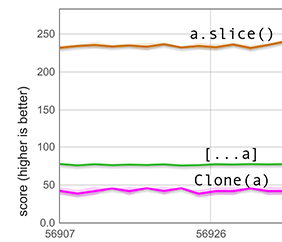
El llenado de huecos con undefined que nuestro camino rápido tiene que realizar no es tan simple como parece: puede requerir convertir todo el arreglo a un tipo de elementos diferente. El siguiente gráfico mide una situación así. La configuración es la misma que la anterior, excepto que esta vez los 600 elementos del arreglo son dobles no encapsulados y el arreglo tiene el tipo de elementos HOLEY_DOUBLE_ELEMENTS. Dado que este tipo de elementos no puede contener valores etiquetados como undefined, el esparcimiento implica una costosa transición de tipo de elementos, razón por la cual la puntuación para [...a] es mucho menor que en el gráfico anterior. Sin embargo, todavía es mucho más rápido que clone(a).
Esparciendo cadenas, conjuntos y mapas
La idea de omitir el objeto iterador y evitar hacer crecer el arreglo resultante también se aplica al esparcimiento de otros tipos de datos estándar. De hecho, implementamos caminos rápidos similares para cadenas primitivas, para conjuntos y para mapas, cuidando siempre evitar estos caminos en presencia de comportamiento de iteración modificado.
Respecto a los conjuntos, el camino rápido admite no solo esparcir directamente un conjunto ([...set]), sino también esparcir su iterador de claves ([...set.keys()]) y su iterador de valores ([...set.values()]). En nuestros micro-benchmarks, estas operaciones ahora son aproximadamente 18× más rápidas que antes.
La ruta rápida para mapas es similar, pero no admite la expansión directa de un mapa ([...map]), ya que consideramos que esta es una operación poco común. Por la misma razón, ninguna de las rutas rápidas admite el iterador entries(). En nuestras micropruebas, estas operaciones son ahora aproximadamente 14× más rápidas que antes.
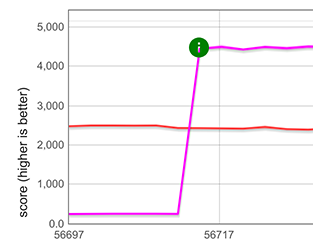
Para expandir cadenas de texto ([...string]), medimos una mejora de aproximadamente 5×, como se muestra en el gráfico a continuación con las líneas púrpura y verde. Tenga en cuenta que esto es incluso más rápido que un bucle optimizado for-of de TurboFan (TurboFan comprende la iteración de cadenas y puede generar código optimizado para ello), representado por las líneas azul y rosa. La razón de tener dos gráficos en cada caso es que las micropruebas operan en dos representaciones diferentes de cadenas (cadenas de un byte y cadenas de dos bytes).
Mejora del rendimiento de Array.from
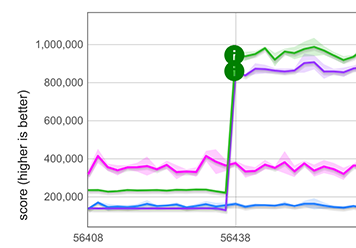
Afortunadamente, nuestras rutas rápidas para elementos extendidos pueden reutilizarse en Array.from en el caso en que se llama a Array.from con un objeto iterable y sin una función de mapeo, por ejemplo, Array.from([1, 2, 3]). Esto es posible porque en este caso, el comportamiento de Array.from es exactamente el mismo que el de expandir. Esto resulta en una mejora de rendimiento enorme, mostrada a continuación para un arreglo con 100 números de doble precisión.
Conclusión
V8 v7.2 / Chrome 72 mejora enormemente el rendimiento de los elementos extendidos cuando aparecen al frente del literal de arreglo, por ejemplo [...x] o [...x, 1, 2]. La mejora se aplica a la expansión de arreglos, cadenas de texto primitivas, conjuntos, claves de mapas, valores de mapas y —por extensión— a Array.from(x).