Accélérer les éléments de propagation
Pendant son stage de trois mois au sein de l'équipe V8, Hai Dang a travaillé à améliorer les performances de [...array], [...string], [...set], [...map.keys()], et [...map.values()] (quand les éléments de propagation sont au début du littéral de tableau). Il a même rendu Array.from(iterable) beaucoup plus rapide. Cet article explique certains détails techniques de ses modifications, incluses dans V8 à partir de la version 7.2.
Éléments de propagation
Les éléments de propagation sont des composants des littéraux de tableau ayant la forme ...iterable. Ils ont été introduits dans ES2015 comme moyen de créer des tableaux à partir d'objets itérables. Par exemple, le littéral de tableau [1, ...arr, 4, ...b] crée un tableau dont le premier élément est 1 suivi des éléments du tableau arr, puis de 4, et enfin des éléments du tableau b :
const a = [2, 3];
const b = [5, 6, 7];
const result = [1, ...a, 4, ...b];
// → [1, 2, 3, 4, 5, 6, 7]
Autre exemple, toute chaîne de caractères peut être propagée pour créer un tableau de ses caractères (points de code Unicode) :
const str = 'こんにちは';
const result = [...str];
// → ['こ', 'ん', 'に', 'ち', 'は']
De manière similaire, tout ensemble (set) peut être propagé pour créer un tableau de ses éléments, triés par ordre d'insertion :
const s = new Set();
s.add('V8');
s.add('TurboFan');
const result = [...s];
// → ['V8', 'TurboFan']
En général, la syntaxe des éléments de propagation ...x dans un littéral de tableau suppose que x fournit un itérateur (accessible via x[Symbol.iterator]()). Cet itérateur est ensuite utilisé pour obtenir les éléments à insérer dans le tableau résultant.
Le cas d'utilisation simple consistant à propager un tableau arr dans un nouveau tableau, sans ajouter d'autres éléments avant ou après, [...arr], est considéré comme une manière concise et idiomatique de cloner superficiellement arr dans ES2015. Malheureusement, dans V8, les performances de cet idiome étaient bien inférieures à celles de son équivalent ES5. L'objectif du stage de Hai était de changer cela !
Pourquoi les éléments de propagation sont (ou étaient !) lents ?
Il existe plusieurs façons de cloner superficiellement un tableau arr. Par exemple, vous pouvez utiliser arr.slice(), ou arr.concat(), ou [...arr]. Ou bien, écrire votre propre fonction clone qui utilise une boucle standard for :
function clone(arr) {
// Allouer d'avance le nombre correct d'éléments, pour éviter
// d'avoir à agrandir le tableau.
const result = new Array(arr.length);
for (let i = 0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
Idéalement, toutes ces options devraient avoir des caractéristiques de performance similaires. Malheureusement, si vous choisissez [...arr] dans V8, il est (ou était) probable qu'il soit plus lent que clone ! La raison en est que V8 transpilait essentiellement [...arr] en une itération comme la suivante :
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
Ce code est généralement plus lent que clone pour plusieurs raisons :
- Il doit créer l'
iteratorau début en chargeant et en évaluant la propriétéSymbol.iterator. - Il doit créer et interroger l'objet
iteratorResultà chaque étape. - Il agrandit le tableau
resultà chaque étape de l'itération en appelantpush, ce qui entraîne une réallocation répétée de la structure de stockage.
La raison de l'utilisation d'une telle implémentation est que, comme mentionné précédemment, la propagation peut être effectuée non seulement sur des tableaux mais, en fait, sur des objets itérables arbitraires, et doit suivre le protocole d'itération. Néanmoins, V8 devrait être assez intelligent pour reconnaître si l'objet propagé est un tableau, de sorte qu'il puisse effectuer l'extraction des éléments à un niveau inférieur et ainsi :
- éviter la création de l'objet itérateur,
- éviter la création des objets résultats de l'itérateur, et
- éviter de continuer à agrandir et ainsi réallouer le tableau résultant (nous connaissons le nombre d'éléments à l'avance).
Nous avons implémenté cette idée simple en utilisant CSA pour les tableaux rapides, c'est-à-dire les tableaux avec l'un des six types d'éléments les plus communs. L'optimisation s'applique au scénario courant du monde réel où la propagation se produit au début du littéral de tableau, par exemple [...foo]. Comme le montre le graphique ci-dessous, ce nouveau chemin rapide offre une amélioration de performance d'environ 3× pour la propagation d'un tableau de longueur 100 000, le rendant environ 25 % plus rapide que la boucle clone écrite à la main.
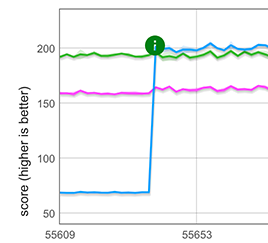
Remarque : Bien que non illustré ici, le chemin rapide s'applique également lorsque les éléments propagés sont suivis par d'autres composants (par ex. [...arr, 1, 2, 3]), mais pas lorsqu'ils sont précédés par d'autres (par ex. [1, 2, 3, ...arr]).
Avancez prudemment sur ce chemin rapide
C'est clairement une accélération impressionnante, mais nous devons être très prudents quant au moment où il est correct d'emprunter ce chemin rapide : JavaScript permet au programmeur de modifier le comportement d'itération des objets (même des tableaux) de plusieurs manières. Comme les éléments propagés doivent utiliser le protocole d'itération, nous devons nous assurer que ces modifications sont respectées. Nous le faisons en évitant complètement le chemin rapide chaque fois que le mécanisme d'itération d'origine a été modifié. Par exemple, cela inclut des situations comme les suivantes.
Propriété Symbol.iterator propre
Normalement, un tableau arr n'a pas sa propre propriété Symbol.iterator, donc lorsqu'on recherche ce symbole, il sera trouvé sur le prototype du tableau. Dans l'exemple ci-dessous, le prototype est contourné en définissant directement la propriété Symbol.iterator sur arr. Après cette modification, chercher Symbol.iterator sur arr donne un itérateur vide, et donc la propagation de arr ne produit aucun élément et le littéral de tableau évalue à un tableau vide.
const arr = [1, 2, 3];
arr[Symbol.iterator] = function() {
return { next: function() { return { done: true }; } };
};
const result = [...arr];
// → []
Modification de %ArrayIteratorPrototype%
La méthode next peut également être modifiée directement sur %ArrayIteratorPrototype%, le prototype des itérateurs de tableaux (ce qui affecte tous les tableaux).
Object.getPrototypeOf([][Symbol.iterator]()).next = function() {
return { done: true };
}
const arr = [1, 2, 3];
const result = [...arr];
// → []
Traiter les tableaux troués
Une attention particulière est également nécessaire lors de la copie de tableaux avec des trous, c'est-à-dire des tableaux comme ['a', , 'c'] qui manquent de certains éléments. Propager un tel tableau, en vertu de respecter le protocole d'itération, ne conserve pas les trous mais les remplit avec les valeurs trouvées dans le prototype du tableau aux indices correspondants. Par défaut, il n'y a aucun élément dans le prototype d'un tableau, ce qui signifie que tous les trous sont remplis avec undefined. Par exemple, [...['a', , 'c']] évalue à un nouveau tableau ['a', undefined, 'c'].
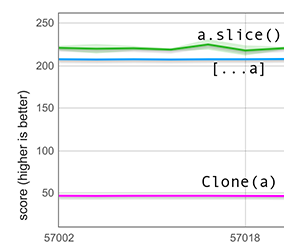
Notre chemin rapide est suffisamment intelligent pour gérer les trous dans cette situation par défaut. Au lieu de copier aveuglément le stockage sous-jacent du tableau d'entrée, il surveille les trous et prend soin de les convertir en valeurs undefined. Le graphique ci-dessous contient des mesures pour un tableau d'entrée de longueur 100 000 contenant uniquement (étiquetés) 600 entiers — le reste étant des trous. Il montre que propager un tel tableau troué est désormais plus de 4× plus rapide que d'utiliser la fonction clone. (Ils étaient auparavant à peu près au même niveau, mais cela n'est pas montré dans le graphique).
Notez que bien que slice soit inclus dans ce graphique, la comparaison avec celui-ci est injuste car slice a une sémantique différente pour les tableaux troués : il conserve tous les trous, ce qui signifie qu'il a beaucoup moins de travail à accomplir.
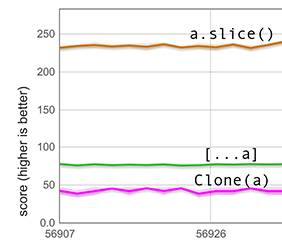
Le remplissage des trous avec undefined que notre chemin rapide doit effectuer n'est pas aussi simple qu'il y paraît : cela peut nécessiter de convertir tout le tableau en un type d'éléments différent. Le graphique suivant mesure une telle situation. Le scénario est le même que ci-dessus, sauf que cette fois les 600 éléments du tableau sont des doubles non encadrés et le tableau a le type d'éléments HOLEY_DOUBLE_ELEMENTS. Étant donné que ce type d'éléments ne peut pas contenir de valeurs taguées telles que undefined, la propagation implique une transition coûteuse du type d'éléments, ce qui explique pourquoi le score pour [...a] est beaucoup plus bas que dans le graphique précédent. Néanmoins, il est encore beaucoup plus rapide que clone(a).
Propager des chaînes, ensembles et maps
L'idée de contourner l'objet itérateur et d'éviter de faire croître le tableau résultant s'applique également à la propagation d'autres types de données standard. En effet, nous avons implémenté des chemins rapides similaires pour les chaînes primitives, les ensembles et les maps, en prenant chaque fois soin de les contourner en présence de comportements d'itération modifiés.
Concernant les ensembles, le chemin rapide prend en charge non seulement la propagation directe d'un ensemble ([...set]), mais aussi la propagation de son itérateur de clés ([...set.keys()]) et de son itérateur de valeurs ([...set.values()]). Dans nos micro-benchmarks, ces opérations sont désormais environ 18× plus rapides qu'auparavant.
Le chemin rapide pour les maps est similaire, mais ne prend pas en charge la propagation directe d'une map ([...map]), car nous considérons cela comme une opération peu courante. Pour la même raison, aucun chemin rapide ne prend en charge l'itérateur entries(). Dans nos micro-benchmarks, ces opérations sont désormais environ 14 fois plus rapides qu'avant.
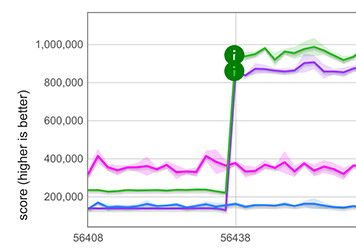
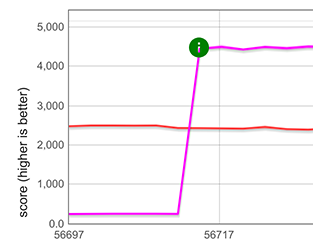
Pour la propagation des chaînes ([...string]), nous avons mesuré une amélioration d'environ 5 fois, comme le montrent les lignes violettes et vertes dans le graphique ci-dessous. Notez que ceci est encore plus rapide qu'une boucle optimisée par TurboFan (for-of-loop, TurboFan comprend l'itération sur des chaînes et peut générer un code optimisé pour cela), représentée par les lignes bleues et roses. La raison pour laquelle il y a deux tracés dans chaque cas est que les micro-benchmarks fonctionnent sur deux représentations de chaînes différentes (chaînes à un octet et chaînes à deux octets).
Amélioration des performances de Array.from
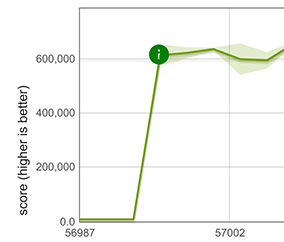
Heureusement, nos chemins rapides pour les éléments propagés peuvent être réutilisés pour Array.from dans le cas où Array.from est appelé avec un objet itérable et sans fonction de mappage, par exemple, Array.from([1, 2, 3]). Cette réutilisation est possible car dans ce cas, le comportement de Array.from est exactement le même que celui de la propagation. Cela entraîne une amélioration énorme des performances, comme montré ci-dessous pour un tableau contenant 100 doubles.
Conclusion
V8 v7.2 / Chrome 72 améliore considérablement les performances des éléments propagés lorsqu'ils apparaissent au début du littéral de tableau, par exemple [...x] ou [...x, 1, 2]. L'amélioration s'applique à la propagation des tableaux, des chaînes de caractères primitives, des ensembles, des clés de maps, des valeurs de maps, et — par extension — à Array.from(x).